My wife, for example, uses ChatGPT on a daily basis, but has found no reason to try anything else. There are no network effects for sure, but people have hundreds and thousands on conversation on these apps that can't be easily moved elsewhere. Understandable that it would be hard to get majority of these free users to pay for anything, and hence, advertising seems a good bet. You couldn't have thought of a more contextual way of plugging in a paid product.
I think OpenAI has better chance to winning on the consumer side than everyone else. Of course, would that much up against hundreds of billions of dollars in capex remains to be seen.
Seems optimistic when there is very little intrinsic stickness due to learning the UI or network effects. Perhaps a little bit chat history - but not 285 billions worth.
Also completely ignoring the fact that most devices things will start to come with the same features directly built into the device/app - and the largest market will be as a commodity backend api that the eventually users won't know or care if it's a google or openai model.
As I see it, they need to be doing stuff nobody else can ( in either price or performance ), otherwise it's hard to justify the valuation.
Cultural defaults seem unchangeable but then suddenly everyone knows, that's everyone knows, that OpenAI is passé.
OpenAI has a real chance to blow their lead, ending up in a hellish no-man's land by trying to please everyone: Not cool enough for normies, not safe enough for business, not radical enough for techies. Pick a lane or perish.
Not owning their own infrastructure, and being propped up by financial / valuation tricks are more red flags.
Being a first mover doesn't guarantee getting to the golden goose, remember MySpace.
I think you're underestimating how fickle consumers are, and how much their choices are based on fashion and emotion. A couple more of these, and OpenAI will find itself relegated to the kids' table with Grok and Perplexity. https://www.technologyreview.com/2025/08/15/1121900/gpt4o-gr...
For myself, I use LLMs daily and I would even say a lot on some days and I _did_ pay the 20€/mo subscription for ChatGPT, but with the latest model I cannot justify that anymore.
4o was amazingly good even if it had some parasocial issues with some people, it actually did what I expect an LLM to do. Now the quality of the 5.whatever has gone drastically down. It no longer searches web for things it doesn't know, but instead guesses.
Even worse is the tone it uses; "Let's look at this calmly" and other repeated sentences are just off putting and make the conversation feel like the LLM thinks I am about to kill myself constantly and that is not what I want from my LLM.
So I'm curious to understand: What are the discussions like that people go back to and would lose if they moved to another platform?
I watched my partner switch from OAI to DeepSeek during the last outage and she hasn't been back to OAI since. I am skeptical there is any actual stickyness when basically all of the chatbots do the same thing for the casual user.
[1] https://www.theregister.com/2025/10/15/openais_chatgpt_popul...
Except these aren't conversations in the traditional sense. Yes, there's the history of prompts and responses exchanged. But the threads don't build on each other - there's no cross-conversational memory, such as you'd have in a human relationship. Even within a conversation it's mostly stateless, sending the full context history each time as input.
So there's no real data or network effect moat - the moat is all in model quality (which is an extremely competitive race) and harness quality (same). I just don't think there's any real switching cost here.
Sure it's 'sticky' at least a little, but it's not a moat. A moat is a show stopper like they own you.
I’ve got a small-ish sample of friends who are regular people and use various AI chatbots because mobile phone providers now commonly bundle an AI subscription with their services. People seem to switch between Perplexity, Claude, and ChatGPT without any trouble. It does not look sticky at all to me and the half-a-percent difference in benchmarks we love to obsess about does not translate at all in increased user satisfaction.
But the trillion dollar question is, what is? Now that I think about it, I'd bet heavily on Google. They've got your email, your photos, your location history, yada yada. Once they're able to pull all that into AI and make a reasonably cohesive product out of it, it seems like that's what people would use by default. Plus they've got a browser, search page, and phone OS that all can lead you to their AI.
They could train custom LoRA layers to mimic your tone, encode special tokens that indicate your name and data and various facts about you and your contacts, to make output more accurate, consistent, and personalized. Lots of possibilities for increased stickiness.
Even enterprise-wise, gemini is pretty good at coding and if your company has all its docs on Google docs, that could become a pretty seamless integration. They can even build their agents to prefer GCP, or maybe make that the free tier but have other providers support be more expensive.
At some point, a reasonable business model might be "we replace your engineering team with AI plus a few Google engineers on retainer for when things get wonky," which could scale to pretty large. (Granted this sounds more like a msft power move.)
They already have all the infrastructure, all they need is a reasonable competitor to github. They really screwed up losing out to msft on that one!
People used to suggest this about MySpace.
Friendster, MySpace, Facebook
Netscape, ie, chrome
Icq, aim, MSN messenger, a million other chat apps
First mover advantage doesn't last long
Very high chance that the winner in five years is a company that does not yet exist
See how stupid it sounds?
In comparison, Claude's name is very bad, it just doesn't sound right and people might mishear me when I say it. I never say "Claude" when talking to other, especially non-technical people, and instead say "ChatGPT" even though I am using Claude exclusively.
