As for the comment "Improving our documentation and website to accurately reflect our product". That is a very round about way of saying "our website indicates our service does things that it does not" which is a VERY bad thing. People are paying for this service based on what Heroku claims it does.
If the website has been inaccurate for years, that is false advertising and really a bigger problem than they are giving credit to.
If anything, I am more disappointed now that I have read this response, it has not appeased anything.
Just yesterday, I found a critical discrepancy between the ActionScript documentation and the actual behaviour of the ActionScript compiler, costing my team a day of work. (I tried to report the issue to Adobe, but the Adobe Bug Reporting System was down. Perhaps they need a Bug Reporting System for the Bug Reporting System.)
I think it's pretty heroic (yeah, pun) for Heroku to own their mistake, make the changes they've proposed, and accept the fire we've been pouring on them. They could have easily tried to weasel their way out of this, or attack the claims (Tesla/NYT comes to mind). Instead, they've accepted their own wrongdoing, and have pledged to make it right.
Who cares if the explanation comes today or tomorrow? Give them a few more hours to make sure their new round of technical claims are accurate, since such accuracy is exactly what's at issue.
As for discrepancy in documentation, this is one of the most major parts of their infrastructure and directly relates to how well applications scale. To claim they have intelligent routing and then not having so, that is completely misleading and not just a minor documentation discrepancy. This isn't a tech document that got out of date, this is straight from their main "how it works" page... http://www.heroku.com/how/scale. Read the bit on routing.
Not impressive at all.
I have friends in that community and while they're all volunteers I've seen first hand how hard they try and help people.
> It can't be that hard to give a basic overview of it before they release a more comprehensive post
Well, actually it is very hard to give a basic overview of anything complicated, without leaving your readership with their heads scratching. The person that wrote the blog post might not even understand the whole stack to be in the position of giving that overview and if he did, you'd probably be here bitching about factual errors.
> People are paying for this service based on what Heroku claims it does
Dude, this is a service used by developers and devops. You aren't meant to trust what they say. You are meant to measure and see for yourself if Heroku fulfils your needs or not. You know, how the author of the original blog post did it. And don't get me wrong, because I would agree with you, except for the fact that their website is not lying about what they provide. It's just out of date, sometimes describing details of the now deprecated Bamboo stack, a stack which also suffered through deprecation ... but hey, errors happen, we are human after all.
The response itself is an example for what other companies should do. They acknowledge sincerely that they have a problem, with a promise that they are going to fix it. How many other companies you've seen that do that? Amazon and Google sure as hell don't.
Also, the reason I chose Heroku is because DevOps is not my area of expertise, if I wanted to measure and analysis the inner workings I would have hosted elsewhere. Heroku is meant to alleviate that pain for me, I pay them excess over what I would pay elsewhere for that luxury.
As for the website not lying, yes it does. Go to "how it works" and click on routing. It's plain not true. Is it too much to ask that they update this in the last 3 years since the change?
I think the response is purely PR. Actually give something that will help their existing customers with this problem.
Developers, sure. Devops? Heroku's entire purpose is so you don't have to care about ops.
> You aren't meant to trust what they say.
Evidently not! I'd rather not do business with liars.
> They acknowledge sincerely that they have a problem, with a promise that they are going to fix it.
That's an optimistic interpretation of their blog post.
For expecting providers to provide what they say they're providing?
The scoundrels.
I was expecting more of a 'sorry, your holding it wrong' approach.
We might also consider the potential for a clash of cultures: Heroku has been relatively open about implementation details. Salesforce, on the other hand, has shown an extreme reluctance to share this kind of information.
I confess I can't help but wonder if the new willingness to make this kind of surreptitious change might in any way be connected to Byron Sebastian's sudden resignation last September. Is that nutty of me?
http://gigaom.com/2012/09/05/heroku-loses-a-star-as-ceo-and-...
We've been on cedar ever since it launched, and been running puma threads or unicorn workers. The idea of one dyno per request is bullshit, and I wasn't sure if they were on cedar or not. A dyno is an allocated resource (512mb, not counting db, k/v store etc)
How ballsy of them to complain when they are doing it wrong.
Random routing is still wayyyyy worse than intelligent routing even if you're processing multiple requests simultaneously on a single dyno (see http://rapgenius.com/1504222)
Requests will still queue, but since time spent queuing at the dyno level doesn't appear in your logs or on New Relic, you'll never know it.
