Is this microsoft stating that they aren't able to get acceptable reliability from Azure? (I mean, I think a lot of us have heard that, but it's interesting to hear it from microsoft themselves).
There's no intrinsic reason they should be vulnerable to themselves.
XXXXL size project. May not ever deliver. But if it fails, it will only do so after years grinding through people, resources, etc.
Global indices for this should be trivial to spin up so availability is never a concern (we're working towards this!).
And if they are using 3rd parties to host their stuff, inevitable 1-3 big players will show up offering that as a service.
And even if you do host your own stuff to avoid availability problems, the big actors can still fail just like GH and you can't do shit coz your dependencies need it.
So the solution is same as it is now, proxy or mirror everything you use
Disclaimer: the author is a colleague of mine
Though to be fair, what the parent meant by federated forges is different than this approach.
If I could get the same bells and whistles by wiring up another forge, so long as it offered a decent API and/or sent events over a webhook, I'd have everything self-hosted.
The agents would need to expose an interface on their own end but as long as you implemented it with a plugin, it'd take the dependency of GitHub and you could use MCP or skills for the rest of it.
Which is to say, this is perfect for agents given they don't need any bespoke SDK from us: simply write Tangled records for issues, pulls, whatever to your PDS and it'll show up on Tangled. We plan to start working on some exemplar agents first-party that would 1. enhance Tangled itself, 2. showcase cool things you can do with an open data firehose.
I recently migrated to codeberg because I'm okay with self-hosting big runners, while using codeberg's available runners for smaller cron-based things (they even have lazy runners for this).
The internet should not be centralised, but you can't make a billion dollar company without capturing the world and selling your company to a trillion dollar company
> GitHub Will Prioritize Migrating to Azure Over Feature Development - GitHub is working on migrating all of its infrastructure to Azure, even though this means it'll have to delay some feature development.
> In a message to GitHub’s staff, CTO Vladimir Fedorov notes that GitHub is constrained on capacity in its Virginia data center. “It’s existential for us to keep up with the demands of AI and Copilot, which are changing how people use GitHub,” he writes.
https://thenewstack.io/github-will-prioritize-migrating-to-a...
So the currently delayed feature development is now gonna be further delayed, yet almost every week we see new features and changes, just the other day the single issues view was changed, as just one example. And it was "existential" 6 months ago yet they keep stumbling on the exact same issue today?
Even if they're focused exclusively on reliability and uptime, we get the experience that we have today, kind of incredible how a company with the resources of Microsoft seemingly are unable to stop continuously shot themselves in the foot. It's kind of impressive actually. As icing on the cake, they've decided to buy up all popular developer services then migrate them all to the same platform, great idea too.
Where it becomes questionable though is when enough progress isn't being made on the top priority (reliability). If Github is being true to their word, they need to be pulling people off of teams that are working on features to work on reliability so that top priority gets the resourcing it needs.
Given the pace of improvement, and the cited example of moving to Azure from months ago, it's not super clear they are doing that. Also not clear that they aren't, maybe the move to Azure is just a more than 6mo project no matter how many people are on it.
I still think the rest of my point stands, especially the last one which is the move that has the biggest impact to the most of us developers.
Did we lose our ability to consider them the evil empire?
There is so much workload running on Azure, i never heard of VMs go away.
If Microsoft can source hardware for Azure, Microsoft can source hardware for Github.
They did that as a panic mode hack to mitigate performance: https://news.ycombinator.com/item?id=47912521
They severely nerfed their search, I'm not sure why every other major tech company (Google - Search and YouTube) keeps breaking search for everything when it was working fine previously.
What's a bigger joke is Microsoft has Azure DevOps which looks like it might be abandoned? But then you also have GitHub... My least favorite thing about both is the ticketing system, I cannot believe that I'd ever utter the phrase "I miss Jira" when every Jira project I've ever been in had been so inconsistently setup, every, single, one.
It's only job is to display diff and review comments and it easily hide the diff for files that are a lit bit longer and hide comments when you have more than a dozen. You need to click to see. It's impossible to search in diff without going through it to expand everything.
And a ton of things are regression compared to working with pr a few years ago. Including being a lot worse in terms of latency!
My favorite was trying to figure out how to publish debug symbols with NuGet packages to Azure DevOps artifact feeds. Horrible documentation and I was never able to get it figured out.
