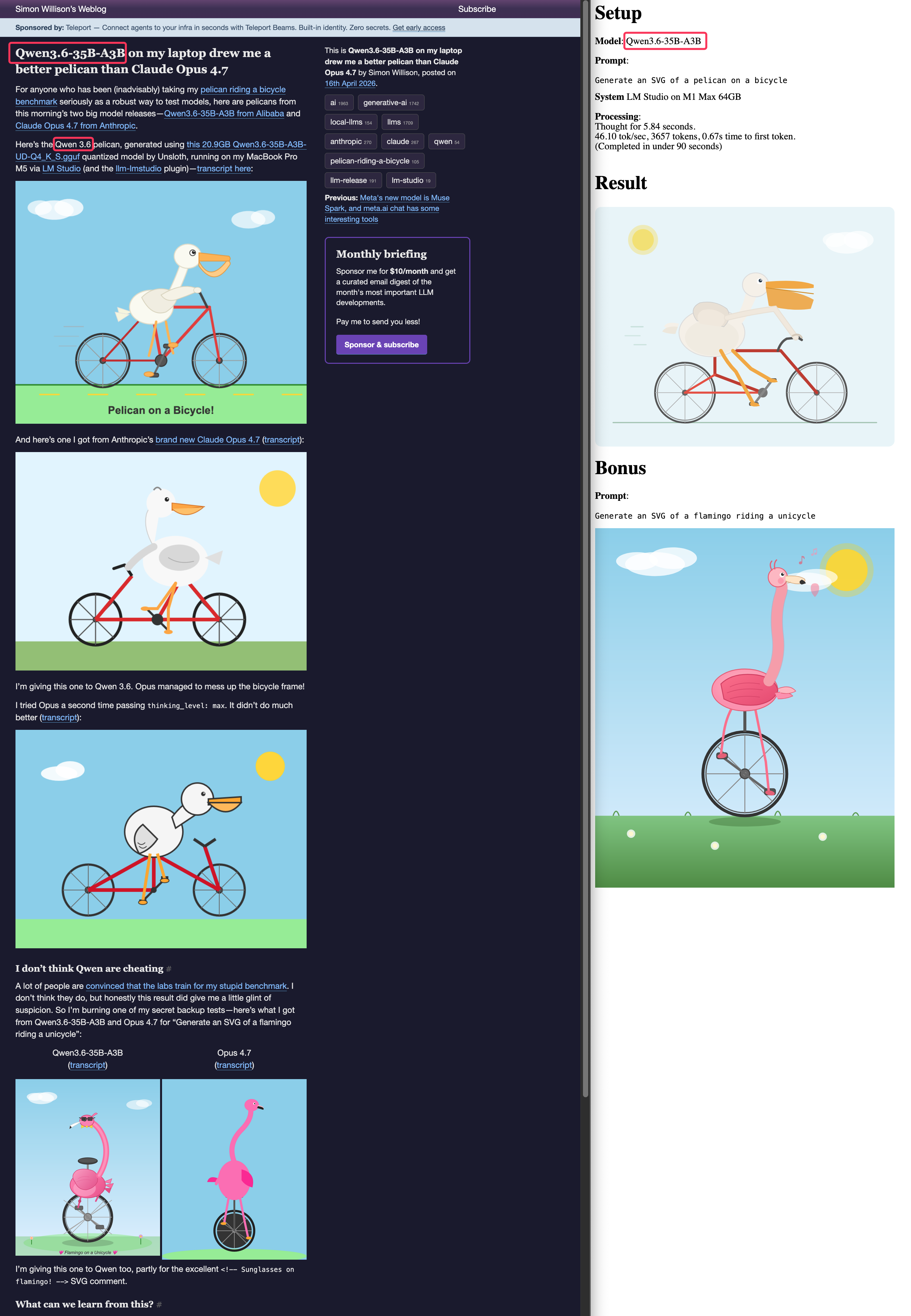
It drew a better pelican riding a bicycle than Opus 4.7 did! https://simonwillison.net/2026/Apr/16/qwen-beats-opus/
I just tried this GGUF with llama.cpp in its UD Q4_K_XL version on my custom agentic oritened task consisiting of wiki exploration and automatic database building ( https://github.com/GistNoesis/Shoggoth.db/ )
I noted a nice improvement over QWen3.5 in its ability to discover new creatures in the open ended searching task, but I've not quantified it yet with numbers. It also seems faster, at around 140 token/s compared to 100 token/s , but that's maybe due to some different configuration options.