That's a non-sequitur given that Heroku still supports it and didn't advocate migrating in their response.
It's fair to complain about a bug in Lion or in Windows 7 or in other products that are stil being supported. It's unfair to rail about a windows 95 bug, for example, but not something which is still being supported. And I'm surprised heroku didnt suggest Cedar in the response itself.
It doesn't matter if you think one dyno per request is "bullshit" or not, Rails isn't multithreaded, so what do you propose they do? Using unicorn_rails on Cedar lets you fork off a few subprocesses to handle more requests on the dyno queue which gets you a constant factor bite at the dyno queue lengths, a few weeks or months of scale at best - it's not a real solution.
Heroku knows that Rails on Cedar is just as affected by their inability to route requests and they're only not copping to it in this blog post because they don't have a customer running Cedar complaining so loudly. Which is cowardly.
> How ballsy of them to complain when they are doing it wrong.
If you mean that deploying a rails app to Heroku is doing it wrong - a sentiment many are agreeing with right now - then yes, you're correct!
Another way to put that is that using Cedar lets you get acceptable end user performance with far fewer dynos.
Sure it is. You just have to set `config.threadsafe!`, which right now is slated to be on by default in rails4.
But then you need a server stack that supports multi-threaded requests, such as puma which the parent comment mentioned using.
And then if you're using MRI, your multiple threads in a process still can't use more than one cpu at a time -- but this _probably_ doesn't matter in the scenario we're talking about, because a single heroku dyno isn't going to have access to more than one cpu at a time anyway, right?
How this all shakes out is indeed confusing. I am _not_ saying "If you just use puma and config.threadsafe!" all is well with their scheduler. I do not know one way or the other, it is hella confusing.
But it is incorrect to say "Rails isn't multithreaded, so what do you propose they do"
Rails does have config.threadsafe!, and it will be on by default in Rails 4. http://tenderlovemaking.com/2012/06/18/removing-config-threa...
- request comes in and gets routed to the dyno with the lowest count. Inc the count.
- response goes out. Dec the counter.
Since they control the flow both in and out, this requires at most a sorted collection of counters and would solve the problem at a "practical" level. Is it possible to still end up with one request that backs up another one or two? Sure. Is it likely? No. While this isn't as ideal as true intelligent routing, I think it's likely the best solution in a scenario where they have incomplete information about what a random process on a dyno can reliably handle (which is the case on the cedar stack).
Alternatively, they could just add some configuration that allows you to set the request density and then you could bring intelligent routing back. The couple of milliseconds that lookup/comparison would take is far better than the scenario they're in now.
EDIT: I realized my comment could be read as though I'm suggesting this naive solution is "easy". At scale it certainly isn't, but I do believe it's possible and as this is their business, that's not a valid reason to do what they are.
Do you have a distributed sufficiently-consistent counter strategy that won't itself become a source of latency or bottlenecks or miscounts under traffic surges?
That being said, health checks are nice for other reasons and could be used outside of the routing layer (which you need to sail along as quickly as possible).
We used to do long polling/comet in our app on Heroku (we axed that feature for non-technical reasons), which meant that many requests were taking several minutes while the framework could still process more requests. In your system, how would you account for asynchronous web frameworks?
But, I'm surprised they didn't wait until the "in-depth technical review" was available to apologize. And the idea that they were informed of a problem "yesterday" doesn't quite match the impression RapGenius gave, that they'd been discussing this with Heroku support for a while.
"tools to understand and improve the performance of your apps" only commits them to updating their docs and tools to reflect how their system really works. It doesn't indicate any intention to fix the actual problem (the fact that requests can be routed to busy dynos), nor that they will make any kind of reimbursement to people who made business decisions based on incorrect docs.
"develop long-term solutions" doesn't really mean anything.
| Working closely with our customers to develop long-term solutions
I cannot imagine this will be simple to fix. I don't know what Heroku's deployment is like^, but I figure it is very massive and complex and solving performance issues at that scale are not done overnight.
^That is the deployment and configuration of the Heroku platform, not how we as devs deploy to Heroku.
"Working closely with our customers to develop long-term solutions"
At this point I imagine they're in damage control mode; I'm not surprised they'd be reluctant to make new promises before everyone's on the same page about the technical issues.
