Protein folding is a physical/biological phenomenon. AFAIK we don't currently have a proper exact mathematical formulation of the problem that would let one determine its complexity.
You may be referring to this paper [1]. It only claims that one particular optimization problem, believed to give a solution to protein folding problems, is NP-hard. So, even if a suitable exact formulation exists, it is not yet proven that protein folding is hard, although it for sure seems plausible.
By the way, it is perfectly possible today to solve some very large-scale NP-hard problems (think millions of variables and constraints) in reasonable amounts of time (think minutes or hours). Examples are knapsack problems, SAT problems [2], the Traveling Salesman Problem [3] or more generally Mixed Integer Programming [4].
[1] "Complexity of protein folding", 1993, by Aviezri S. Fraenkel
[2] http://www.satcompetition.org
> it is a problem for which the correctness of each solution can be verified quickly [0]
[0] https://cs.stackexchange.com/questions/128493/is-protein-fol...
Besides, this is real life - if predictions and real life match, that's great. If they don't, well you know you went wrong somewhere.
Joke, which I think is from Sean Eddy (hammer).
Bioinformatics approaches a Computer Scientist for help with a hard problem. CS agrees to help. Year later CS comes back very excitedly. "your problem is not hard it is NP-hard!". Bioinformatics nods, and says "I still got to solve it" and continues finding ever faster and better approximations ;)
Also problem space is both bounded (you don't have infinite length proteins) and f'd up in reality. e.g protein hijacking and re-conformation in the face of an infectious agent.
^ That sounds like word-salad BS but I think there's some truth to it. I know protein folding has been postulated to be useful in terms of understanding basic biology, understanding disease pathology, and drug prediction. While a wide range of approximations are functionally useless, perhaps the Alphafold approach or some improved version of it surpasses the functionally useful threshold.
At least I hope so
If AlphaFold is substantially more accurate at solving proteins, it can mean that drug discovery is faster, assays are faster, etc. etc.
The "unexpected problems" would be caught in the assay stage.
Proteins consist of chains of amino acids which spontaneously fold up to form a structure. Understanding how the amino acid chain determines the protein structure is highly challenging, and this is called the "protein folding problem".
People use mathematical models to predict how proteins fold in nature. Many such mathematical models are stated in terms such as "proteins fold into a configuration that minimizes a certain energy function". Even the simplest such models [1] give rise to NP-hard decision problems, which are also known (somewhat confusingly) as "protein folding problems". To make this a bit less confusing, I will call the mathematical decision problems PFPs.
Like all mathematical models, our protein folding models don't correspond exactly to reality. Even if you are somehow able to determine the exact mathematical solution to a mathematical PFP, that _still_ doesn't guarantee that the real protein that you were trying to model behaves like the mathematical solution would indicate. E.g. the protein may fold in such a way that it gets stuck in a local optimum of the energy function you were using.
How do we detect this? We make inferences about how the protein should behave, given the mathematical solution to the Protein Folding Problem, and then we perform experiments, and find out (empirically) that the protein behaves in a manner that is inconsistent with the inferences drawn from the mathematical model. Scientists _do_ do this. And they would have to do it even if they had a fast, exact way to solve NP-complete problems, because the NP-complete problems are still just part of a mathematical model, and need not correspond to reality in any way.
The success of AlphaFold is not measured by how well it solves (or approximates) mathematical PFPs. The success of AlphaFold is measured by making successful predictions about how certain proteins will fold. And this is exactly how it was tested [2]: they threw it at a bunch of problems for which scientists have empirically determined how certain amino acid chains fold, but didn't release the results. And then they compared the solutions predicted by AlphaFold, and found that most of the predictions were consistent with what they knew to be the case.*
[1] https://en.wikipedia.org/wiki/Lattice_protein
[2] https://predictioncenter.org/casp14/index.cgi
* That's an understatement. The solutions were really very good, much better than those produced by any other submission to CASP14.