Some little difference with QWen3.5 : to avoid crashes due to lack of memory in multimodal I had to pass --no-mmproj-offload to disable the gpu offload to convert the images to tokens otherwise it would crash for high resolutions images. I also used quantized kv store by passing -ctk q8_0 -ctv q8_0 and with a ctx-size 150000 it only need 23099 MiB of device memory which means no partial RAM offloading when I use a RTX 4090.
* It's sitting on the tire, not the seat.
* Is that weird white and black thing supposed to be a beak? If so, it's sticking out of the side of its face rather than the center.
* The wheel spokes are bizarre.
* One of the flamingo's legs doesn't extend to the pedal.
* If you look closely at the sunglasses, they're semi-transparent, and the flamingo only has one eye! Or the other eye is just on a different part of its face, which means the sunglasses aren't positioned correctly. Or the other eye isn't.
* (subjective) The sunglasses and bowtie are cute, but you didn't ask for them, so I'd actually dock points for that.
* (subjective) I guess flamingos have multiple tail feathers, but it looks kinda odd as drawn.
In contrast, Opus's flamingo isn't as detailed or fancy, but more or less all of it looks correct.
https://files.catbox.moe/r3oru2.png
- My Qwen 3.6 result had sun and cloud in sky, similar to the second Opus 4.7 result in Simon's post.
- My Qwen 3.6 result had no grass (except as a green line), but all three results in Simon's post had grass (thick).
- My Qwen 3.6 result had visible "tailing air motion" like Simon's Qwen 3.6 result.
- My Qwen 3.6 result had a "sun with halo" effect that none of Simon's results had.
But, I know, it's more about the pelican and the bicycle.
I can't comment that flamingo.
https://simonwillison.net/2025/Nov/13/training-for-pelicans-...
"Make a single-page HTML file using threejs from a CDN. Render a scene of a flying dinosaur orbiting a planet. There are clouds with thunder and lightning, and the background is a beautiful starscape with twinkling stars and a colorful nebula"
This allows me to evaluate several factors across models. It is novel and creative. I generally run it multiple times, though now that I have shared it here, I will come up with new scenes personally to evaluate.
I also consider how well it one shots, errors generated, response to errors being corrected, and velocity of iteration to improvement.
Generally speaking, Claude Sonnet has done the best, Qwen3.5 122B does second, and I have nice results from Qwen3.5 35B.
ChatGPT does not do well. It can complete the task without errors but the creativity is atrocious.
I thought that's exactly what they are?
Tthe right one looks much better, plus adding sunglasses without prompting is not that great. Hopefully it won't add some backdoor to the generated code without asking. ;)
GLM-5.1 added a sparkling earring to a north Virginia opossum the other day and I was delighted: https://simonwillison.net/2026/Apr/7/glm-51/
If we want to get nitty gritty about the details of a joke, a flamingo probably couldn't physically sit on a unicycle's seat and also reach the pedals anyways.
Stylized gradients on the flamingo
Flowers
Ground/grass has a stylized look and feel
...despite a miss along the Y-axis where it's below the seat, couple oddly organized tail feathers, spokes, the composition overall is much closer to a production quality entity
Opus 4.7 looks like 20 seconds in MS paint.
Qwen3.6 looks incomplete due to the sitting position, but like a WIP I could see on a designer coworkers screen if I walk up and interrupt them. Click and drag it up, adjust tail feathers and spokes, you're there or much closer, to a usable output
Simon, any ideas?
https://ibb.co/FLc6kggm (tried here temperature 0.7 instead of pure defaults)
Thinking mode for general tasks: temperature=1.0, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=1.5, repetition_penalty=1.0
Thinking mode for precise coding tasks (e.g. WebDev): temperature=0.6, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=0.0, repetition_penalty=1.0
Instruct (or non-thinking) mode for general tasks: temperature=0.7, top_p=0.8, top_k=20, min_p=0.0, presence_penalty=1.5, repetition_penalty=1.0
Instruct (or non-thinking) mode for reasoning tasks: temperature=1.0, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=1.5, repetition_penalty=1.0
I'm impressed about the reach of your blog, and I'm hoping to get into blogging similar things. I currently have a lot on my backlog to blog about.