Google has another problem - they advertise their models as separate products. There is Gemini and there is Nano Banana, also Nano Banana Pro. But they are all somehow under the same product which is still called Gemini. I understand the distinction but I am sure many non-technical people find it confusing.
> My wife, for example, uses ChatGPT on a daily basis, but has found no reason to try anything else.
Is she paying for it? Because as we have seen repeatedly in the past, paid products whither and die when Microsoft bundles a default replacement.
You need to provide a really good reason why this time its different.
Ads might change that. If we know anything, nobody beats Google with ad based monetization. OAI is absolutely correct to be scared.
I just asked it to build me a searchable indexed downloaded version of all my conversations. One shot, one html page, everything exported (json files).
I’m sure I could ask Claude to import it. I don’t see the moat.
I honestly can't see how OpenAI can possibly recoup the hundreds of billions poured into it at this point. I'd say AI assistants are no more sticky than browsers or search engines.
You might be tempted to say that Chrome or Google are sticky. But they're really not. A lot of people aren't old enough to remember the 90s when we had multiple search engines and people did switch. I know this goes against prevailing HN dogma but I'm sorry: Google is simply the best search engine. It doesn't have a magical hold on people. People aren't fooling themselves.
And Chrome? Before smartphones it was simply the better browser. Firefox used to have a much larger market share and Chrome ate their lunch. By being a better browser. Chrome was I think the first browser, or at least the first major browser, to do one process per tab. I still remember Firefox hanging my entire browser when something went wrong. I switched to Chrome in version 2 for that reason.
And now browsers are more sticky because of Chrome on Android and Safari on iOS. Safari really needs to be cross-platform, like seriously so. I know they briefly tried on Windows but they didn't really mean it.
Anyway, back to the point. I believe there's a certain amount of brand inertia but that's it. If Gemini dominates ChatGPT performance and UI/UX, people will switch so fast.
Google, Microsoft and Meta can survive the AI collapse. Apple is irrelevant (at least for now). OpenAI? Doomed IMHO.
That's ok, we use ChatGPT only for coding. We should be good, right? Umm, no. They already explicitly expressed the intention to take a percentage of your revenue if you shipped something with ChatGPT, so even the tech guys aren't safe.
"As intelligence moves into scientific research, drug discovery, energy systems, and financial modeling, new economic models will emerge. Licensing, IP-based agreements, and outcome-based pricing will share in the value created. That is how the internet evolved. Intelligence will follow the same path."
"Intelligence will follow the same path."
https://openai.com/index/a-business-that-scales-with-the-val...
So yes, OpenAI has the best chance to win on the consumer side than anyone else. But, that's not necessarily a good thing (and the OpenAI fanboys will hate me for pointing this out).
My "brain" in terms of projects, is local on my computer. I have a simple set of system rules that I need to copy.
I am not everyone, I understand that. What I try to say: don't overestimate the lock in effect of AI. I doubt there is one.
By the way this is a perfectly rational stance. If the supermarket next to me stopped stocking Coca Cola, I would just by Pepsi.
See power users such as devs with coding assistants that have model selection dropdowns allowing you to switch on a whim. There is zero loyalty or stickiness in the paying user crowd.
Take ozempic as an example. The word is already part of the culture, but the company is losing badly to lly. Novo nordisk is projecting revenue DECLINE while eli lilly is still growing massively. I am not even sure people know other glp1 drugs other than ozempic. I don't even remember lilly drugs name.
I think people should not underestimate the market. It's a dynamic game where engineering intuition might not be enough
Google hasn't yet pushed hard into dominating the chatGPT use case, but they could EASILY push out chatGPT if they tried. For example, if they instantly turned their search page to the gemini chat, they would instantly have dominated openAI use cases. I'm not saying they would do that, they will probably go for the 'everything app' approach slowly
I think the use cases of chatGPT and google are not differentiated enough to justify 2 winners
They're losing market share and the growth of active user plateaued. They captured all the normies who learned about llms on TV but these people will never spend a cent as you said.
They're not even on the top 10 most used llms on openrouter anymore: https://openrouter.ai/rankings
At the current pace anthropic will make more money than openai soon: https://epochai.substack.com/p/anthropic-could-surpass-opena...
