It would be great if languages could be "upgraded" to remove the hardest parts, both for native speakers and for foreigners willing to learn.
I remember reading that a famous poet/literate (can't remember who) tried to propose that for the Spanish language, decades ago.
Otherwise, it would be nice to have a universal language that everyone can learn and speak. Obviously, English is now occupying that spot, but I'd bet that English is certainly not the easiest, nor the most complete, language we could use.
Attempts such as Esperanto and others were never carried out with enough skills or resources. I'm wondering if it could be possible to do so today.
Coincidentally, I wrote a novel ~20 years ago, in which the protagonist is a language professor that invents a new universal language, called Galatico, and "open sources" it for the benefit of humanity. I even ventured as far as designing the basic concepts of this artificial language. It was really fun. Without knowing it, I used an alphabet system (base 64, in my case) similar to the one used in the Cistercian numerals [0]. I discovered this just two months ago, when visiting a Cistercian monastery in Italy, and then reading more about these monks.
Truly fascinating, for me.
That is a dubious claim. The truth of the matter is that there is no economic benefit in learning Esperanto over learning English as a second language, and (comparatively) very little cultural benefit. Learning English unlocks a vast world of literature, media, and communication in addition to the basic marketable skill its proficiency entails. Esperanto? Not so much.
The only way to force the use of Esperanto or any artificial language is to force children to learn it worldwide. That's something you might expect in North Korea (if they were so inclined), but most people would rightly dismiss it as a mostly pointless exercise.
It's a very westerner thing to say "your language is too complicated, you should simplify it for me"
https://en.wiktionary.org/wiki/%E7%94%9F#Japanese
It's telling that there is what's effectively a reading test for Japanese people, where it requires 12 years of schooling to take a stab at Level 2 (covering only the "daily use" kanji!), and Level 1 requires years of additional study on top of that:
I would guess they're talking about kanji though, which really isn't very complex. It's moreso just annoying to have glyphs that you can't pronounce if you don't already know an onyomi/kunyomi reading...
Take hiragana for instance, it consists of 46 characters (versus 26 for the latin alphabet). The latin alphabet is way more efficient than hiragana because we compose sounds instead of syllables: ta is t+a, whereas in hiragana あ doesn't appear in た. Then you add katakana and kanji, and it just becomes impossible to think of Japanese writing as not complicated.
Using a syllables-script for an ending grammar just doesn't make sense. Using 2 syllable scripts is just strange.
It most likely helped the leaders there to stay in control. Without native Japanese translators foreigners are unable to get very far.
When you learn English, Italian, Spanish and French you are not learning really 4 different languages as those languages overlap each other, they are from the same family(English is part of the germanic[anglo-saxon] but also the Latin family[normand]).
If you are native English speaker, you will learn French easily as most of english vocabulary(more than 60% of adjectives, and adverbs for example) comes from French.
As a native Spanish speaker, I understand most Italian and Portuguese with little effort, and French only problem is pronunciation, reading it is very easy.
For a Chinese native(Mandarin or Cantonese), learning written Japanese is easy, almost trivial.
I find Hiragana and Katakana easy to learn, not different from a vocabulary. It is kanji what is harder.
Absolute peak language for puns and dad jokes, too.
Even kana have exceptions where spelling and pronunciation are ambiguous. E.g. は/へ, which canonically represent [ha̠]/[he̞] but are also used for particles pronounced [ɰᵝa̠]/[e̞], which would usually be written わ/え. And こうし pronounced either [ko̞ːɕi] when it means 格子 (grid) or [ko̞ɯ̟ᵝɕi] when it means 子牛 (calf). Then there are aspects of the pronunciation like pitch accent and devoiced vowels that can't be expressed using kana at all...
I'm glad the Japanese writing system survived the first waves of digitization (at which point a vocal group of people worldwide was willing to sacrifice cultural artefacts and linguistic finesse for the sake of modernization) and in time put its own mark on things like character encoding and the technical capabilities of fonts on computers.
> Les caractères chinois, ou sinogrammes, sont les unités logographiques qui composent l'écriture des langues chinoises.