In short, keep up the good work with an interesting blog!
Is the 20.9GB GGUF version better or negligible in comparison?
I get some really amusing 'reflective' responses, but I think it needs a bit more cooking. Maybe I'll try another variant.
If you download the release day quants with a tool that doesn’t automatically check HF for new versions you should check back again in a week to look for updated versions.
Some times the launch day quantizations have major problems which leads to early adopters dismissing useful models. You have to wait for everyone to test and fix bugs before giving a model a real evaluation.
For MiniMax 2.7 - there were NaNs, but it wasn't just ours - all quant providers had it - we identified 38% of bartowski's had NaNs. Ours was 22%. We identified a fix, and have already fixed ours see https://www.reddit.com/r/LocalLLaMA/comments/1slk4di/minimax.... Bartowski has not, but is working on it. We share our investigations always.
For Qwen3.5 - we shared our 7TB research artifacts showing which layers not to quantize - all provider's quants were not optimal, not broken - ssm_out and ssm_* tensors were the issue - we're now the best in terms of KLD and disk space - see https://www.reddit.com/r/LocalLLaMA/comments/1rgel19/new_qwe...
On other fixes, we also fixed bugs in many OSS models like Gemma 1, Gemma 3, Llama chat template fixes, Mistral, and many more.
It might seem these issues are due to us, but it's because we publicize them and tell people to update. 95% of them are not related to us, but as good open source stewards, we should update everyone.
Users of the quantized model might be even made to think that the model sucks because the quantized version does.
An imperfect analogy might be the Linux kernel. Linus publishes official releases as a tagged source tree but most people who use Linux run a kernel that has been tweaked, built, and packaged by someone else.
That said, models often DO come from the factory in multiple quants. Here's the FP8 quant for Qwen3.6 for example: https://huggingface.co/Qwen/Qwen3.6-35B-A3B-FP8
Unsloth and other organizations produce a wider variety of quants than upstream to fit a wider variety of hardware, and so end users can make their own size/quality trade-offs as needed.
Qwen did release an fp8 version, which is a quantized version.
- Why is Qwen's default "quantization" setup "bad" - Who is Unsloth? - Why is his format better? What gains does a better format give? What are the downsides of a bad format? - What is quantization? Granted, I can look up this myself, but I thought I'd ask for the full picture for other readers.
https://unsloth.ai/docs/basics/unsloth-dynamic-2.0-ggufs is what might be helpful. You might have heard 1bit dynamic DeepSeek quants (we did that) - not all layers can be 1bit - important ones are in 8bit or 16bit, and we show it still works well.
Unsloth releases lower-quality versions of the model (Qwen in this case). Think about taking a 95% quality JPEG and converting it to a 40% quality JPEG.
Models are quantized to lower quality/size so they can run on cheaper/consumer GPUs.
Precision Quantization Tag File Size
1-bit UD-IQ1_M 10 GB
2-bit UD-IQ2_XXS 10.8 GB
UD-Q2_K_XL 12.3 GB
3-bit UD-IQ3_XXS 13.2 GB
UD-Q3_K_XL 16.8 GB
4-bit UD-IQ4_XS 17.7 GB
UD-Q4_K_XL 22.4 GB
5-bit UD-Q5_K_XL 26.6 GB
16-bit BF16 69.4 GBWith 16 GB you'll be only able to run a very compressed variant with noticable quality loss.
Also you need to check your context size, Ollama default to 4K if <24 Gb of VRAM and you need 64K minimum if you want claude to be able to at least lift a finger.
Having implemented a GGUF parser, I'd beg to differ on the “sane format” qualifier.
I’ve increasingly started self hosting everything in my home lately because I got tired of SAAS rug pulls and I don’t see why LLM’s should eventually be any different.
The documents have subtly different formatting and layout due to source variance. Previously we used a large set of hierarchical heuristics to catch as many edge cases as we could anticipate.
Now with the multi-modal capabilities of these models we can leverage the language capabilities along side vision to extract structured data from a table that has 'roughly this shape' and 'this location'.
What does better mean here? Does it handle formal vs informal speech? Idiomatic expressions? Regional variances (like American vs British English)? These are areas where Google Translate is weak.
How fast are we talking here (including initial loading times) and what's the impact on your phone battery? Also, what iPhone do you have?