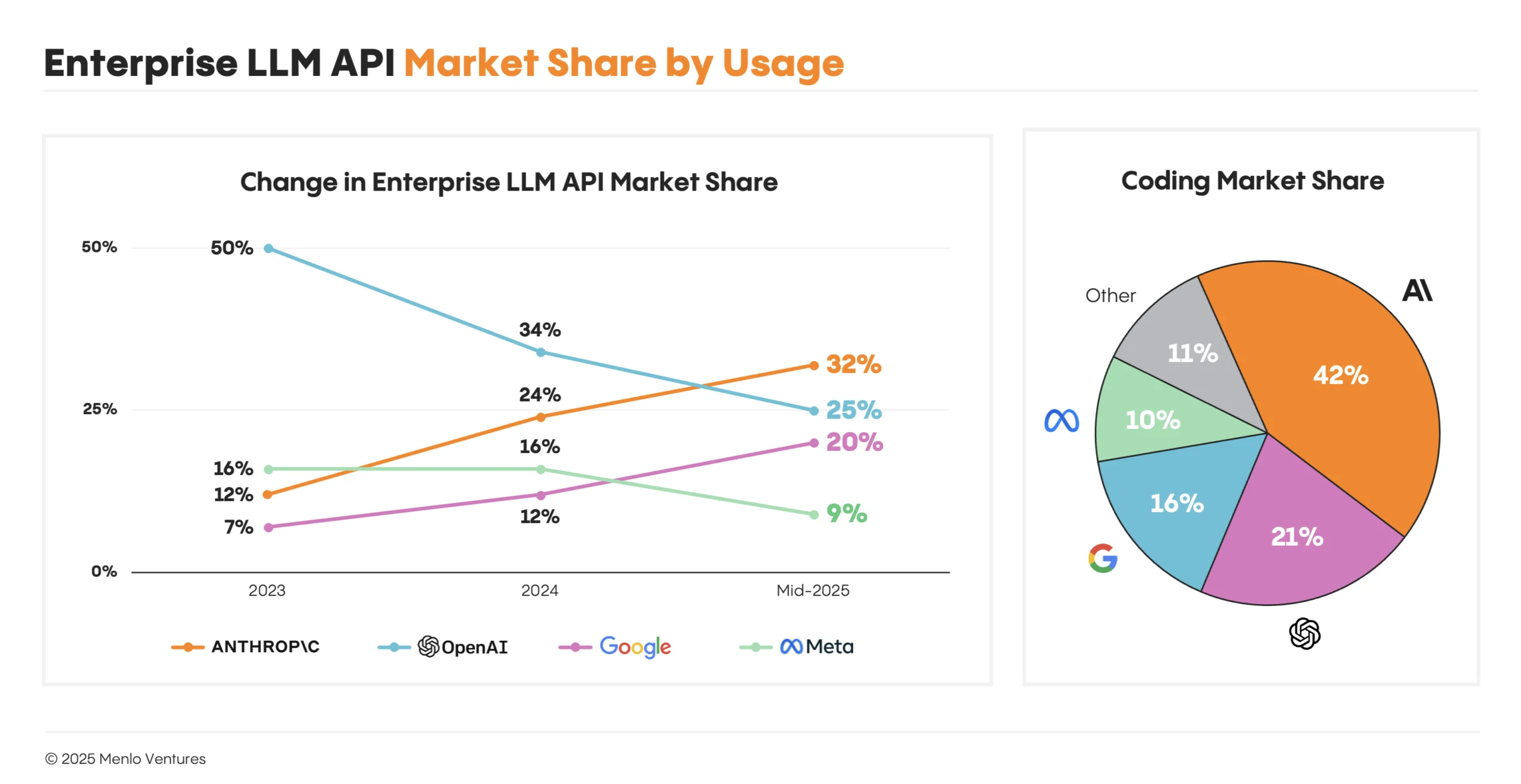
https://menlovc.com/wp-content/uploads/2025/07/2-llm_api_mar...
Neither can they be easily searched nor organized. And what prolonged AI use teaches you is: don't search for that old chat, just ask anew.
That particular piece of flypaper isn't as sticky as it may seem.
1. the current AI model is producing answers that do not met my needs so I try multiple others at the same time and the one that produces the best answer I stick with until I have this problem again.
2. there is a new model released and advertises a new capability that I want to try out.
I can imagine that for many people the answer that ChatGPT generates is adequate enough that they never need to try another model even if better answers exists from another model. For people with less complex needs this is a very real stickiness. Why make the effort to try something new if the answer is adequate.
In this case, OpenAI would only f*k up if they change the pricing significantly, add intrusive ads or their answers become significantly worse.
I might have sessions I revisit over a few weeks, but nothing longer than that. The conversations feel as ephemeral as the code produced. Some tiny fractions of it might persist long term, but most of it is already forgotten and replaced by lunch time.
They look like fortresses from the outside, but they are all incredibly vulnerable. That's the truth they don't want people to know or realize just how vulnerable they all are.
Anecdotally, the vast majority of my own conversations and coding interactions are transient in nature, to the point where I prefer to use the ‘temporary’ mode in whatever tool I’m using.
For coding, every project needs a plan and readme to get whatever agent back up to speed with what the task is. Anyone with a paid-for GH Copilot license knows that you can just switch between whatever provider at a whim, depending on the needs of your task or financial requirements.
I think people will find it easier to revert back to Siri 2.0 if that ever materialises, in which case the stickiness moat is bridged by a more familiar and widely integrated abstraction layer.
My anecdotes are that Google is winning even on consumer side.
So I suspect that Google will lean into Gemini, Microsoft will lean into OpenAI, and Apple ... it's a tough question what they do in the longer term.
For business users it's a different story and I see room for Anthropic to shine. And then there are the specialty AI services but those are all different markets from the general purpose AI.