"Working closely with our customers to develop long-term solutions"
There are probably some simple techniques whereby dynos can themselves approximate the throughput of routing-to-idle, while Heroku's load-balancers continue to route randomly. For example, if a 'busy' dyno could shed a request, simply throwing it back to get another random assignment, most jam-ups could be alleviated until most dynos are busy. (And even then, the load could be spread more evenly, even in the case of some long requests and unlucky randomization.) Heroku may just need to coach their customers in that direction.
For example, use a hashing algorithm that switches to 1 of N intelligent routers based on domain name.
If you pick the right algo you can pretty much add routers whenever you like.
(It would be nice to know what Heroku have tried so far, at the very least to drive off know-it-all blowhards like me.)
It's not an intractable problem, but it's not trivial, affects only a small percentage of customers, and introduces complexity for everyone.
I feel pretty confident that there is a reasonable solution, and as someone that just spent the last 3 weeks building a custom buildpack and a new heroku app for an auto-scaling worker farm, I am happy to see such a quick, hopeful response.
This will affect any user with a high standard deviation in their application's response time.
Lets take an extreme case as an example: An application that has an average response time of 100ms, however 1% of the responses have a 3s response time. They have relatively small load and they only have 2 web dynos running. The admin thinks: We have this occasional slow response, but it should be fine. When one dyno is chewing on the 3s task, the other dyno will pick up the slack. Wrong.
With random routing, when one dyno is chewing on the slow task, 50% of the incoming requests are stacking up in that dyno's queue. The other dyno may be able to easily handle it's load, but half of your responses are still getting hit with 3s+ delays.
This is an extreme example, but this is not a rare issue. As the admin, unless you know about this issue, you will be perplexed by the seemingly random slow response times your users will be reporting. You won't see the problem in your logs, or your New Relic performance reports, but your customers will notice.
As others have pointed out, a major selling point of Heroku is it is supposed to "just work." These sorts of issues are supposed to be intelligently handled by their super-slick infrastructure. In my opinion, this is a serious issue. The fact that this has been biting users for 3 years now and Heroku is only willing to address the problem after they get major bad press is disheartening.
I have always been impressed by Heroku, especially how they constantly step up, admit their mistakes, and appear to be as transparent as possible about how they will fix their issues. This situation is seriously disappointing.
I am sure this is a very difficult problem to solve at their scale, but this is really what we as customers are paying them to solve.
The decision made by heroku was not an engineering decision, it was a business decision. While it is quite a bit frustrating, it is understandable and I don't think it will change. Since reverting a whole infrastructure to its original no-longer-profitable position is generally not a smart move.
They'll just abandon rails devs and move on.
This is not only a problem for non-concurrent applications. It will become a problem as dyno usage increases for any application. The major factors will be the standard deviation of your response times and the number of responses you can handle per dyno. The issue just manifests first in applications that can only handle one request per dyno.
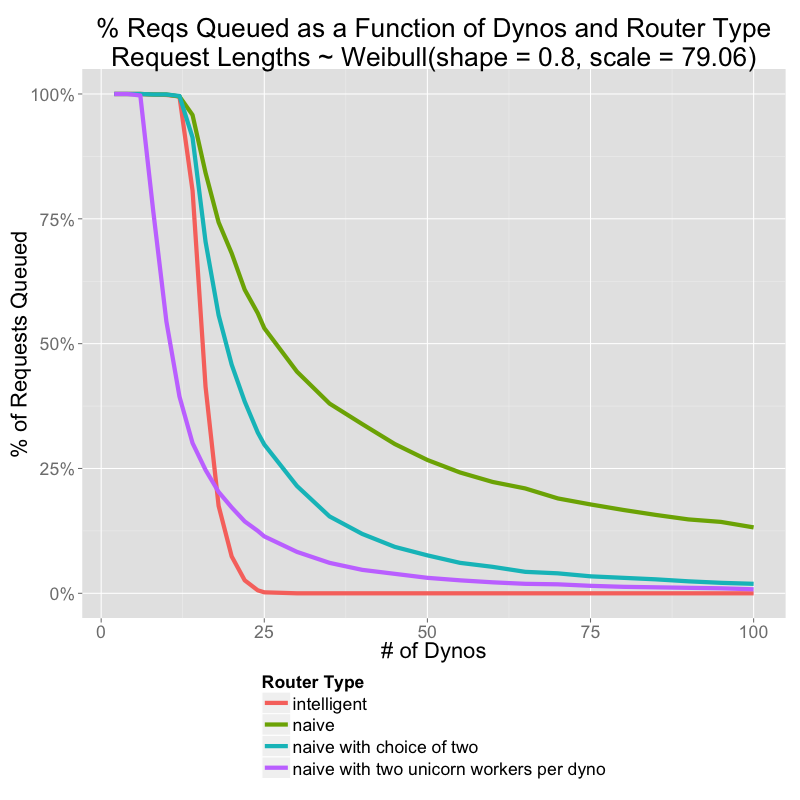
Check out this graph released by rapgenius: http://s3.amazonaws.com/rapgenius/1360871196_routerstyles_fa...