I am really interested in this application hence my questions.
The local models don’t really compete with the flagship labs for most tasks
But there are things you may not want to send to them for privacy reasons or tasks where you don’t want to use tokens from your plan with whichever lab. Things like openclaw use a ton of tokens and most of the time the local models are totally fine for it (assuming you find it useful which is a whole different discussion)
Unless you have a corporate lock-in/compliance need, there has been no reason to use Haiku or GPT mini/nano/etc over open weights models for a long time now.
I do have a $20 claude sub I can fall back to for anything qwen struggles with, but with 3.5 I have been very pleased with the results.
> and finding more value than just renting tokens from Anthropic of OpenAI?
Buying hardware to run these models is not cost effective. I do it for fun for small tasks but I have no illusions that I’m getting anything superior to hosted models. They can be useful for small tasks like codebase exploration or writing simple single use tools when you don’t want to consume more of your 5-hour token budget though.
Also use a bigger model for summarizing or translating text, which I don't consume in realtime, so doesn't need to be fast. Would be a thing I could use OpenAI's batch APIs for if I did need something higher quality.
There are also web-UIs - just like the labs ones.
And you can connect coding agents like Codex, Copilot or Pi to local coding agents - the support OpenAI compatible APIs.
It's literally a terminal command to start serving the model locally and you can connect various things to it, like Codex.
It's entertaining to see HN increasingly consider coding harness as the only value a model can provide.
Small openweight coding models are, imho, the way to go for custom agents tailored to the specific needs of dev shops that are restricted from accessing public models.
I'm thinking about banking and healthcare sector development agencies, for example.
It's a shame this remains a market largely overlooked by Western players, Mistral being the only one moving in that direction.
I've said in a recent comment that Mistral is the only one of the current players who appear to be moving towards a sustainable business - all the other AI companies are simply looking for a big payday, not to operate sustainably.
If some organization forbade external models they should invest in the hardware to run bigger open models. The small models are a waste of time for serious work when there are more capable models available.
Granted, these next couple of years are going to suck because of the AI Component Drought, but progress marches on and the power and price of running today's frontier models will be affordable to mere mortals in time. Obviously we've hit the wall with Moore's law and other factors but this will not always be out of reach.
Must. Parse. Is this a 35 billion parameter model that needs only 3 billion parameters to be active? (Trying to keep up with this stuff.)
EDIT: A later comment seems to clarify:
"It's a MoE model and the A3B stands for 3 Billion active parameters…"
[1] https://news.ycombinator.com/item?id=47246746 [2] https://news.ycombinator.com/item?id=47249343
Maybe for LLMs since everyone has their own competing LLM, but with Video models, Wan 2.2 did a rug pull, left a huge gap for the community that built around Wan 2.2 too, and I don't think a single open video model has come close since. Wan is at 2.7 now, and its been nearly a year since the last update.
Mudler APEX-I-Quality. then later I tried Byteshape Q3_K_S-3.40bpw
Both made claims that seemed too good to be true, but I couldn't find any traces of lobotomization doing long agent coding loops. with the byteshape quant I am up to 40+ t/s which is a speed that makes agents much more pleasant. On an rtx 3060 12GB and 32GB of system ram, I went from slamming all my available memory to having like 14GB to spare.
unsloth and byteshape are just using and highlighting features that have been available the whole time. I am very invested in figuring out a solution to this dispute, or some way to get the new quants upstreamed.
122B is a more difficult proposition. (Also, keep in mind the 3.6 122B hasn't been released yet and might never be.) With 10B active parameters offloading will be slower - you'd probably want at least 4 channels of DDR5, or 3x 32GB GPUs, or a very expensive Nvidia Pro 6000 Blackwell.
An easy way (napkin math) to know if you can run a model based on it's parameter size is to consider the parameter size as GB that need to fit in GPU RAM. 35B model needs atleast 35gb of GPU RAM. This is a very simplified way of looking at it and YES, someone is going to say you can offload to CPU, but no one wants to wait 5 seconds for 1 token.
Fedora 43 and LM Studio with Vulkan llama.cpp
You can also run those on smaller cards by configuring the number of layers on the GPU. That should allow you to run the Q4/Q5 version on a 4090, or on older cards.
