I'm not even a member of Merveilles but that makes me sad for them.
[1] http://werxltd.com/wp/2010/05/13/javascript-implementation-o...
[2] http://stackoverflow.com/questions/6122571/simple-non-secure...
This hash doesn't scramble input very well, so you can fiddle with individual characters to converge on any desired hash value.
Record the "closest" hash value to your target generated by this loop, apply (only) that character change, repeat. If the hash value stops converging, add a character. This naive version pretty often does the job in 5 full iterations or so, which means (5 * len(s) * len(alphabet)) = maybe ~3000 total hashes to get a solution.
for i in xrange(len(s)):
copy = s
for c in alphabet:
copy[i] = c
diff = abs(hash(copy) - 666)
best = min(diff, best)on my 4-core MBP (2.6ghz ivy bridge) i can manage ~1.8 billion hashes per second.
i could parallelize with OpenCL, but i think this is enough. after a few minutes, i get ARbyhlf as a valid name (although i don't know if this is actually valid.. but it definitely might be)
(removed)
edit: just realised that my nonce calculation was wrong.. http://pastebin.com/bcHcECPJ
I actually did some micro-benchmarking in the midst of all that and found that hashing a single, static, string took something of the order of 20ns. That's half a billion hashes per second, or 2 billion on four cores. Add a little overhead for string generation, and yeah, we get the same number.
when i took out string generation, i went from 1.2 GH/s to 1.8GH/s (although, i'm assuming my string generation was much simpler)
> I very quickly realised looking through the entire possibility space in order would be unproductive
you say that, but it's not as unproductive as you might think. assuming the hash function is uniformly distributed (hah), there are 4 billion hash values that could result from a string. if we can check 2 billion a second, we should see a result every few seconds. maybe my search space pruning was particularly bad, because i see on average ~4-10 a minute, and they are usually quite clustered together. this suggests the hash is not uniformly distributed (although a cursory glance at the function should make it obvious to people with a maths background).
anyways, it was good fun to poke around :) cheers for sharing!
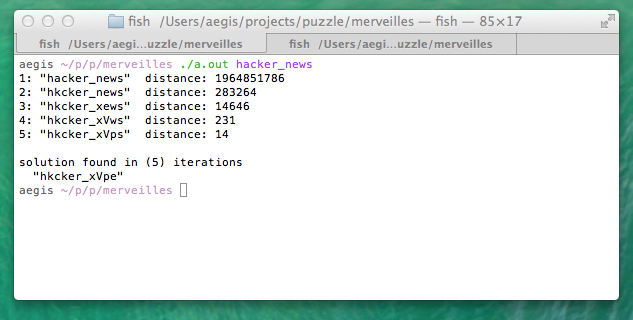
Example: http://bochs.info/img/mutation-20140606-024906.png
One could definitely optimize this to be less destructive and produce more pronounceable results. It's basically two pieces: an engine for suggesting mutations, and a simple algorithm to score and pick mutations. Changes to either half (vowel distribution, ngrams, etc) could result in better strings.
(fyi, this kind of attack is a big reason to use cryptographic hashes: http://en.wikipedia.org/wiki/Cryptographic_hash_function)
I got schooled, I'm learning, next time I'll be more clever about it, thank you!
I’m half tempted to buy a few hours of highcpu AWS compute power and get
it done nowish instead ... I set myself a $50 spending limit, which
gave me about 24 hours of compute on an instance with 32 virtual cores
You could get 178 hours of compute for your $50 budget.
Maybe there's an OpenCL use for finding extremely optimal usernames, though.
{kind=link}