- Not designed to be difficult to extend
Everything else is basically irrelevant because as Clang has aged it's both slowed down and reached parity in both compile and execution speed. Phoronix even have GCC faster than Clang at building the Linux Kernel, even in an (according to a comment) biased sample where GCC wasn't built with lto enabled. GCC also (last time I tried) does better debug info.
LLVM is much easier to hack on, though, although some parts are more similar than you might expect.
https://www.phoronix.com/scan.php?page=news_item&px=GCC-Fast...
You should try and fettle with both to see what works best for your project.
A serious question: Is it correct to say that any compiler with state-of-the-art optimization cannot be fast, and clang's previous performance advantages were actually due to the lack of various optimization techniques and other features? And is there any investigation and research on the tradeoff of compiler speed/complexity vs. execution performance? Many minimalist purists claim that modern compilers are evil and it's possible to write a small and fast compiler. Yes, but at what cost? And is the cost too large to be justified, or is it that computers are acutally fast enough?
Sure, there are some language features that can make optimizations pathological complex, but for the most part if compilation speed isn't continuously tracked and strictly enforced against new changes, you inevitably regress into a slower compiler.
For instance, the Go community is highly sensitive to compilation speed. Although the Go compiler is SSA-based like LLVM, it's very selective about the optimizations applied. The Go compiler tracks and benchmarks each phase of the compiler release-to-release to identify major regressions.
Not lack of optimization techniques; LLVM is relatively fast compared to Clang for builds of the Linux kernel. Is it all of the compiler diagnostics and semantic analysis, or just unoptimized code? WIP to find out.
(I literally just went over a perf record of a linux kernel build with a teammate that's going to look into this more; I organized the LLVM miniconf at plumbers which is the video linked in the phoronix article in the grand parent post; my summer intern did the initial profiling work).
ToT LLVM, linux-next x86_64 defconfig: https://photos.app.goo.gl/hNwwy2K1Gh7Uc2D67 (yes, I know about disabling kptr_restrict)
Our next big project is to look into lazy parsing.
A quick example of this: https://gcc.godbolt.org/z/4r38xv
This isn't a particularly scientific test, but if you compare the assembly for the generated factorial function, the compilers being asked for absolutely breakneck speed correctly identify parallelism in the code, but fail to recognize that the loop overflows almost immediately - it is defined behaviour, so without human intervention it can't guess where we want performance. So the end result is a pretty enormous SIMD-galore function which is not much faster or even slower than the very simple optimize-for-size output.
You may be thinking, well it's faster sometimes, that's good - that is often a good thing, however, code density is very important. The SIMD-gone-mad version is several times bigger than the simple loop. Modern x86 CPU's have a roughly 1-4k μop cache, that might be a whole load of it gone right there. It's a significant dent in the instruction cache too.
If you look down the software stack, we use programs like compilers to invariants in our data and algorithms, act on it, and then promptly throw it away - when moore's law ends this is where we can find a lot of performance, I reckon. In this case we can bully the compiler into assuming the code overflowing won't happen, or highly unlikely, which lets it schedule the code more effectively for our use-case but this requires relatively intimate knowledge of a given compiler and the microarchitecture one is using - it's not really good enough.
I believe it is theoretically possible to write many of the optimizations that larger compilers have in fewer passes, but that comes at the cost of complexity and difficulty in debugging different combinations.
Do you have a reference for this statement?
same reason everyone choose anything open source.
Windows used BSD network stack because of license. Apple moved away from Bash because of license, etc.
Linux was the inexplicable exception that would allow us all to have true free software, but companies were quick to insert tainted mode so that cheap modem manufacturers dont' have to open source their lazy backdoors and google can ship android phones with not a single open sourced device driver.
Linux is practically the Bernie Sanders of open source.
I had access to Windows NT and ended up getting my first distribution via the Linux Unleashed book, because I needed something at home to save the trips to campus to work on our DG/UX timesharing environment.
If the POSIX subsystem was up to it, I wouldn't need to look elsewhere.
I don't see that this tells us anything negative about Clang. How is it a bad thing for the compiler to give you the option of a very slow build using additional optimisations? If you don't want that, then don't use that feature.
(I literally just looked at a perf record of a whole build of the linux kernel with Clang; and know more about the subject than...anyone).
ToT LLVM, linux-next x86_64 defconfig: https://photos.app.goo.gl/hNwwy2K1Gh7Uc2D67 (yes, I know about disabling kptr_restrict)
Our next big project is to look into lazy parsing.
GCC in this case gives you equal or as-near-as-makes-no-difference up or down performance in less compilation.
Some rigs are now posting 17s Kernel build times, reasons to be cheerful
I doubt any of the other compilers under comparison were designed to be difficult to extend. I think you instead mean “designed to be easy to extend.”
I'm sorry to say your doubt is mistaken. GCC is deliberately designed to be difficult to extend.