While technically a true statement, the usage of kanji in Korea and Vietnam is now fairly limited - Korea uses typically a system based on combining sounds together nowadays (while you still see them use Kanji for names or titles here and there) and Vietnam has moved to (an accent-rich) alphabet during the French colonization .
They mean that in the specific context of those languages. The set of hanzi is different than the set of kanji, which is different than the set of hanja, which is different than characters that Taiwan uses. They are -not- the same characters.
I see no real issue with using sinogram/sinograph over Chinese character since it refers to a Chinese character being used in another language. And it obviates the whole hanzi, kanji, hanja thing when not necessary.
The thing about hentaigana is that it's more or less an open set. I don't think there is the standard set of hentaigana that scholars agree upon. At a quick glance, juki-gana does not seem to be identical to Unicode's hentaigana set (https://www.unicode.org/charts/PDF/U1B000.pdf), although I'm sure the intersection is non-empty.
So all they need to do is use a font that implements it.
All hentaigana are available in Unicode 10. They can be found in the Unicode block 1B000–1B12F (Kana Supplement + Kana Extended-A).
For example, U+1B004 𛀄 HENTAIGANA LETTER A-3
It is completely brutal.
I reviewed this one 384 times already: https://www.benricho.org/kana/kana-img/f4f6.gif
The lapses are just crazy.
My second most reviewed, at 374 times, is https://www.benricho.org/kana/kana-img/f465.gif
Third, at 306 times, https://www.benricho.org/kana/kana-img/f4b7.gif
It's also serious because names are accepted as signature using hanko (official stamps) for official business and procedures.
By the way, there’s no requirement that your hanko matches your name and they only need to be registered for large purchases, like a house or for business use. They are however kept on record by your bank and sometimes compared digitally. By law foreigners can always use a signature instead of hanko but it’s not recommended as the comparison will often fail. On the other hand, online banking ans ATMs are good enough now that it’s been a good five years since I set foot in a bank.
I speculated that the nature of Japanese writing might be one reason. Written Japanese can sometimes be hard to understand when read aloud, as a lot of meaning is conveyed by the written characters themselves—most often by the kanji used, which frequently distinguish between different words with the same pronunciation, but also by the stylistic choice of whether to write a word in hiragana, katakana, or kanji.
Also, Manga is massively popular, and that form doesn't covert well (or at all) to audiobook.
Actually, I mentioned that possibility to the editor, too, as I have often read about Americans listening to audiobooks in the car. His response was that where he is from, in Saitama Prefecture, most people commute by car, too, but while they listen to the radio they don’t listen to audiobooks. That was his impression, anyhow.
You’re right about manga, of course.
Probably no more so than speakers of other languages.
What I meant is that written Japanese often conveys information that will be lost if the text is read aloud as it is written, as words written differently are often pronounced the same.
English has similar cases, such as “right,” “write,” and “rite.” But Japanese has many, many more. For example, the words 壮観, 送還, 相姦, 相関, 相観, 挿管, 創刊, and 総監 are all pronounced sōkan, but they mean, respectively, a grand sight, repatriation, incest, correlation, physiognomy, intubation, start of publication, and inspector general. When the words are seen, their meaning is immediately clear. When they are heard, the listener must infer which meaning is intended from the context, and often the context is insufficient.
Radio announcers, when reading aloud a text, will sometimes explain the kanji with which a word was written. Audiobook narrators probably don’t feel they have the authority to do so.
The language is full of homonyms, for instance.
Misunderstandings occur and then there is a back and forth along the pattern of "No, I don't mean the GENSHI (原子, atom) of GENBAKU (原爆, atom bomb). I mean GENSHI (原資, capital) as in SHIKIN (資金, funds). Okane no koto (having to do with money)." "Aaa... naruhodo".
They also often cannot read the names of people and places. It is simply not possible. If you don't know, the best you can do is form several plausible hypotheses, all of which could be incorrect due to some semi-arbitrary assignment.
Audible also seems to be doing ok in Japan now so it's probably way to early to attribute the relative popularity of audiobooks to any property of the language.
Not really. Japanese as a spoken language predates writing systems, and words like "koko" are yamatokotoba (original Japanese), not loans from other languages. It was first written in kanji (Chinese characters) because that was the only script they had initially, hiragana and katakana came later.