This always kills me. It used to work so well, and now it doesn't seem to work at all if not logged in, and not particularly well if you are logged in.
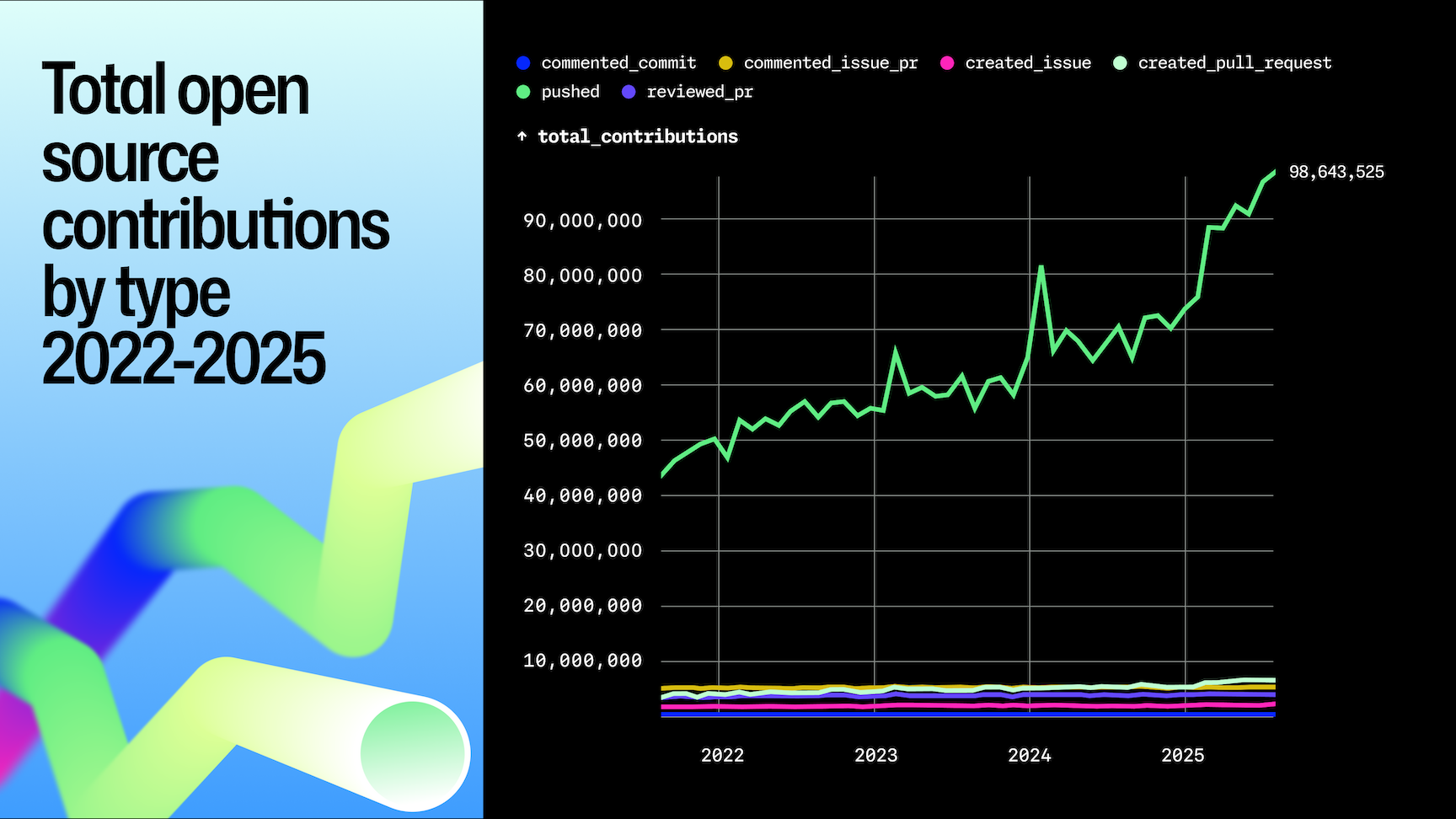
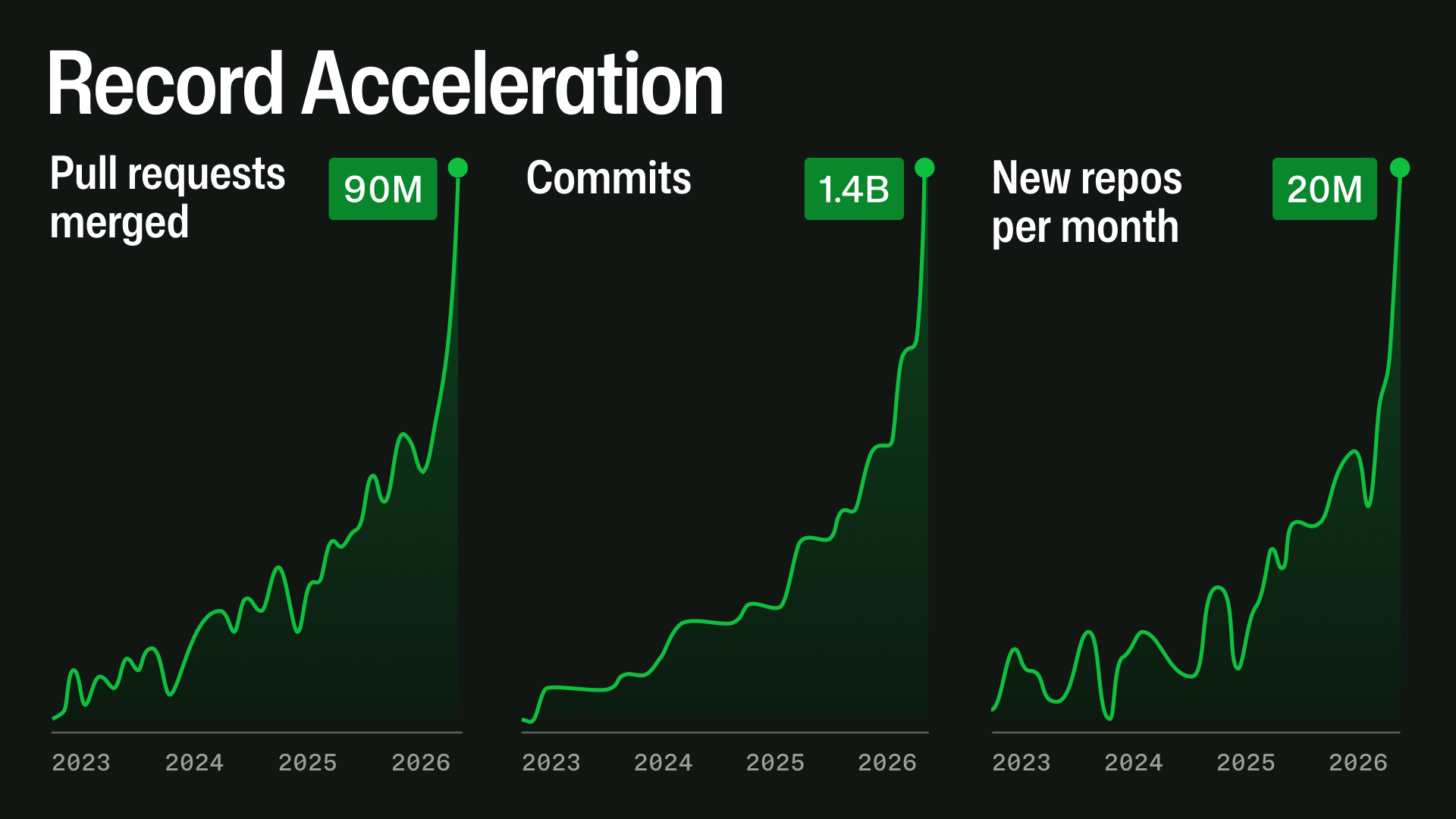
The unlabelled graph with big numbers on top, the priorities that don't match with what we're experiencing, and a list of things that they're doing without a real acknowledgement of the _dire_ uptime over the last 12 months....
You don't need to know the bottom left axis number. We do have to assume the graph is linear, and not some kind of negative exponent log graph. But given the rest of the content, I think that is safe to assume.
Any company that experiences significantly more growth than they were planning for will have capacity issues.
