Ages and ages ago I was an EE turned programmer and everyone was hyping JUnit at the time. I had a customer ask for it on a project so fine I'll learn it. I kept thinking it was stupid because in my mind it barely did anything. But then I got it: it did barely do anything, but it did things you'd commonly need to do for testing and it did them in a somewhat standardized way that kept you from having to roll your own every time. Suddenly it didn't feel so stupid.
https://www.willowtreeapps.com/craft/is-anthropic-model-cont...
"Please don't post shallow dismissals, especially of other people's work. A good critical comment teaches us something."
"Don't be curmudgeonly."
MCP is barely worth being called a protocol; LLMs are now smart enough to follow instructions however you give them. When I played around with creating my own tool-using agent, I specified the tools in YAML, and asked it to use custom tags to 'call' them. It worked just fine.
More critically, there's nothing stopping the LLM from _not_ obeying whatever it is you give it, especially as the context fills up and/or the user trying to break it, except its own training. There is no proper HTTP server that would give you invalid responses 'just because'. Yeah, you could wrap the agent in a function that calls it again and again if the response isn't properly formatted with whatever formatting error happened, but I don't think any sane person would call that 'following the protocol', as the only entity it makes happy is whoever you're buying tokens from.
I see this agent stuff as a pretty basic agreement wrapped up in the vernacular of a protocol, i.e. "we'll put this stuff in the 'role' prop on our JSON", and then everyone else knows where to look for it. It's not especially important what we decide, as long as we create shared expectations.
I used to think protocols and RFCs and other products of standards bodies were the juicy 'big boy table' of tech, but then I realised: ok, it's not so complex–and perhaps doesn't itch my engineering itch–, but SOMEONE needs to take responsibility for deciding the protocol, otherwise it's just a bunch of randoms making up interfaces 1:1 with other parties and no useful tooling emerging for a long time. Best to beat it to the punch and just figure out a 'good enough' approach so we can all get on and make cool stuff.
Addendum: I will say, however, that the AI space has a particularly unhealthy attraction to naming, coining, forming myriad acronyms and otherwise confusing what should be a very simple thing by wrapping it up in a whitepaper and saying LOOK MA LOOK!
If you're interested in more technical approaches, I think they're starting to come together, slowly. I've seen several research directions (operads / cellular sheaves for a theory of multiagent collaboration, the theory of open games for compositional forwards/backwards strategy/planning in open environments) that would fit in quite nicely. And to some extent, the earliest frameworks are going to be naive implementations of these directions.
Mention John Holland’s work in adaptive systems, Hewitt’s actor model or even Minsky’s “Society of the Mind” and you’ll be met with blank stares.
I do believe LLMs have the potential to make these older ideas relevant again and potentially create something amazing, but sadly the ignorant hype makes it virtually impossible to have intelligent conversations about these possibilities.
https://hn.algolia.com/?dateRange=all&page=0&prefix=true&sor...
"Edit out swipes."
"Don't be curmudgeonly."
Hewitt's actors are arguably the earliest version of "agents" out there. But about one out of every 17,000 techbros running around claiming to be an AI expert today has even heard of actors. Much less Society of Mind, or any of the pioneering work on Agents that came out of the Stanford KSL[1] or UMBC (remember "AgentWeb"[2]?).
And don't even mention KQML, FIPA, DAML+OIL, or KIF, or AgentSpeak, or JADE...
[2]: https://web.archive.org/web/20051125003655/http://agents.umb...
They went for LLM + short-term and long-term memory + planning + tool using + action execution.
Presumably "planning" here is covered by any LLM that can do "think step by step" reasonably well?
It wasn't clear to me what the difference between "tool using" and "action execution" was.
I haven't seen a definition that specifically encompasses both short- and long-term memory before. They say:
> This dual memory system allows agents to maintain conversation continuity while building knowledge over time.
So presumably, this is the standard LLM chat conversation log plus a tool that can decide to stash extra information in a permanent store - similar to how ChatGPT's memory feature worked up until about four weeks ago.
mild disagree. 1) externalizing the plan and letting the user audit/edit the plan while its working is "tool use", yes, but a very specialcase kind of tool use that, for example, operator and deep research use Temporal for. ofc we also saw this with Devin/Manus and i kinda think they're better 2) there is a form of primitive tree search that people are doing where they can spam out several different paths and run it a few steps ahead to gain information about optimal planning. You will see this with morph's launch at AIE. 3) plan meta reflection and reuse - again a form of tool use, but the devin and allhands folks have worked on this a lot more than most.
my criticism of many agent definitions is that they generally do not take memory, planning, and auth seriously enough, and i think those 3 areas are my current bets for "alpha" in 2025.
> I haven't seen a definition that specifically encompasses both short- and long-term memory before.
here
- https://docs.mem0.ai/core-concepts/memory-types#short-term-m...