The purple line is a multi-threaded application. No matter how concurrent your framework, it is still possible to overload the resources of a single dyno. When that happens, the router will continue to stack requests up in the queue.
You replace intelligent request scheduling with more hardware and instances, which you charge the user for.
How much investment is there in platform service providers towards developing better schedulers that would reduce the number of instances required to serve an application? That answer, in this case, is "not a lot"
The incentives between provider and user are not aligned, which is why I am more inclined to buy and manage at a layer lower with virtual machines.
Edit: AppEngine went through a similar issue. Here is an interesting response from an engineer on their team:
https://groups.google.com/forum/#!msg/google-appengine/y-LnZ...
I think the practical significance of this kind of incentives is overrated. The company I work for does outsourcing work, paid by hour. Do they have incentives to make me produce less so that their customers pay for more hours? Theoretically. Do they act on it? Hell, no - there is competition and customer satisfaction matters.
There is plenty of competition for government work, but there are many ways to game the system even in the rare truly open/fair competitive bids.
Prices are usually determined more by competition than by technical factors. Unfortunately, there's a fair bit of lock-in to PaaS vendors, which is the real reason I'd be skeptical about building a business on them. The nice thing about the VM layer is there's a well-documented, public API between your code and the platform, so when your service provider raises their rates, you can switch to another one or operate your own hardware.
You could price per request that you serve for your customers. Of course that just puts the perverse incentive on your customers, since now the service provider is bearing the cost of a nonoptimized application. The client doesn't care much about the weight of a single request, since the cost to him is the same (well except for latency).
So what you could do is define a 'typical request' by running a suite of open source web application on the service provider. This way you see how much hardware is required for a given throughput of 'typical requests'. Put a price tag on that. Now pricing also becomes much clearer for the customers: they know that if their application's requests are roughly of the same weight as open source web application X, Y and Z, and if they serve N requests per month, then their cost will be roughly N*(price of 1 typical request) per month.
Now the service provider has the incentive to optimize its hardware and services, because then it can run more typical requests at the same cost. The client has the incentive to optimize his application, because then he will use fewer typical request units, and hence pay less.
You could also determine the cost of a typical request by averaging over all of your clients' applications, instead of a suite of open source applications.
And besides, I really don't see why someone who needs that many dynos is still on Heroku.
> The simulation was a bit of a stretch because the supposed number of servers you need to achieve "equivalent" performance is highly dependent on how slow your worst case performance is, and if your worst case isn't that bad the numbers look a lot better
It's still pretty bad. Here's a graph of the relative performances of the different routing strategies when your response times are much better (50%: 50ms, 99%: 537ms, 99.9%: 898ms)
http://s3.amazonaws.com/rapgenius/1360871196_routerstyles_fa...
See http://rapgenius.com/1504222 for more
if I understand the chart correctly, using unicorn with two workers gets you pretty close to intelligent routing with no intelligence. I imagine adding up to three or four would make things even better... I don't know about puma/thin etc where you can perhaps crank it even further without too much memory tax(?)
To me this seems like the easiest approach for everybody concerned. Heroku can keep using random routing without adding complexity, and most users will not get affected if they are able to split the workload on the dyno-level.
On a slight tangent: On the rails app I'm working on I'm trying to religiously offload anything that might block or take too long to a resque task. It's not always feasible, but I think it's a good common-sense approach to try to avoid bottlenecks.
Put it into context. Heroku made this change 3 years ago, and also has had no issues admitting the change to users. Their documentation has lagged far behind and I believe they will be more transparent in the future. This is an engineering decision they made a long time ago that happened to get a lot of PR in the past 24 hours. Until there is a business reason (losing customers), I don't see them "fixing" the problem.
You are almost investing in heroku by using their stack and tool chain, it isn't easy for well established customers to just up and move. This is probably a PR win for them, rather than a loss. Truth be told, it will be how they handle this in the coming months that will make them win/lose customers.
Or, for all we know, they could already be in the process of migrating away from Heroku, but that doesn't happen overnight and doesn't help their performance in the meantime.