For example, multi-complex proteins are not well predicted yet and these are really important in many biological processes and drug design:
https://occamstypewriter.org/scurry/2020/12/02/no-deepmind-h...
A disturbing thing is that the architecture is much less novel than I originally thought it would be, so this shows perhaps one of the major difficulties was having the resources to try different things on a massive set of multiple alignments. This is something an industrial lab like DeepMind excels at. Whereas universities tend to suck at anything that requires a directed effort of more than a handful of people.
A similar concern has sparked some worries about "AI overhang" https://www.lesswrong.com/posts/75dnjiD8kv2khe9eQ/measuring-...
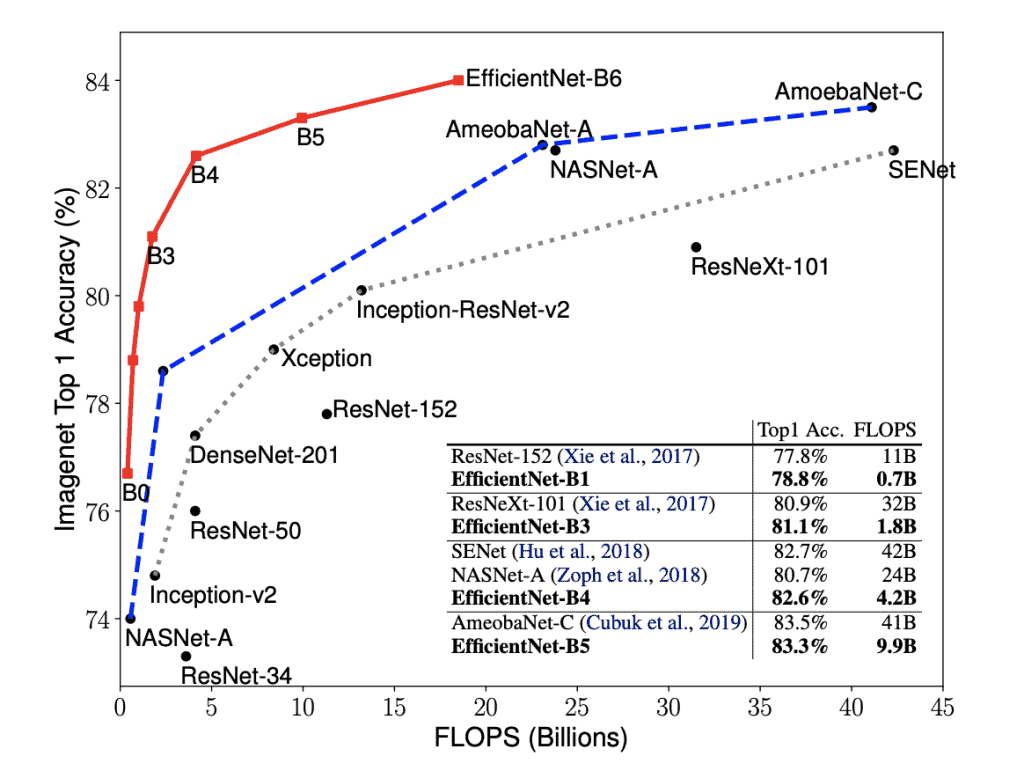
Most of the compute in ML research seems to be going into architecture search. Once the architecture is found, training and net finetuning/transfer learning is comparatively cheap, and then inference is cheaper still. This implies we could see 10-100x gains in AI algorithms using today's hardware, or sudden surprising appearance of AI dominance in an unexpected field. (Object grasping in unstructured environments? Art synthesis?) A task could go from totally impossible to trivial in a year. In retrospect, the EfficientNet scaling graph should have alarmed more people than it did: https://learnopencv.com/wp-content/uploads/2019/06/Efficient...
Waymo has been puttering along for years, not announcing much of interest. This may have caused some complacency about self-driving cars, which is a mistake. Algorithms only get better, while humans stay the same. Once Waymo can replace some human drivers some of the time, things will start changing very quickly.