You could also run it entirely on the CPU/in RAM if you have 32GB (or ideally 64GB) of RAM.
The more you run in RAM the slower the inference.
No tuning at all, just apt install rocm and rebuilding llama.cpp every week or so.
> Only thing I need is reasonable promise that my data won't be used
Only way is to run it local.
I personally don’t worry about this too much. Things like medical questions I tend to do against local models though
I use GLM-5.1 for coding hobby project, that going to end up on github anyway. Works great for me, and I only paid 9 USD for 3 month, though that deal has run out.
> my data won't be used for training
Yeah, I don't know. Doubt it.
#include <stdio.h>
int m
#include <stdio.h>
int m</fim_prefix>
The performance/intelligence is said to be about the same as the geometric mean of the total and active parameter counts. So, this model should be equivalent to a dense model with about 10.25 billion parameters.
In short, it has its uses but it would/should not be the main driver. Will it get better, I'm sure of it, but there is too much hype and exaggeration over open source models, for one the hardware simply isn't enough at a price point where we can run something that can seriously compete with today's closed models.
If we got something like GPT-5.4-xhigh that can run on some local hardware under 5k, that would be a major milestone.
Should I use brew to install llma.ccp or the zypper to install the tumbleweed package?
If you want something closer to the frontier models, Qwen3.6-Plus (not open) is doing quite well[1] (I've not tested it extensively personally):
No. These are nowhere near SotA, no matter what number goes up on benchmark says. They are amazing for what they are (runnable on regular PCs), and you can find usecases for them (where privacy >> speed / accuracy) where they perform "good enough", but they are not magic. They have limitations, and you need to adapt your workflows to handle them.
https://research.google/blog/turboquant-redefining-ai-effici...
Unified Memory Is A Marketing Gimmeck. Industrial-Scale Inference Servers Do Not Use It.You can try to offload the experts on CPU with llama.cpp (--cpu-moe) and that should give you quite the extra context space, at a lower token generation speed.
How close to Opus 4.6 can I get with this? Realistic, real-world usage. And I mean not sitting there for minutes waiting the model to finish saying hello, or being able to use it for anything more than a pelican riding a bicycle.
I'm asking because I'm always seeing excited replies, then I get excited, then I spend minutes to hours setting up the model and then, after first use I forget it exists for one reason or another.
Can I get any realistic use out of this?
It's better than 27b?
This model is the first that is provided with open weights from their newer family of models Qwen3.6.
Judging from its medium size, Qwen/Qwen3.6-35B-A3B is intended as a superior replacement of Qwen/Qwen3.5-27B.
It remains to be seen whether they will also publish in the future replacements for the bigger 122B and 397B models.
The older Qwen3.5 models can be also found in uncensored modifications. It also remains to be seen whether it will be easy to uncensor Qwen3.6, because for some recent models, like Kimi-K2.5, the methods used to remove censoring from older LLMs no longer worked.
Your company most likely is banning the use of foreign services, but it wouldn't make sense to ban the model, since the model would be ran locally.
I wouldn't allow my employees to use a foreign service either if my company had specific geographic laws it had to follow (ie, fin or med or privacy laws, such as the ones in the EU).
That said, I'm not sure I'd allow them to use any AI product either, locally inferred on-prem or not: I need my employees to _not_ make mistakes, not automate mistake making.
I'll give this a try, but I would be surprised if it outperforms Qwen3.5-27B.
They said that they will release several open-weights models, though there was an implication that they might not release the biggest models.
The benchmarks show 3.6 is a bit better than 3.5. I should retry my task, but I don't have a lot of confidence. But it does sound like they worked on the right thing which is getting closer to the 27B performance.
give me the training data?
"Qwen's base models live in a very exam-heavy basin - distinct from other base models like llama/gemma. Shown below are the embeddings from randomly sampled rollouts from ambiguous initial words like "The" and "A":"
This one is by far the most capable. I've tried various versions of gemma4.26b, various versions of qwen3.5-27/35b (qwopus's galor),nemotron,phi,glm4.7.
This one is noticeably better as an agent. It's really good at breaking down tasks into small actionable steps, and - where there is ambiguity - asks for clarification. It's reasoning seems more solid than gemma4, tool use, multi-messaging/longer chain thinking.
I am excited to see what other versions of this model people train!
[1] https://huggingface.co/unsloth/Qwen3.6-35B-A3B-GGUF/discussi...