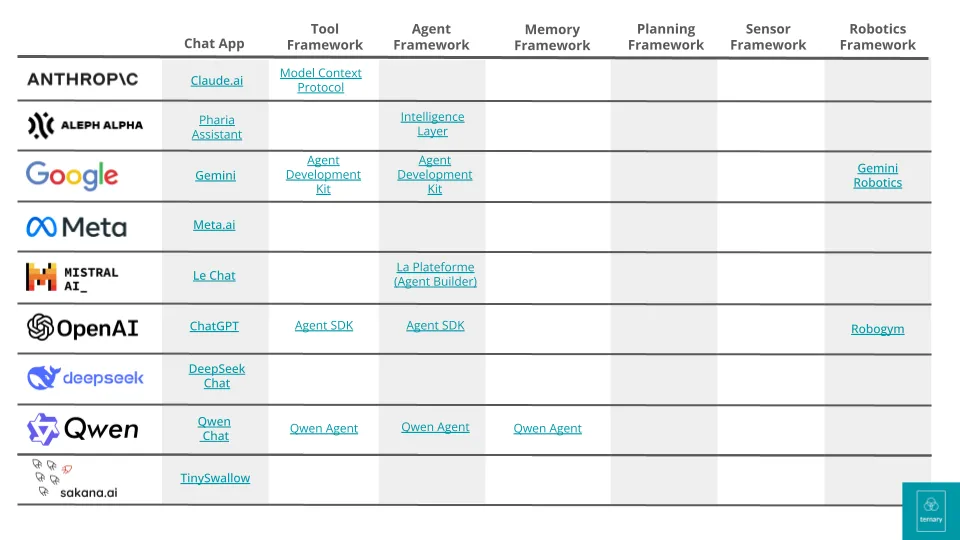
Image of a table outlining where the major frameworks are: https://substackcdn.com/image/fetch/w_1272,c_limit,f_webp,q_...
Here is also an article I wrote last year on the different types of memory: https://open.substack.com/pub/jdsemrau/p/memory-and-knowledg...
doing a lot of inference here, but could be a separation between -read- tool kinda actions, and -write/execute- (like running code/sending an email, etc)
a bit weird from a coding perspective but idk
What happened four weeks ago?
Prior to that change "memory" was a tool call: https://simonwillison.net/2024/Oct/15/chatgpt-horoscopes/#ho...
That said, the "Agent pattern du jour" is heavily based on using LLM's to provide the "brain" of the Agent and then Tool Calling to let it do things an LLM can't normally do. But still... depending on just what you do with those tool calls and any other code that sits in your Agent implementation then it certainly could be more than "just" an LLM wrapper.
Nothing stops you from, for example, using the BDI architecture, implementing multi-level memory that's analogous to the way human memory works, wiring in some inductive learning, and throwing in some case-based reasoning, and an ontology based reasoning engine.
Most people today aren't doing this, because they're mostly johnny-come-lately's that don't know anything about AI besides what they see on Twitter, Reddit, and LinkedIn; and wouldn't know BDI from BDSM.
[1]: https://en.wikipedia.org/wiki/Belief%E2%80%93desire%E2%80%93...
For me, the question of which protocols are used to communicate with the environment (MCP et al) ist just one and not even the most interesting question. Other questions uncover better, why agents are "a different kind of software" and why they might vastly change how we think of and use software:
- Stochastic not deterministic (evals/tests are crucial, creating reliable systems is much harder)
- conversational not forms (changes how we write software, and what we need to know for great UX)
- modalities, especially voice, change how we use computers (screens may become less important),
- batch with occasional real-time vs interactive might change how we feel that software works "for us"
- different unit economics (inference costs are significant compared to traditional run-time costs) change how software can be marketed
- data-driven capabilities on every level may change value chains and dictate how agents can work (if data is the moat, will agents need to "go to" the data owner and will be closely guarded of what they can extract/use?, much more than just traditional AAA)
- agents can be implemented in a way that they get better "themselves", because LLMs can be trained with data - will model providers capture most of the value of specialized vertical solutions? Is code less valuable than data/LLMs in the end?
- human-agent-relationship: By definition, agents act on someones behalf. This may again change how we interact with services/websites/content. Currently our personal systems are just like terminals. Will our interactions with services/websites etc. be mediated by "our" personal agents, or will we continue to use the different services, directly (and their agents, too)? Depending on that, the internet as we know it might change dramatically - services must deal more with agents than to humans, directly.
Bottom line: Agents are just an LLM wrapper, but they have the potential to dramatically change a lot of things around software. That's what's interesting about it, in my view.
see: https://github.com/luigiajah/mcp-stocks
The implementation: https://github.com/luigiajah/mcp-stocks/blob/main/main.py
Each MCP endpoint comes with a detailed comment - that comment will be part of the metadata published by the MCP server / extension. The LLM reads this instruction when the MCP extension is added by the end user, so it will know how to call it.
The main difference between REST an MCP is that MCP can maintain state for the current session (that's an option), while REST is supposed to be inherently stateless.
I think most of the other protocols are a variation of MCP.
"When disagreeing, please reply to the argument instead of calling names. 'That is idiotic; 1 + 1 is 2, not 3' can be shortened to '1 + 1 is 2, not 3."
https://news.ycombinator.com/newsguidelines.html
If you know more than others, that's great, but in that case please share some of what you know, so the rest of us can learn. Putdowns don't help.
https://hn.algolia.com/?dateRange=all&page=0&prefix=true&sor...
So it's debatable I think.
https://github.com/sgt101/FIPA-Mirror-/blob/main/Experience_...
During Web 2.0, we saw similar enthusiasm. Instead of AI agents or blockchain, every modern company had an API exposed. For instance, Gmail- and Facebook chat was usable with 3p client apps.
What killed this was not tech, but business. The product wasn’t say social media, it was ad delivery. And using APIs was considered a bypass of funnels that they want to control. Today, if you go to a consumer service website, you will generally be met with a login/app wall. Even companies that charge money directly (say 23&me ad an egregious example) are also data hoarders. Apple is probably a better example. There’s no escape.
The point is, protocols is the easy part. If the economics and incentives are the same as yesterday, we will see similar outcomes. Today, the consumer web is adversarial between provider ”platforms”, ad delivery, content creators, and the products themselves (ie the people who use them).
I mean, it’s not impossible that consumers will ignore sites and services that don’t play with their AI. But even so, the content providers would need to find alternative revenue streams – otherwise they’d be bleeding money.
My prediction is that tech companies will continue to compete for dominance over the entry points, apps and human interactions. It will be an adversarial space where coalitions of vertically integrated walled gardens can work. Basically how it is already.
{kind=link}