But that happened 1y+ ago [1][2] without much changing since?
[1] https://www.theverge.com/2019/12/9/21000085/waymo-fully-driv...
[2] https://blog.waymo.com/2020/10/waymo-is-opening-its-fully-dr...
No it's not. Only Google spends significant time with automatic architecture search, and many people think this is really to try to sell cloud capacity.
> Once the architecture is found, training and net finetuning/transfer learning is comparatively cheap
Training isn't cheap for significant problems.
Getting the data is very expensive, and compute is a significant expense for large datasets.
> This implies we could see 10-100x gains in AI algorithms using today's hardware
Actually, most of the time we see 10-100% (percent! not times) gains from architecture improvements, whether they be manual or automatic.
But that is very significant, because a 10% improvement can suddenly make something useful that wasn't before.
Yeah, the HN commentary on Alphafold has a high heat-to-light ratio. I'm eager to read the paper because the previous description of the method sounded remarkably similar to methods that have been around for ages, plus a few twists.
The devil is going to be in the details on this one.
Sorry for the ignorance but what does this mean?
I even predicted DeepMind's CASP 14 network would be transformer-based back in 2018, but I couldn't have told you the details of that transformer, just that it was a no-brainer to move from fixed width convolutions to arbitrary width attention sums because sequence motifs and long-range interactions are of arbitrary width in the sequence.
All that seems to have changed with AlphaFold 2 because unlike GPT-XXX, this isn't a parlor trick with memorized text. This is actually useful and the FOSSing of the network will spawn all sorts of new applications of the approach.
So now I wonder what will replace Transformers because nothing lasts forever and there are a lot of smart people trying all sorts of new ideas.
Something along these lines was speculated to be to be used by Fabian Fuchs [0] soon after the original CASP competition. Basically, it's a huge win for the geometric deep learning people, and indicates an exciting direction for mainstream academia to move in.
I may be cynical about general expertise, as a support person, but large datasets have long been stock in trade of areas I'm more or less familiar with, whether "large" is TBs or PBs like CERN experiments. (When I were a lad, it was what you could push past the tape interface in a few days -- data big in cubic feet...)
Could you give an overview of how people can leverage this (or how you might?).
From reading around about it, it sounds like there's often a need to find a certain type of molecule to activate/inhibit another based on shape and the ability to programmatically solve for this makes the searching way easier.
Is this too oversimplified/wrong? How will this be used in practice.
[Edit]: Thanks for the answers!
It doesn't look like the models produced by this would immediately turn the challenging problem of finding, approving, and marketing successful pharmaceuticals (IE, it doesn't eliminate any real bottleneck).
There was a long-term dream of structure-based drug discovery based on docking, but IMO, it has never really proved itself (most of the examples of success are cherry picked from a much larger pile of massive failures).
I was thinking of going into that field. Can you expand a bit on why you left?
Holy grail, IMO, though is being able to design de novo protein sequences (to make "biologics", aka engineered protein drugs) that can a) target (bind/block/enhance) or do (chemical reactions) what you want and only that, b) are easily synthesizeable by bacteria/yeast (cheap to make), and c) are stable (easy to transport/store).
Short answer: nobody knows. Traditionally, protein folding is a solution in search of a problem, but that's largely because the predictions were...unusably bad. This was always more of a super-difficult validation problem for the force fields and simulation methods, which could then be used for other problems of greater value (such as rational protein design, or simulation of the motion of proteins with known structures).
These predictions are better, but still pretty far from the level of precision that you'd want for any kind of rational drug design, where the exact locations of protein side-chains (for example) matter a lot. You'll note that AlphaFold returns structures that are "relaxed" using one of the oldest simulation systems for proteins: AMBER. So it's not exactly a clean-room solution to the problem, and you can't assume that the details (which matter to drug design) are going to be any better than for the older methods.