The priorities are most inline with that. The are way beyond the point that they can just add more hardware. They need to make the backend more efficient, and all the stated goals are about helping there.
We very much do. The graph suggests an insane growth in PRs from almost zero to 90M. Now compare this misleading graph with this much clearer one, which shows that the growth over the last three years has been less than 80%: https://github.blog/wp-content/uploads/2025/10/octoverse-202...
No, they're completely useless. Using the "New repos per month" as an example, if the bottom left is 1m, then that's a 20x increase in 2 years which is a lot. If the bottom left is 19m, it's a 5% increase in 2 years which is nothing.
The massive surge on their labelled X axis starts in 2026, and these issues have been going on for a lot longer than that. GHA has been borderline unusable for a year at this point, if not longer.
> But given the rest of the content, I think that is safe to assume.
The rest of the content is "we're working on it", and "here's two outages in the last 14 days, one of which caused actual data loss"
What's the question here, you don't believe growth is currently exponential, or do you think it shouldn't be hard to scale, when 10x YoY is not enough?
I’m sure they’re experiencing scaling issues across the platform, but it’s unacceptable for that to have a negative impact on us when we're sending them $250/dev/yr for (what is in all honesty) hosting a bunch of static text files.
> What's the question here, you don't believe growth is currently exponential, or do you think it shouldn't be hard to scale
I think you're putting words in my mouth here; I didn't say either of those things. I'm saying that this blog post is a meaningless platitude when the github stability issues predate this, and that all this post says is "we hear you're having issues".
GitHub is claiming they require 30x scale due to the giant increase in repository creation, PRs, commits, etc.
I have not seen a single product increase in features or quality as an end user, nor new significant products have come out in this period (other than the LLMs themselves).
Where is all this code going?
What I’m not seeing here but I am seeing with the Linux kernel is, most of the automatically submitted code is irrelevant or not useful
(Maybe that’s what you were getting at, apologies)
Yes, that was the intented meaning, sorry if it wasn't clear.
My point was that, if we can assume github's load is a decent proxy for global code generation, we're generating 30x without 30x results.
30x means that iOS could generate as many features as it has had since development in just a year. I don't think there is evidence of even 2x delivery in the industry.
Half of my friends is vibe-coding something but they can barely get the rest of the group chat to use it once.
In companies, I see people vibe-coding "miracle apps" that fall under the smallest amount of scrutiny.
Basically people are doing the same developers do when they say "I can do this in a weekend", which is getting a prototype sort of running and then immediately losing energy (or in this case lacking ability) to push it forward.
Some people I know can't even explain what they are trying to create.
Since yesterday, me and several colleagues noticed that the pull request lists on the website are incomplete, across many repositories. For example, on https://github.com/gap-system/gap/pulls it says "Pull requests 78" in the "tab list", but the PR list view reports "35 open" (the number 78 is correct, and confirmed by e.g. `gh pr list`)
And that despite <https://www.githubstatus.com> reporting "all systems operational".
Their support acknowledged the issue, but has been silent since then, and the status page still shows nothing other than the potentially-related issue on the 27th. It looks like it has been resolved on some repositories in the meantime, but I still have the issue across multiple orgs and repositories.
Surely a scaling hack where they use "estimation" queries that return "kind of right" results instead of 100% correct data, as it's less load on the infrastructure. Not necessarily a bug as much a shit choice from product perspective.
Sorry, but I don't think there is any way this can be classified as "not actually a bug"
I’m sure survivor bias is at play here, but when I look through the older code bases - especially the data model - it’s an entirely different world than the newer stuff, and it’s clear which of the two was written by people who understand systems.
are there big conceptual serialisations that I've missed? is it just not well factored? was the move to Azure just a catastrophically bad idea? some other thing?
Even as recently as 18 months ago, Lovable appeared, seemingly overnight, and caused huge problems for GitHub because they were creating repositories on GitHub for every single Lovable project, offloading the very high cost onto GitHub, hundreds of thousands of repositories. A couple of years before that, Homebrew used GitHub as a de facto CDN and that was a huge problem, too.
Nowadays it is easy to imagine how we can scale out a service like Twitter or YouTube or Facebook because everything has been done before, but that's not true of Git, Git hasn't ever scaled like this before, there are very few examples of service with GitHub's characteristics.