Also, I'm not sure at what point this is, but at some point around say $3-5k a month, (100+ dynos) you really should rethink using Heroku. At that point and higher, you really ought to know about your infrastructure enough to optimize for scale. The "just add more dynos" approach is stupid because adding more web fronts is often the lazy/expensive approach. Add a few queues or some smarter caching and you'll need fewer web servers. Throw in something like Varnish where you can and you need even fewer servers. Point being, at some point scaling is no longer "free", it takes work and Heroku isn't magic.
If their platform can't handle higher amounts of load, they really should indicate as such.
Of the five action items they listed, it seems that only the last of them is about actually solving the problem. I hope they are committed to it - better visibility of the problem can help, but I'd rather not have the problem in the first place.
Long-term fixes actually do require deep analysis of alternatives (and even what the appropriate parameters are for a solution that will deal with customers problems while maintaining Heroku's scalability), and aren't something you can do much more than make vague references to off the cuff.
The key question on that point will be follow-through.
Perhaps this is ignorance on my behalf of how companies who have already been sold (Heroku) fit into the picture, but some explanation would be appreciated.
Random request routing is also present on Cedar [1]. The difference is that, on Cedar, you can easily run multi-threaded or even multi-process apps (the latter being harder due to a 512mb memory limit) which can mitigate the problem, but does not solve it. Modifying your app so all of your requests are handled extremely quickly also mitigates the problem, but does not solve it.
Seems to me the obvious solution is to do these things (multi-threaded app server, serve only/mostly short requests) and use at least a somewhat intelligent routing algorithm (perhaps 'least connections' would make sense).
[1] - https://devcenter.heroku.com/articles/http-routing#request-d...
Yet they state their action plan to "fix" this issue is to update their DOCUMENTATION and no mention of fixing the DEGRADATION issues itself.
Just bizarre.
This is flat out untrue. The third bullet point in their action plan is to update their documentation, and the fifth is "Working closely with our customers to develop long-term solutions".
Updating the documentation to accurately reflect what the platform does is obviously critical to allow people to make decisions and manage applications on the platform as it is, so is an important and immediate part of the action plan.
Long-term fixes to the problem are also important, and are explicitly part of the action plan. Its clear that they haven't identified what those solutions are, but its not at all true that they haven't mentioned them as part of the action plan.
Sure, it's great they responded. The response should be "you're right, we are fixing it and issue credits" for revenue gained from fraudulent claims about the performance of their product and a credibility straining bait-and-switch.
They saw the potential loss in customers, and then acted. What this means is that they never had in mind to provide the best support and product they could for their customers before this news broke out.
Sad.
What disheartens me is that the documentation discrepancy caused real, extremely substantial aggregate monetary impact on customers, yet there is no mention of refunds. Perhaps that will come, but in my opinion, anything short of that is just damage control.
This is a time excessively demonstrate integrity, for them to go above and beyond. It's in their interest not to just paper over the whole thing.
This feels like something that would have been connected to the Salesforce acquisition 3 years ago, and then making the service less efficient in order to increase profits or revenue targets on paid accounts. Not to mention saving money on the free ones.
It would be a little bit like Tesla not only selling you the Model S, but also selling you the electricity you charge the vehicle with. At some point, they make the car less efficient, forcing you to charge more often, and then claiming they didn't document this very well. Frankly, there are only so many people who will be a capable enough electrical engineer (or in Heroku's case, a sysadmin) to catch the difference and measure it.
The apology should be, "we misled you, and betrayed your trust. Here's how we're planning on resolving that, and working to rebuild our relationship with our customers over the next year. [Insert specific, sweeping measures...]
We all need to remember that there are no magic bullets. The fact that Heroku can get a startup to, say, 5M uniques per day by dragging some sliders on a web panel and running up a bill on a corporate AMEX is pretty impressive.
At some point scaling a web business becomes a core competency and one needs to deal with it. I'm guessing by the time scaling an app on Heroku becomes an issue, if better understanding your scaling needs and handling them directly isn't going to save you a TON of money, your business model is probably broken.
Our response: http://rapgenius.com/Oren-teich-bamboo-routing-performance-l...
Also, I really love seeing a company take responsibility like this. I know the situations (and the stakes) are not comparable but this is a lot better than what Musk did when Tesla got a bad review. As a company just take the blame and say you can and will fix it, that's good enough for most people.
{kind=link}