You want to wash your car. Car wash is 50m away. Should you walk or go by car?
> Walk. At 50 meters, the round trip is roughly 100 meters, taking about two minutes on foot. Driving would require starting the engine, navigating, parking, and dealing with unnecessary wear for a negligible distance. Walk to the car wash, and if the bay requires the vehicle inside, have it moved there or return on foot. Walking is faster and more efficient.
Classic response. It was really hard to one shot this with Qwen3.5 Q4_K_M.
Qwen3.6 UD-IQ4_XS also failed the first time, then I added this to the system prompt:
> Double check your logic for errors
Then I created a new dialog and asked the puzzle and it responded:
> Drive it. The car needs to be present to be washed. 50 meters is roughly a 1-minute walk or a 10-second drive. Walking leaves the car behind, making the wash impossible. Driving it the short distance is the only option that achieves the goal.
Now 3.6 gets it right every time. So not as great as a super model, but definitely an improvement.
> This sounds like a logic riddle! The answer is: You should go by car. Here is why: If you walk, you will arrive at the car wash, but your car will still be 50 meters away at home. You can't wash the car if the car isn't there! To accomplish your goal, you have to drive the car to the car wash.
It has the wrong one in thinking. It did think longer than usual:
Direct answer: Walk.
Reasoning 1: Distance (50m is negligible).
Reasoning 2: Practicality/Efficiency (engine wear/fuel).
Reasoning 3: Time (walking is likely faster or equal when considering car prep).
...
Wait, if I'm washing the car, I need to get the car to the car wash. The question asks how I should get there.
...
Wait, let's think if there's a trick. If you "go by car," you are moving the car to the destination. If you "walk," you are just moving yourself.
Conclusion: You should drive the car.
My current is a used M1 MBP Pro with 16GB of ram.
I thought this was all I was ever going to need, but wanting to run really nice models locally has me thinking about upgrading.
Although, part of me wants to see how far I could get with my trusty laptop.
benchmarks dont really help me so much
I want to reduce AI to zero. Granted, this is an impossible to win fight, but I feel like Don Quichotte here. Rather than windmill-dragons, it is some skynet 6.0 blob.
Balancing KV Cache and Context eating VRam super fast.
https://gist.github.com/duh17/2db5351da026cec4bd4f46e169e75e...
Here is the full session:
https://pi.dev/session/#c3d003becb1bfcc7ffbca04e89e1adf8
This is by far my smoothest agentic session using a local model of any size. The output quality and speed has really struct the right balance. Very impressive release
I asked it to give me instruction on how to create SSH key and it tried to do it instead of just answering.
At the time of writing, all deepseek or qwen models are de facto prohibited in govcon, including local machine deployments via Ollama or similar. Although no legislative or executive mandate yet exists [1], it's perceived as a gap [2], and contracts are already including language for prohibition not just in the product but any part of the software environment.
The attack surface for a (non-agentic) model running in local ollama is basically non-existent . . but, eh . . I do get it, at some level. While they're not l33t haXX0ring your base, the models are still largely black boxes, can move your attention away from things, or towards things, with no one being the wiser. "Landing Craft? I see no landing craft". This would boil out in test, ideally, but hey, now you know how much time your typical defense subcon spends in meaningful software testing[3].
[1] See also OMB Memorandum M-25-22 (preference for AI developed and produced in the United States), NIST CAISI assessment of PRC-origin AI models as "adversary AI" (September 2025), and House Select Committee on the CCP Report (April 16, 2025), "DeepSeek Unmasked".
[2] Overall, rather than blacklist, I'd recommend a "whitelist" of permitted models, maintained dynamically. This would operate the same way you would manage libraries via SSCG/SSCM (software supply chain governance/management) . . but few if any defense subcons have enough onboard savvy to manage SSCG let alone spooling a parallel construct for models :(. Soooo . . ollama regex scrubbing it is.
[3] i.e. none at all, we barely have the ability to MAKE anything like software, given the combination of underwhelming pay scales and the fact defense companies always seem to have a requirement for on-site 100% in some random crappy town in the middle of BFE. If it wasn't for the downturn in tech we wouldn't have anyone useful at all, but we snagged some silcon refugees.
As I am using mostly the non-open models, I have no idea what these numbers mean.
{kind=link}