> To summarize, for every v1 diff line there would be:
> - Minimum of 10-15 DOM tree elements
> - Minimum of 8-13 React Components
> - Minimum of 20 React Event Handlers
> - Lots of small re-usable React Components
https://github.blog/engineering/architecture-optimization/th...
What always struggled was the richness of the Rails monolith itself and its backing MySQL databases - the expectation that everything links to everything throughout the product (think: issue cross references across orgs that only appear if you're able to access the remote repo, and other things like that).
Those details appear richly everywhere you look, and the combination of that with a general lack of understanding and/or focus on performance (shipping big features is hard, shipping them with performance at scale is MUCH harder), compounded by Ruby being an easy language to get performance wrong in (object count really hurts, and it makes it very easy to create many) leaves every feature adding to the performance problem, and makes it daunting/impossible to make fast once it's slow.
There was a full on year or more of making GitHub fast while I was there that just couldn't gain enough momentum to make enough of a dent to make it better. I remember finding and fixing a N^3 (or maybe it was N^4? something bad) in the home page activity feed - the worst thing I found but gives an idea. IMO it would need a fresh view of how to keep interfaces simple and how to design the data layers performantly - not adding every bell and whistle to every screen.
I hope someone at GitHub realises they are about to lose everything that was hard earned by early GitHub - it once was a site people (myself included) looked up to for ideal availability, responsible releases, data driven improvement - but no more it seems :(
[0] https://docs.codeberg.org/getting-started/faq/#how-about-pri...
[Emphasis mine]
Vlad, you are living in a very different world to me.
GitHub has suffered dozens and dozens of outages since the beginning of the year. It is notably less available and reliable than it was even as recently as last year. People have created dashboards and heatmaps showing how bad GitHub has become. At least one of those has made it to the front page of Hacker News. In fact its unreliability and persistent availability issues have become a frequent topic of conversation across sites and communities frequented its users - of which HN and Reddit are two obvious examples. At this point GitHub's unreliability risks becoming a meme, if it hasn't already done so.
The only thing your post makes clear is that your priorities ARE NOT clear.
> Our priorities are clear: availability first, then capacity, then new features.
WRONG!
Your priorities are:
1. Availability 2. Availability 3. Availability
You have NO OTHER PRIORITIES.
If you want other priorities, focus on AVAILABILITY for 6 months and then come back and we can all have a serious conversation about something else.
In the meantime, you need to understand that GitHub's reliability over months and months - not just in April - has been completely unacceptable.
Focus on fixing that and on nothing else.
On an average ~8 hour working day, there's at least one failed request. In fact, looking over the logs, I can't spot a single day that did not have a failed request.
Now, I can't guarantee that these are all caused by GitHub (as opposed to my connection), but it is pretty funny.
Security or trust not even making the list.
I feel like this would have negative impacts (lots of interesting historical archives on Github) but maybe if a project hasn't been touched, or cloned, in some time, it just gets deleted with some notice.
Just last week I found an interesting repo that hadn't been touched in 9 years. I immediately cloned it as it was something reverse engineered so DMCA isn't out of the question, but now I have two reasons to clone.
Looking at the commit graph: Why do commits have big steps followed by slow rolloffs? Why do the steps not happen at uniform points Why do larger steps sometimes have less of a slope than smaller steps but not all the time?
Then looking at the other graphs there's completely different effects going on.
If this is the unvetted and unbased information they are putting out in public facing-blogs, only the stars would know what data is being "presented" in their boardrooms
GitHub instability has started way before that. I understand it’s too much to ask of a trillion-dollar corporation to consider the impact of their own actions, but perhaps they should’ve thought of that before forcing LLM development down everyone’s throats.
They started the trend with Copilot.
> If they weren't letting folks use it directly
There is a chasm of difference between “letting you use it” and “forcing it down your throat”. Microsoft is doing the latter, not the former. Copilot is annoyingly present by default at every step on GitHub.
* we had to resolve a variety of bottlenecks that appeared faster than expected from moving webhooks to a different backend (out of MySQL)
* * redesigning user session cache to redoing authentication and authorization flows to substantially reduce database load.
* we accelerated parts of migrating performance or scale sensitive code out of Ruby monolith into Go.