OpenAI will likely keep their billion users, and likely monetise them fairly effectively with ads. Their revenue will be considerable. It’s less clear that OpenAI will “win” and their competitors won’t.
Competing in freeware products is impossible as soon as monopoly emerges. Competing in paid products is way easier, especially after free money age has ended.
Of course the first thing people may look at is technologies going head-to-head.
Another big one is user pricing, plus the underlying cost to serve users. Actually minus that cost.
Biggest so far is capital.
Seems to be going that way, a contest of capital could dominate like so many other things regardless of technologies.
There are probably other things that companies may leverage if competition does really ramp up.
It may not have to be a moat to be a defining characteristic that some prefer.
Most people I know with android phones, myself included, just use Gemini which is bundled with the OS and has a dedicated button, has excellent data and integration with maps and such.
When it comes to enterprise, non IT companies (banking, insurance, etc) in Europe seem to be defaulting to Google's offerings, Gemini and NotebookLM in particular.
Chat window is a chat window.
I can imagine that sooner or later things like OpenClaw (or its alikes) will become more popular and that could be something that will catch users.
And it's a spectrum, at one end you got the full-on AI psychosis and at the other "its a machine, I owe it nothing".
Conversational AI is going to be sticky to the extent that you see a switch to a different provider as dropping a relationship.
It would take me minutes to copy across a histories of projects and continue relatively unscathed by the experience.
I use chatGPT and currently relatively like it. But there is no moat beyond that.
Not like, for example, whatssap where it's almost impossible to detach from it due to the network ... (I've really tried with about a 10% success rate)
Which doesn't make money.
> Of course, would that much up against hundreds of billions of dollars in capex remains to be seen.
Most of that is a bet against enterprise adoption. Automation of customer service, sales, marketing, warehouses, medical discoveries, etc...
That's not the case. OpenAI is advancing on many fronts; codex, vectorStore, embeddings, response API, containers, batch processing, voice-to-speech, image generation... the list goes on.
OpenAI has by far the strongest brand and user base. It's not even close.
And, when it comes to the product they've been locked in the last few months it seems. The coding models are no longer behind Anthropic's and their general-use chat offering has always been up there at the top.
they can be super easily moved. just use the existing export feature, all a competitor needs is ability to import conversations.
But why would you want to?
You can just leave them there at slowly start new conversation on another platform.
Agentic development and claw style personal assistants are where the dough is at.
and thousands on conversation on these apps that can't be easily moved elsewhere.
myspace used to be a well known brand. I've worked there.
it's plenty good on free tier
as soon as they start adding restrictions / raising prices / etc won't take long to look for alternatives
Maybe you're overestimating their "moat" and stickiness. The dust is still settling on this madness and "OpenAI"[1] creates a lot of noise in the market.
These LLMs are being rapidly commoditized, very soon they will become as "boring" as virtual machines or containers. Altman has the exceptional skill to dupe people into giving their money to him. The "infinite money glitch" that he has been exploiting isn't really infinite.
I just hope there'll be a breakthrough with truly transparent LLMs that will stabilize this madness. As I've griped[2] two years ago, I find OpenAI too scummy, and it is unlikely that they will "win" with their sleazy ways.
[1] Air quotes because of their persistent abuse of the word "open"
The problem with a moat in the consumer space is it depends on brand and marketing. OpenAI came into this world as a tech novelty, then an amazing tech tool, then a household name.
But… can they compete with massive consumer companies like Apple, Google, etc? In the long run?
There’s no technical reason they can’t. The question is whether they have consumer marketing in their blood. The space doesn’t have a lot of network effects, so it’s not like early Facebook where you had to be on it because everyone was.
Not saying they’ll fail, just saying it would be a significant challenge to be a hybrid frontier model / consumer product company.
The tech landscape is littered with companies they had users who couldn’t monetize through ads. Beside the costs of serving request via LLMs is orders of magnitude greater than a search result.
On top of that, OpenAI is a sharecropper on other companies’ server, they depend on another company’s search engine and unlike Google, they are dependent on Nvidia.
Don’t forget that most browsing is done on the web and Google is the default search engine on almost every phone sold outside of China.
OpenAI has the stickiness of MSN news or MS Teams. Your wife uses chatgpt on a daily basis but is she paying for it? If they charge her $0.99/mo will she not look at alternatives? If she gets two or three bad responses from chatgpt in a row, will she not explore alternatives to see if there is something better? Does she not use google? If she does, she is already interacting with gemini everyday via their AI overview.
OpenAI has a first-to-market advantage, not a moat as you think. they can absolutley dominate the market, if they stay on top of their game. Ebay was the main online shopping network, they had that advantage, they were even the ones that made Paypal a thing! But they're relatively little used now, better alternatives crushed them.
Amazon was the first-to-market with cloud services, they didn't get worse in any significant way, but their market share is not as great as it used to be, Azure has gained decent ground on them. 10 years ago the market share break down was 31/7/4, now it is 28/21/14 for AWS/Azure/GCP respectively.