To confuse things even more, 此処 is valid Chinese as well, but the pronunciation is unrelated, they just mapped the meaning on top. This is also fairly common, to the point that there's a technical term for it (jukujikun).
I think your comment would make more sense if you removed the “not really“ in the beginning. You come off as saying “No, it was not written in kanji at first. It was initially written in kanji!” Which casts a weird, negative shadow on the otherwise interesting facts you add.
An even more subtle point is that kanji usage is fluid, so it's perfectly correct to write many words as kanji or kana, but with subtle shifts in meaning. For example, いい and 良い are both "good", but the latter is more formal and may even be read differently (yoi vs ii).
There's a lot more in common between the writing in Taiwan and Japan since Taiwan kept the "older" kanji while the CCP went thru the cultural revolution and the simplification of the number of strokes in each sign.
Still, there's a bunch of stuff that kind of looks like it would make sense when reading a Chinese word in Japanese, but turns out there's a lot of meanings are very different, either because the meaning evolved over time, or the Japanese simply imported kanji using their original sounds and not caring about their actual meaning.
As someone who knows nothing of the Japanese language beyond the very basics, I found these videos quite entertaining:
https://www.youtube.com/watch?v=-E6vHCT0wpw
https://www.youtube.com/watch?v=rzJqXd-1dEU
It looks like many characters are familiar to his respondents, but their combinations make absolutely no sense.
There’s a handful of kanji created in Japan (called) kokuji, mostly food related. Some of these made it back to China. And there are a few differences based on simple mistakes, for example a Chinese character mistakenly applied to the wrong species of fish.
No. In Chinese it's 此处 (simplified Chinese) or 此處 (traditional Chinese).
AFAIK, 処 is simplified Japanese. The original kanji is 處, which is the same as traditional Chinese.
In a Japan of today, you grow up with a plentitude of words taken from English and written + pronounced in Katakana. So you learn to pronounce "san-do-i-chi" for sandwich, "de-za-i-na" for "designer", "su-ma-ho" for smartphone, "ca-re-n-da" for calendar. And since you use and pronounce them wrongly on a daily basis you reinforce the Japanesified pronunciations. Then, actually pronouncing "calendar" in an English way becomes tricky.
So to me, the alphabets are a great example of a "historically grown" system, that's ripe for a "refactoring".
Korean has this same problem. Ice cream becomes ah-ee-suh kr-ee-muh, etc. I don't know very much Japanese but I believe it's even worse for Korean in this regard.
It, and words that include it, are not such common words. How/why did he choose that for the example, I wonder.
For that matter, how did I add it? It was due to some recursive chasing of words in a dictionary, where some word's older meaning was being explained as relating to some feudal situations in the Edo period, and that explanation used 藩 in it. Evidently, I have reviewed it 24 times. The fact that it contains 番 ("ban", number in a series, turn, ...) helps a lot.
I write down Korean word definitions in Korean, and this usually leads me to a whole bunch of niche words.
I'm very curious as to why Nintendo made this choice!
Is it because the game is designed to be welcoming to children? In which case, why not use furigana and use it as an opportunity to learn Kanji though repetition?
Is it supposed to reflect the simplicity of a back-to-nature lifestyle and the characters therein?
I'm inclined to suspect is the latter of the two; especially if kana is only employed in character speech while other parts of the game use Kanji.
Has anybody played the Japanese version? Can you speak to the use of Kanji in the game?
I'm inclined to suspect is the latter of the two; especially if kana is only employed in character speech while other parts of the game use Kanji.
This, but it’s the other way around. When characters speak to the player, who exists outside of the game world, it is in a mix of kanji and kana. When they write within the game world, it is in kana only.
> Hentaigana : beauties
>
> The word hentaigana is made of kana, — syllabic elements —, and hentai [...]
Here she (?) is referring to 変体 and not 変態. Earlier in the article she said "[j]apanese language is a very playful language" but I don't think she's thinking of homonyms. :-)
[1] https://atadistance.net/2019/10/20/japanese-text-layout-for-...
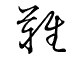{kind=link}
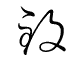{kind=link}
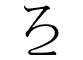{kind=link}