I'd like to know what database backend they migrated to. I was also surprised to read that the migration from Ruby to a more performant language had not already been completed. I assume this is because it a large code base with many moving parts, etc.
amazing on one hand, quite scary on the other for github and all other forges if this continues and there is no reason why it wouldn't.
The user (and not a big tech monopoly) answer to scaling issues is almost always to stop scaling and start federating and interoperating.
I was thinking of maybe doing a proper write up about how to host your own Forgejo + Action runners on Linux, Windows and macOS, not sure if there is enough interest. What would people for sure want to know in a guide/explanation of this?
The only repos I left on GitHub are forks and one with a bit of public engagement.
I think I found the issue.
and that azure cannot scale fast enough to handle the load so they're embracing multi-cloud as a company... owned by microsoft?
woah. what am I reading.
I am surprised that Microsoft is allowed to use Go. How long will it be before a bean counter forces a rewrite to a Microsoft favored language?
Status page is also still doing that thing where every component is green but in practice clone is hanging, push is timing out, actions are stuck. Per-service uptime is a managed number. The user-experience number is the one that matters and it's not in the post-mortem.
> availability first, then capacity, then new features.
I'd love to experience first-hand a leadership team who says, "stop accepting new paying customers until we've got availability sorted out!"
> New sign-ups for GitHub Copilot Pro, Pro+, and Student plans are paused. Pausing sign-ups allows us to serve existing customers more effectively.
I understand the rapid growth (because of AI agents), but if such critical software service becomes unstable then it's time to migrate? Thinking about self-hosting GitLab.
Right way to think about this:
> If things we need/see as critical for our work are hosted on a platform with really bad reliability, it's time for us to migrate
My internet connection at home is really shit, and almost every week there is a multi-hour downtime for some reason, not to mention when La Liga games are on TV anything using Cloudflare is unavailable, so I've had to spend extra energy and time to setup things in a way so I can still work whenever this happens.
That's a delayed April fool's right?
If you multiply all current numbers together (as of Apr 28), you find out that GitHub has a 97.26% uptime.
One ... single ... 9.
They can do better.
> you find out that GitHub has a 97.26% uptime
Calculating that to "Downtime per day" you get ~40 minutes of downtime per day, almost a week per year. Crazy stuff for something essential like this.
Stop subsidizing tokens now that we extracted enough training data from you and we have enough agentic junkies business to keep the flywheel going up and cut on the loss leaders. [0]
No mention of Copilot/slopiffication. Probably an intentional omission as Microsoft only has one true priority across all of its products.
So, it's because of LLMs guys.
The unlabeled graphs don't help the credibility case. When you are already in the hole on trust, shipping a post that requires readers to assume favorable baselines is exactly the wrong move.
Yesterday was the last straw for me - I've begun migrating my personal private projects and my contracting firm's projects off of github.
on another note - is the exponential growth from 'agentic' workflows actually resulting in productive software in the wild. Or it is just noise. On my end I haven't seen the software I use getting better.
In seriousness, looking at their scale, this is an insane engineering challenge.
Especially if they’re moving databases, not easy ever, and certainly not at that scale
Now that’s the kind of excellence I expect from the GitHub engineering team
Wild
Good chuckle out of this post, it’s crazy that neither Atlassian (Bitbucket) or Gitlab are capturing value out of this same agentic coding boom. I wish github was separately publicly traded outside of Microsoft.
Nowhere to get exposure to this
Leopard, meet face.
Too little too late, yesterday was the straw that broke the camel’s back for us and we’ve started a migration to a self-hosted GitLab.
[0] https://github.com/actions/checkout#note
[1] https://github.com/actions/checkout/issues/270#issue-6289677...
This company is owned by one of the major causes of the AI boom and is hiding behind difficulty scaling, despite its parent company also being a premier source of scaling solutions.
GitHub: don't gaslight your customers.
It is not your customers' problem that you're having trouble scaling. Nobody cares. Give us the service we are paying you for and make it reliable, or else we'll choose something else.
After the words "Both of those incidents are not acceptable" the blog post should have been over. Nobody needs to hear a sob story about how your service is too popular.
Long live Github under MS!
I mean: obviously, in the old world, it would have taken lot of work to improve the situation. But now, with AI, just plug copilot against the code base and everything is fixed in a week, no ?
{kind=link}
{kind=link}