For OpenAI to survive it needs most of the market share, if it gets only a 3rd for example, the AI industry on its own needs to be a $1T+ industry. Over the past 10 years revenue alone (not profit) for AWS has been $620B total and just made $128B in revenue (highest) last year. OpenAI needs to make in profits (not revenue) what AWS made last year in revenue by 2029 just to break even. If it manages to just break even by then, it needs to have more profits than the revenue AWS managed to attain after its entire lifetime until now. It's far easier to switch LLM models than cloud providers too!
Their only remote way of survival, I hate to say it, is by going the way of palantir and doing dirty things for governments and militaries. they need a cash-cow client that can't get anyone else like that. And even then, being US-based, I don't think outside the US any military is insane enough to use OpenAI at all due to geopolitics. Even in sectors like education, Google (via chromebooks) is more likely to form dependence than Microsoft via OpenAI since somehow they're more open to arbitrary apps due to historical anti-trust suits.
I can see a somewhat far-fetched argument being made for their survival, but only on thin-threads and excellent execution. But I can't see how they can actually survive competition. They're using the Azure strategy for market share, they're banking on AI being so ubiquitous that existing vendor-lock-in mindset will serve as a moat. They'll need to be much more profitable than AWS in like 1/5th of the time. Their product is comparable to (and literally is in Azure) one of many cloud service offerings, as oppose to an entire cloud provider, and their costs are huge similar to cloud providers like needing their own data-centers level huge, they need to overcome those costs, and on top of that have $125B> revenue in like 2 years!!
ChapGPT has become the AI verb, and in the consumer space it is not getting dethroned.
My hunch is that in five years we'll look back and see current OpenAI as something like a 1970's VAX system. Once PCs could do most of what they could, nobody wanted a VAX anymore. I have a hard time imagining that all the big players today will survive that shift. (And if that particular shift doesn't materialize, it's so early in the game; some other equally disruptive thing will.)
To really have local LLMs become "good enough for 99% of use cases," we are essentially dependent on Google's blessing to provide APIs for our local models. I don't think they have any interest in doing so.
* even if an openweight model appears on huggingface today, exceeding SOTA, given my extensive experience with a wide variety of model sizes, I would find it highly surprising the "99% of use cases" could be expressed in <100B model.
* Meanwhile: I pulled claude to look into consumer GPU VRAM growth rates, median consumer VRAM went 1-2GB @ 2015 to ~8GB @ 2026, rougly doubles every 5 years; top-end isn't much better, just ahead 2 cycles.
* Putting aside current ram sourcing issues, it seems very unlikely even high-end prosumers will routinely have >100GB VRAM (=ability to run quantized SOTA 100b model) before ~2035-2040.
That still requires a pretty large chip, and those will be selling at an insane premium for at least a few more years before a real consumer product can try their hand at it.
I almost wonder if we need some sort of co-op for training and another for hosted inference
Datacenters simply scale better than homesevers on cost and performance
So only really works for people that value local highly - which isn’t most people.
Qwen 2.5 was already there. "99% of use cases" isn't a very high bar right now.
phi4-mini-reasoning took the same prompt and bailed out because (at least according to its trace) it interpreted it as meaning "can't have a, e, i, o, or u in the name".
Local is the only inference paradigm I'm interested in, but these things have a way to go.
Tell the average person that they have to install their own model is a deal breaker at the outset.
As for 99% capabilities being on device, battery life makes it a non starter.
1) the opportunities for vertical integration are huge. Anthropic originally said they didn’t want to build IDEs, then realized the pivot to Claude Code was available to them. Likewise when one of these companies can gobble up Legal, Medical, etc why would they let companies like Harvey capture the margins?
2) oss models are 6-12 months behind the frontier because of distillation. If labs close their models the gap will widen. Once vertical integration kicks off, the distillation cost becomes higher, and the benefit of opening up generic APIs becomes lower.
I can imagine worlds where things don’t turn out this way, but I think folks are generally underrating the possibilities here.
For code generation specifically, the performance level of this is going to be more than enough for this customer base. What does Anthropic do then to justify $200/mo price sticker? Better model? Just how much better? Better tools? Single company can't compete with the tools entire OSS can produce.
I would be unable to sleep if I was running OAI / Anthropic.
It’s ironic, if the promise of AGI were realized, all knowledge companies, including AI companies, become worthless
They're all scavengers, and we're the road kill.
Anthropic Claude has the best integrations with coding; what would make sense is for them to focus on that segment.
Other AI companies don't have anything really compelling. Meta has a model that's fully open-source, but then that's not particularly useful outside of helping them remain somewhat relevant, but not market-leading.
Sure Google can go against that, but it's openai is definitely in a much better spot. It's pretty important for a consumer market.
the problem with coding is the value is really in the harness and orchestration both of which are accessible to the opensource community. ClaudeCode isn't that big of a deal unless Anthropic makes it so that you can only access the models that ClaudeCode uses through ClaudeCode. If not, then projects like pi and opencode have the advantage in the long run. Also, these harnesses being node modules (of all things) make them very easy to reverse engineer with the help of... claudecode ironically.