But that said, if you have a method that can reliably give you a blurry view of the overall shape of a protein, even that could be useful for things like target discovery or inference of biological networks. But this is still a lot closer to pure research than "revolutionizing drug discovery", as is frequently batted around on reddit, HN and the press.
There are some examples of this issue in the AlphaFold blog, some protein loops that they thought were mispredicted but it turned out they were part of an energy degeneracy so the natural state fluctuated pretty wildly, so if you can't simulate this properly it matters less how accurate the incoming structure is (to a certain degree of course).
Being able to predict what it would look like would be a huge deal because then you can go about intelligently designing drugs for it.
Though I think the major impacts will be two-fold:
(1) The field of structural biology is going to see a change, with much more data available. Some structures of difficult to crystallize proteins will be solved, which may lead to much greater biological understanding. We may enter a time, where once you have a primary sequence, you also have a likely 3d-structure, which will probably change the daily work of quite a few biologists a bit.
(2) Industrial protein design. A tool such as this can potentially have great utility in optimizing proteins as chemical catalysts for various processes in different industries. This includes expanding the conditions under which a protein is active and also making their conformation more stable and so the protein more long-lived in solution.
That was a few billion dollars right there and almost all the work was done by hand by lab scientists.
1) is easy. 2) might not be - there can be a lot of things in a blood sample, and finding only the interesting (bad) things might not be simple. The sequencing part is pretty much solved. 3) would take a bit of work, but I think it's possible now. 4) we're getting there. 5) might have a fair amount in common with 3), but it probably takes some additional work. 6) is... probably non-trivial.
That's just one research agenda. There are others. You may have to move to related work, but I doubt you're going to be out of a job in this lifetime.
Basically sequence everything what's in your blood and look for what doesn't match your genome === infection. The problem is this is orders of magnitude more compute intense than whole genome sequencing. Basically increased demand for sequencing far outmatches available compute!
DNA sequencing is still slow and very expensive. On the scales you're talking about it's just not worth it.
I think I agree at a high-level that there is a huge reservoir of demand for this technology. But it's also possible that solving protein folding and similar research will simply cease to be a bottleneck for that demand, and people will be out of jobs.
These correlations do hold for technical fields, but logically there should be a point beyond which productivity gains outpace, demand growth / demand could even stop growing. One should either retool to solve a newer problem before this point is reached, or hope that the point is not reached in the span of their career.
Oil rig builders for example - manufacturing has been increasingly automated, but the demand for oil rig building has grown consistently. But they should probably look into solving other problems given that demand is shifting.
The underlying sequence datasets include PDB strucrures and sequences, and how those map to large collections of sequences with no known structure (no surprise). Each of those datasets represents decades of thousands of scientists work, along with programmers and admins who kept the databases running for decades with very little grant money (funding long-term databases is something NIH hated to do until recently).
> This was tested on Google Cloud with a machine using the nvidia-gpu-cloud-image with 12 vCPUs, 85 GB of RAM, a 100 GB boot disk, the databases on an additional 3 TB disk, and an A100 GPU.
This is amazingly detailed for a researcher who wants to follow in the track and also Apache licensed, which is one road-bump out of the way for a commercial enterprise, like an actual drug manufacturer who wants to burn some money trying this out.
edit: said the last part too fast, the code has a "the AlphaFold parameters are made available for non-commercial use only under the terms of the CC BY-NC 4.0 license"
It's quite unclear what value this will have to pharma; personally I doubt this has any direct applications (and I'm one of the few people in the world that can say that with deep authority).
Personally, I've found over decades that academic papers like that are far less useful to me than a github project and downloadable data that I can inspect, run and modify on my own. Other folks I know could read that paper and write the code in a day, I always wish I could do that.
> The simplest way to run AlphaFold is using the provided Docker script. This was tested on Google Cloud with a machine using the nvidia-gpu-cloud-image with 12 vCPUs, 85 GB of RAM, a 100 GB boot disk, the databases on an additional 3 TB disk, and an A100 GPU.