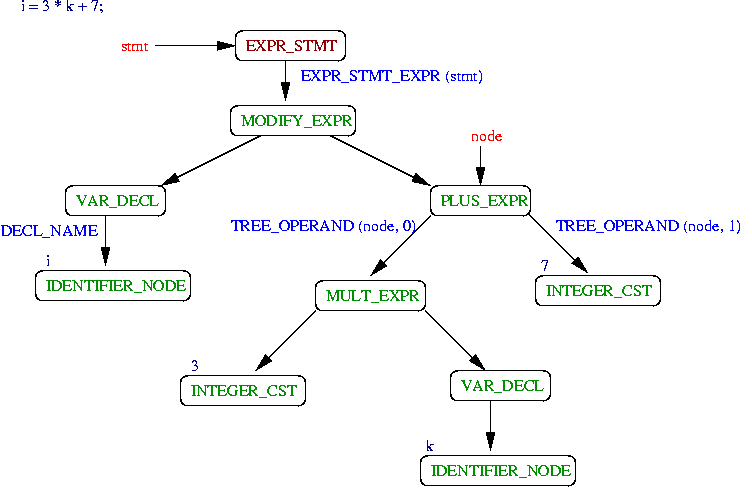
Can someone explain this Clang “pro”? If a refactoring tool wants to rename “x”, it does it to the source, not the AST, no? And if “x-x” is turned into 0 by the parser, why does it matter? Assuming “x” isn’t volatile, “x-x” is indeed 0!
If we have, for example,
struct a { int x; } sa;
struct b { float x; } sb;
sa.x - sa.x
sa.y - sa.y
A textual find and replace isn't sufficient because multiple variables might be named ‘x’ and you wouldn't want to rename all of them, just the one you're interested in. The only way to know which occurrences of ‘x’ are your ‘x’ is by parsing the source into an AST and then performing analysis on it. Once you know the file locations, then the source itself can be modified. So to summarize, yes you are correct that the source is modified, but an AST + analysis is needed to find the correct locations.
So, to avoid maintaining a separate parser, it would be nice to grab an AST from the compiler - but that AST has to match 1-1 with the source to be useful for refactoring.
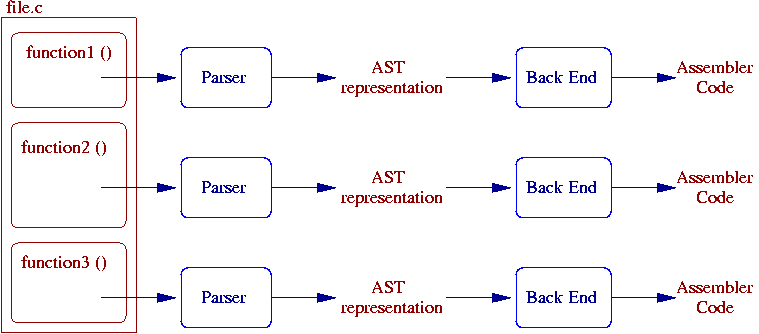
http://icps.u-strasbg.fr/~pop/images/front-end.png
It's a bit more work than cases where AST matches source level expectations, but can't you just walk that sub-tree and figure out that '0' was 'x - x'?
The "source"-level rewriting tool is going to build some kind of code and data structure that... parses and performs semantic analysis of the code.
Also, if x-x gets turned into zero by the parser just scrap the project and bring out the firing squad.
> GCC is built as a monolithic static compiler, which makes it extremely difficult to use as an API and integrate into other tools.
Obviously, if gcc exposed the AST with an API, changing "x - x" into 0 would be bad for refactoring, but they don’t (at least when this was written a decade ago).
"GCC is licensed under the GPL license. clang uses a BSD license, which allows it to be used by projects that do not themselves want to be GPL."
For example, Apple can keep their internal backends (GPU, some ARMv8 details) proprietary.
One example is ILP32 support for AArch64, which is apparently used in the Apple Watch. It looks like all of Apple's modern SoCs are 64 bit only, and in order to reclaim some memory on constrained devices, they're using ILP32 and a 32 bit address space, with 64 bit registers and such. https://lists.llvm.org/pipermail/llvm-dev/2019-January/12978...
This conveniently avoids most of the downsides of dynamic linking, except I don't think you get any of the upsides, either—which is to say I'm not sure what the point is. I kind of like it because, since I don't mind breaking code signatures, I can replace the frameworks in third party apps with updated copies. But I'm pretty sure that's not Apple's intended use!
- Okay, we need to think of some reasons besides "It's not GPLv3".
- In fact, let's list that one last so it looks like an afterthought that doesn't concern us so much.
- Hmm, no, too conspicuous. Make it next-to-last.
By the way you should be aware there is 100% no requirement for Apple to defend their choice for a compiler. They can choose whatever they want for any reason or no reason at all. If they don’t choose your favorite compiler it’s not some kind of evil conspiracy.
They made a choice and published a document describing their thought process and you can take it or leave it.
These things were true when Apple first went with Clang, and this document must date from that time.
GCC is now implemented in C++, and Clang’s C++ support is excellent. The only issue I have with my c++17 code in Clang is I can’t yet rely on recursive template parameter pack deduction.
Maybe in libstdc++, but what else would you use there.
I wanted to know what register allocation algorithms GCC implements, but I can't even find it. It's all files with cryptic names and hundreds in one directory. You can find _even less_ documentation, talks and blog posts about GCC internals :(
There's a directory [1] containing some "historical notes" written by the creators of llvm: Chris Lattner and Vikram Adve. One of them is the original clang readme [2].
[1]: https://opensource.apple.com/source/clang/clang-800.0.42.1/s...
[2]: https://opensource.apple.com/source/clang/clang-800.0.42.1/s...
{kind=link}
{kind=link}