Disagree, Codex is neck and neck with A/ on coding front
Works pretty good.
i'm just so surprised they'd use chatgpt to do this, when it's quite as easily (and perhaps faster) to use google translate.
(Aside, it's interesting how perceptions of these things have changed in one year: a whole article on OpenAI's future that makes no mention of AGI/ASI)
Many people say we’re at AGI already and I’m wondering why everyone hasn’t died yet.
Yes, just like the first person who will invent perpetual motion. /s
PS: to be clear, I'm not saying it's impossible but so far, just like perpetual motion or the Fountain of Youth it's an exciting idea anybody can easily understand yet nobody solved since it's been phrased out. It's not a solved problem and assuming it suddenly is is simply a (marketing) lie.
And so this goes back to my theory that open AI's execution is basically to get it itself in a position where the market cannot afford to have it implode. Basically, it wants to or it needs to be too big to fail. And I think we're already kind of seeing the politicization, if you will, sort of the rocket race between two superpowers or large powers on the AI front, and I think that Might be a viable strategy.
The only other way to reach too big too fail status is if allied countries risk collapse if it goes under ( like the big banks in the financial crisis ) which I don't see happening either.
The real danger here is how over-leveraged Open AI is. No other AI player is as exposed. Their massive spending commitments are all precariously balanced on the other end by their user base, and if that evaporates, the whole thing will fall apart and that could crash the stocks of other players ...and by crash, I mean bring them down to a realistic value. But the economy is counting on this to work, which is why I believe that Open AI's strategy here really is to make the market exposed to Open AI's risks.
At least some of us in HN talk about limiting the data we give to Facebook, Google, Microsoft, etc. Isn’t it just as important to limit what we share with non-privacy preserving AIs?
Note: tech friends have asked me how I can use slightly weaker AI models and be happy about it: I still use Gemini Plus (and Anthropic via AntiGravity) for technical work: everything I do as a software developer is open source and all of my writing (20+ books) is Open Content so I don’t care about privacy and being direct-marketed based on my tech work. To me it makes sense to use the best AI just for tech work and a private AI for everything else. Think about this if a family member has a serious health problem, or something else private: do you want to use open web searches and open AI chats, or do you want to use private web search and private AI access? Why not make privacy your default, except in special situations?
Duck.ai's Privacy Policy goes:
As noted above, we call model providers on your behalf so your personal information (for example, IP address) is not exposed to them. In addition, we have agreements in place with all model providers that further limit how they can use data from these anonymous requests, including not using Prompts and Outputs to develop or improve their models, as well as deleting all information received once it is no longer necessary to provide Outputs (at most within 30 days, with limited exceptions for safety and legal compliance).
Otoh, privatemode.ai, confer.to, trymaple.ai are at least attempting Apple AI-like confidentiality.
I'm not worried about the privacy aspect though many suggest that I should be. The power the dossier has given them to navigate the medical industry in the United States has been absolutely incredible. They don't have to be stuck when a random doctor who has never heard of their illness suggests that they might be overreacting. They can simply find someone who will help them. They can talk, in medical lingo, about their test results and discuss them with the doctor on equal footing.
I'm not sure this would've been nearly as successful without Opus 4.5/4.6 driving the harness. I'm not also not sure what real privacy risk there is here; it all sounds very theoretical.
Many pundits think it's just a matter of scraping the internet and having a few ML scientists run ablation experiments to tune hyperparameters. That hasn't been true for over a year. The current requirements are more org-scale, more payoff from scale, more moat. The main legitimate competitive threat is adversarial distillation.
Many pundits also think that consumers don't want to pay a premium for small differences on the margin. That is very wrong-headed. I pay $200/month to a frontier lab because, even though it's only a few % higher in benchmark scores, it is 5x more useful on the margin.
The WH has said it hasn't approved any sales, but it's not clear China is buying, and it seem they are making good progress on their huawei ascend chips. If China is basiclly at parity on the full stack (silicon, framework, training, model), and it starts open weighting frontier models at $0.xx/M tokens, then yeah, moat issues all around one would imagine? Not surprised to see Anthropic complaining like this: https://www.anthropic.com/news/detecting-and-preventing-dist... - but I don't know how you go back from it at this point?
I've never believed in Nvidia's moat, and it seems OpenAI's moat (research) has gone and surprisingly is no longer a priority for them.
They've already found a better route. Buy it elsewhere e.g. in Singapore. Train their models there using Nvidia hardware.
Ship the result and fine tune back in China.
So "China" is and has always been buying it. No difference. The politics can keep raging.
it seem they are making good progress on their huawei ascend chips
Anything changes in between?
[0]: https://www.reuters.com/world/china/deepseeks-launch-new-ai-...
From what I can see Anthropic's big bet is that they will solve computer use and be able to act as an autonomous agent. Not so sure how fast they will progress on that. OpenAI on the other hand - I have no idea what they are planning - all I'm reading is AI porn and ads.