My experience working with code written by researchers is that it frequently contains a large number of bugs, which brings the whole project into question. I've also found that encouraging them to write tests greatly improves the situation. Additionally, when they get the hang of testing they often come to enjoy it, because it gives them a way to work on the code without running the entire pipeline (which is a very slow feedback loop). It also gives them confidence that a change hasn't lead to a subtle bug somewhere.
Again, I'm not criticising. I am aware that there are many ways to produce high quality software and Google/DeepMind have a good reputation for their standards around code review, testing etc. I am, however, interested to understand how the team that wrote this think about and ensure accuracy.
In general, I hope that testing and code review become a central part of the peer review process for this kind of work. Without it, I don't think we can trust results. We wouldn't accept mathematical proofs that contained errors, so why would we accept programs that are full of bugs?
edit: grammar
More info here and here:
https://www.bakerlab.org/index.php/2021/07/15/accurate-prote...
https://techcrunch.com/2021/07/15/researchers-match-deepmind...
I guess its a little less accurate but the quick compute time makes as much difference too. E.g. research students can have multiple less costly mistakes before achieving what they want with the software.
Does CC BY-NC actually do this? As far as I can tell it only really talks about sharing/reproducing, not using.
Or is the only thing prohibiting other commercial use the words "available for non-commercial use only"?
I suspect that the clause is there to prevent a startup launching on the basis of “see this trained model? Yeah, that’s literally our business model” though, which is a mildly amusing thought, wot wot.
So basically, a few tens of thousands, sure. A few million, big G might have a problem.
Still, the smart move would be to launch the business anyway, and gamble that you can work out a licensing deal.
Alternatively, you could manually change the network model, add a few hidden layers, etc... modifying the parameters in step, and result in a new model and new parameters. Some training to vary the parameters, and it's now a new work.
One of the things I say about CASP has to be updated. It used to be "2 years after Baker wins CASP, the other advanced teams have duplicated his methods and accuracy, and 4 years after, everything Baker did is now open source and trivially reproducible"
now, it's baker catching up to DeepMind and it took about a year
If you're a a medical startup, having an off-the-shelf prediction model you can just start using for all your protein folding needs is a very different proposition from having to train one yourself from scratch.
That said, hopefully other researchers and institutions will take Google's research and produce an equivalently powerful model but with a more commercially-friendly open-source license. From some comments in this thread, it sounds like that's already happening, in fact.
Source: former folding@home researcher.
For comparative and evolutionary analysis structure is far more conserved than sequence. Especially in things like viruses or anything with a high rate of reproduction like bacteria. Just knowing the general fold or overall structure is enough to do structural alignment and tell if two genes are related on that basis, even if their genomic sequence is completely dissimilar. Large groups of researchers rely on sequence homology built from sequences of known structure.
But AlphaFold works well in new sequence space to far more accuracy than is needed. If we had an AlphaFold prediction for every known sequence suddenly the evolutionary relationships between all genes and even all species would be far clearer. This on its own unlocks a new foundation to reason about function and molecular interaction with a wholistic systems view without gaps in what we can know with some reasonable assurance.
For an analogy think of the difference between having books in different languages describing objects. You know what some of the book in English might say but you dont even know if the book in Spanish is even talking about the same things. AlphaFold is like an AI that transforms all the books into picture books and now we can use image similarity or have one person look at all pictures.
I think you mean amino acid homology? (due to synonymous mutations)
I looked it up and you're right, protein structure/motifs are much more highly conserved than amino acid sequence https://humgenomics.biomedcentral.com/articles/10.1186/1479-...
On the other hand outbound network traffic from an university is "free". So the benefit is absolutely minimal from a hosting perspective.
It was tried (https://journals.plos.org/plosone/article?id=10.1371/journal...) but it is gone the way of the dodo for the above reasons.
https://www.nature.com/articles/s41586-021-03819-2_reference...
{kind=link}