Google seems to be lackluster at executing with Gemini but they are in the best position to win this whole thing - they have so much data (index of the web, youtube, maps) and so many ways to capitalize on the models - it's honestly shocking how bad they are at creating/monetizing AI products.
Anthropic is in favor with developers and generally tech people, while OpenAi / Gemini are more commonly used by regular folks. And Grok, well, you know…
We have yet to see who’s winning in the “creative space”, probably OpenAI.
As these positionings cristallize, each company is likely going to double down on their user’s communities, like Apple did when specifically targeting creative/artsy people, instead of cranking general models that aren’t significantly better at anything.
I think it has to be for the financials to work out. Whoever is not the winner and takes all goes bankrupt.
Claude: Programmers
ChatGPT: LGBTQ/Liberals, with a lot of censorship
Grok: Joe Rogan
Like, why do I STILL have to do taxes and accounting with external tools? Why doesn't OpenAI have their own tax filing service for the people?
OpenAI should just drop their API service and build everything themselves. It's exactly what they did with ChatGPT. Build thousands of things, not just a few.
Legal liability.
What is the network effect of Google Search?
Other factors that favor Google at scale:
- Sites often allow only the biggest search engine crawlers and block every other bot to prevent scraping. This has been going on for more than a decade and is especially true now with AI crawlers going around.
- Google search earns more per search than competitors due to their more mature ad network that they can hire lots of engineers to work on to improve ad revenues. They can also simply serve more relevant ads since their ad network is bigger.
- Google can simply share costs (e.g. index maintenance) among many more users.
Personally I only see Google (Gemini), X (Grok) and the Chinese models having a chances to still be alive in 1-2 years.
Big customers may buy but won't give them logos, people who are offended by Musk's worldview won't pay them either. You don't do well with a toxic brand: just look at Ye having to buy full page apologies ads to try and sell a record.
As margins collapse capex will collapse. Unfortunately valuations have become so tied to AI hype any reduction in capex will signal maybe the hype has gotten ahead of itself, meaning valuations have gotten ahead of themselves. So capex keeps escalating.
None of this takes into account the hoarding effects at play with regards to GPU acquisition. It's really a dangerous situation the industry is caught in.
Companies use to hoard talent. Now they are hoarding compute, RAM, and GPUs.
Deepseek showed that there are possibly less expensive ways to train, meaning the future eye watering expenses may not happen.
Bigger models may not scale. The future may be federations of smaller expert models. Chat GPTX doesn’t need to know everything about mental health, it just needs to recognize the the Sigmund von Shrink mental health model needs to answer some of my questions.
Today you have a phone in your pocket and you have apps on your home screen. Facebook is on your home screen, Whatsapp or X or Bluesky or whatever have a place on your home screen. Google basically is the safari app on iPhone. I don't know how many people have ChatGPT on their home screen. And soon, there will be some AI in your home screen from Apple (served by Google or another big hitter)that will be an incredible advantage.
That means OpenAI either needs to build up history with users very quickly and use that as stickiness before Apple nukes that distribution. Or they need to find a way of being another device that every living person has in their pocket.
Every attempt at doing that so far has been a comical failure and the way OpenAI are behaving makes me think their attempt will be no different.
I would love to dunk on this or something, but the lesson is that it's all about distribution.
Sama is really good at that, and also.. gotta give props for a lot of forward thinking like the orb, which now makes a lot of sense to me, as non-Apple/Google proof of personhood.
For me, the choice is ChatGPT, not for its Codex or other fancy tooling - just the chat. Not that Claude Code or Cowork is less important. Not that I like Codex over Claude Code.
I would argue chatgpt is in the top 10 products of all time with regard to product market fit.
This matters a lot to me, as I use AI as something of an ongoing project organizer, and not purely for specific prompts.
So at least for me, it would be a huge hassle to move to another platform, on par with moving from one note-taking software to another (e.g., Evernote to IA Writer.)
For the humanity perspective, this doom is very optimistic. It says that these LLMs currently disrupting the platforms cannot themselves be the next platforms.
Maybe no one will have 'the ability to make people do something that they don't want to do' sort of power with this next stage in computing.
Sounds good to me.
None of these can't be moved away from immediately. Even with my github repos, I use Antigravity, Claude Code, Opencode, and I might try Codex. I use one of them as a primary more than the other, but they're as close to interchangeable as possible.
I think this is clearly wrong. Users provide lots of data useful for making the models better and that is already being leveraged today. It seems like network effects are likely in the future too. And they have several ways to get stickiness including memory.
I see the point Ben is making even though there are a lot of nerdier innovations he’s skipping over — credential management, APIs (.closest!), evergreen deployments, plugin ecosystems, privacy guards, etc.
One aspect that model execution and web browsers share is resource usage. A Raspberry Pi, for example, makes for a really great little desktop right up until you need to browse a heavy website. In model space there are a lot of really exciting new labs working on using milliwatts to do inference in the field, for the next generation of signal processing. Local execution of large models gets better every day.
The future is in efficiency.
They'll have their guard down more often than the claudinistas and geminites, and be cheaper to somehow exploit.
I also think that more half-serious business ideas have been initially implemented against OpenAI services, i.e. most likely to fail due to a lack of proficiency in how to make an organisation work even if the core idea is sound and worthwhile pursuing.
I hear this, but every time I look the platforms have captured another use case that the startup ecosystem built (eg images, knowledge summarization, coding, music).
The sector is already littered with the corpses of the innovators that got swallowed by the platforms’ aggressiveness to do it all.
They're already doing it, but wonder how far they'll take it.
Demo: https://chatjimmy.ai/
Google “How to send a get request using Java”.
>import java.net.URI; import java.net.http.HttpClient; import java.net.http.HttpRequest; import java.net.http.HttpResponse;
public class GetRequestExample { public static void main(String[] args) { // Define the URL String url = "https://api.example.com/data";
// 1. Create an HttpClient instance
HttpClient client = HttpClient.newHttpClient();
// 2. Create an HttpRequest object for a GET request
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.GET() // Default method, but good to be explicit
.build();
try {
// 3. Send the request and receive the response synchronously
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
// 4. Process the response
System.out.println("Status code: " + response.statusCode());
System.out.println("Response body: " + response.body());
} catch (Exception e) {
e.printStackTrace();
}
}Vs Chat GPT
> import java.net.URI; import java.net.http.HttpClient; import java.net.http.HttpRequest; import java.net.http.HttpResponse;
public class GetRequestExample {
public static void main(String[] args) throws Exception {
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.example.com/data"))
.GET()
.build();
HttpResponse<String> response = client.send(
request,
HttpResponse.BodyHandlers.ofString()
);
System.out.println("Status: " + response.statusCode());
System.out.println("Body: " + response.body());
}Chat GPT is a bit clearer, but both are good.
It’s really Google’s race to lose, but we are talking about Google here. They’re very hit or miss outside of Search
I really dislike this narrative where it's always China = bad, and US companies = good.
These labs all copy from each other. OpenAI and Anthropic have "distilled" each other models too and routinely poach key researchers from competitors. Not only that, there's evidence Sonnet 4.6 has heavily distilled Deepseek R1 too, in fact, if you ask Sonnet 4.6 in Chinese who it is, it will tell you it's a Deepseek model.
Chinese are the only ones publishing papers on their models non stop.
The whole AI race is entirely based on blatant copyright infringements and copying each other.
First off, nonetheless open publishing stuff. Everything would have been trade secrets.
Next off no interoperable json apis instead binary APIs that are hard to integrate with and therefore sticky. Once you spent 3 or 4 months getting your MCP server setup, no way would you ever try to change to a different vendor!
The number of investors was much smaller so odds are you wouldn't have seen these crazy high salaries and you wouldn't have people running off to different companies left and right. (I know, .com boom, but the .com boom never saw 500k cash salaries...)
Imagine if Google hadn't published any papers about transformers or the attention paper had been an internal memo or heck just word2vec was only an internal library.
It has all been a net good for technological progress but not that good for the companies involved.
Give me an open source or non-American product that delivers the same quality, and I'll switch in an instant.
FWIW, this is how capitalism is supposed to work! Competition is driving AI forward at a fantastic pace!
OpenAI has the best model, that is how they are going to compete.
Their chatbot business could be in trouble, but Gemini needs a LOT of work to make it better to use too.
Coding wise, it has become very competitive. They need to sell better and sell aggressively
That being said...
> The one place where OpenAI does have a clear lead today is in the user base: it has 8-900m users. The trouble is, there’re only ‘weekly active’ users: the vast majority even of people who already know what this is and know how to use it have not made it a daily habit. Only 5% of ChatGPT users are paying, and even US teens are much more likely to use this a few times a week or less than they are to use it multiple time a day.
This really props up the whole argument, because the author goes on to say that OpenAI's users are not really engaged. But is "only" 5% of users paying of a 8-900M user base really so inconsequential? What percentage of Meta's users are paying? Google's? I would be curious to see the author dig deeper here, because I am skeptical that this is really as bad as the author suggests.
Moving on to another section:
> If the next step is those new experiences, who does that, and why would it be OpenAI? The entire tech industry is trying to invent the second step of generative AI experiences - how can you plan for it to be you? How do you compete with this chart - with every entrepreneur in Silicon Valley?
Er, are any of these startups training foundation models? No? Then maybe that is how you compete? I suppose the author would say that the foundation model isn't doing much for OpenAI's engagement metrics (and therefore revenue), but I am not sure I agree there.
Still, really good article. I think it really crystalizes the anti-OpenAI argument and it gives me a lot of interesting things to think about.
There is no way that number is an accurate reflection of the number of actual human users of their service. I could believe they have 8-900m bot/fraud accounts in their databases, maybe, but not real users.
{kind=link}