So storing the diagonal as a matrix and the new bases is more compact?
But if they read your paper enough that they invited you to a talk, that probably means they were far enough along to independently inventing it they were going to do so anyway, and wanted to chat with someone who was also doing the thing they were already doing. Good ideas tend to reveal themselves to anyone who is aware of the problem.
That's more than a stretch. They likely invited them because someone thought the abstract sounded interesting, or something like that.
> "TurboQuant starts by randomly rotating the data vectors. This clever step simplifies the data's geometry"
If I throw a bunch of shapes on the ground, tightly packed and touching each other, then rotate all of them, you can't guarantee that the new conglomerate shape is any more/less "simple" than before, right?
> "Johnson-Lindenstrauss Transform to shrink complex, high-dimensional data while preserving the essential distances and relationships between data points. It reduces each resulting vector number to a single sign bit (+1 or -1)."
What happens is that you get very spikey activations, there are so called "outlier" activations. A easy to read paper that tells you about this is SmoothQuant [0]. Another source from Anthropic and the Mechanistic Interperability people is calling these "privileged basis" [1].
Now based on the weight symmetries of a typical transformer, these actually don't need to exist. Weight symmetries means the ways you can change the weights without actually affecting the mathematical function, there are a broad class of these because the linear algebra has a lot of redundancies in it.
But the behaviour of the Adam optimizer is such that you do end up w/ these things because it sort of more quickly optimizes to produce them. This comes from the fact it is an elementwise dynamic learning rate (and probably partly to do with the epsilon).
[0] https://arxiv.org/pdf/2211.10438 [1] https://transformer-circuits.pub/2023/privileged-basis/index...
> In particular, we can generate fixed random rotation matrices at initialization, and multiply them into the activations any time we read from or write to the residual stream.
In simple terms, large ML models like LLMs often learn trivial rules such as "if the 21st decimal place of the 5th dimension in the embedding vector is 5 - then the image is of a cat." Learning such a memorization function is usually not what we are trying to do, and there are a variety of techniques to avoid these trivial solutions and "smooth" the optimization geometry.
Thanks so much for the explanation
Let's pick a simpler compression problem where changing the frame of reference improves packing.
There's a neat trick in the context of floating point numbers.
The values do not always compress when they are stored exactly as given.
[0.1, 0.2, 0.3, 0.4, 0.5]
Maybe I can encode them in 15 bytes instead of 20 as float32.
Up the frame of reference to be decibels instead of bels and we can encode them as sequential values without storing exponent or sign again.
Changing the frame of reference, makes the numbers "more alike" than they were originally.
But how do you pick a good frame of reference is all heuristics and optimization gradients.
Matrices are numbers [x,y,z]
GPUs are matrix processing units
Models are big matrices, we quantize them to make them small. That is lossy. Makes AI dumber the harder you quantize but lets you run inference with lesser hardware
What if you could quantize less destructively/lossy? You could make a model way smaller or make much bigger models that run on less RAM
That is what they achieved here. They're not saying that multiplying the matrices with scalars up or down helps. They're saying that by mutating and transforming the matrix with a function (ie. rotating the dimensions by the same "random" rotation) you have matrices that make smarter models fit in smaller boxes, needing way less RAM to achieve the same performance
If we quantized it as aggressively as we would have without the distribution/mutation function, the drop in benchmarks would be even more noticeable
It's actually a huge breakthrough and commercially its probably only a short term loss in valuation for the manufacturers
>How can a boolean value preserve all of the relational and positional information between data points?
They aren't reducing entire vector to a bollean only each of its dimensions.
as for the J-L transformation is way above my head so i'm almost certainly mistaken but it seems to be some clever way to use a bit as a sort of pointer in order to reuse existing chunks of parameter weight data like in a jpeg or zip compression algorithm.
Is is something like pattern based compression where the algorithm finds repeating patterns and creates an index of those common symbols or numbers?
“”” For the full technical explanation with equations, proofs, and PyTorch pseudocode, see the companion post: TurboQuant: Near-Optimal Vector Quantization Without Looking at Your Data.“
“ TurboQuant, QJL, and PolarQuant are more than just practical engineering solutions; they’re fundamental algorithmic contributions backed by strong theoretical proofs. These methods don't just work well in real-world applications; they are provably efficient and operate near theoretical lower bounds.”
It reads like a pop science article while at the same time being way too technical to be a pop science article.
Turing test ain't dead yet.
> Instead of looking at a memory vector using standard coordinates (i.e., X, Y, Z) that indicate the distance along each axis, PolarQuant converts the vector into polar coordinates using a Cartesian coordinate system. This is comparable to replacing "Go 3 blocks East, 4 blocks North" with "Go 5 blocks total at a 37-degree angle”
Why bother explaining this? Were they targeting the high school and middle school student reader base??
Every architecture improvement is essentially a way to achieve the capability of a single fully-connected hidden layer network n wide. With fewer parameters.
Given these architectures usually still contain fully connected layers, unless they've done something really wrong, they should still be able to do anything if you make the entire thing large enough.
That means a large enough [insert model architecture] will be able to approximate any function to arbitrary precision. As long as the efficiency gains with the architecture are retained as the scale increases they should be able to get there quicker.
All the foundation model breakthroughs are hoarded by the labs doing the pretraining. That being said, RL reasoning training is the obvious and largest breakthrough for intelligence in recent years.
The most important one in that timeframe was clearly reasoning/RLVR (reinforcement learning with verifiable rewards), which was pioneered by OpenAI's Q* aka Strawberry aka o1.
(Sorry for my terrible English, it's not my native language)
The last query in the sequence will be new for every new token you predict, but the set of prior keys and values stay the same, ie keys and values are reusable. The key value cache gets bigger and bigger for each new token you add to the sequence, and that’s where compression comes in. You have to store the keys and values in vram, and you’d like to keep the size down by not storing the raw uncompressed tensors. To make this work well your compression needs two things: it needs to be fast so that you can compress and decompress on the fly, and it needs to play well with softmax attention. Prior attempts at compression usually suck at one or the other, either the speed to decompress is too slow and your token/s takes a hit, or you lose important precision and the model output quality suffers. The claim in the paper is that they’ve made progress on both.
Hopefully Johnson–Lindenstrauss lemma applies in the same way for SRHTransformed vectors as they do for randomly rotated vectors and the independence of the distribution laws of the coordinates remains and therefore the quantization of each coordinates independently is still theoretically sound.
Look at this figure: https://storage.googleapis.com/gweb-research2023-media/image...
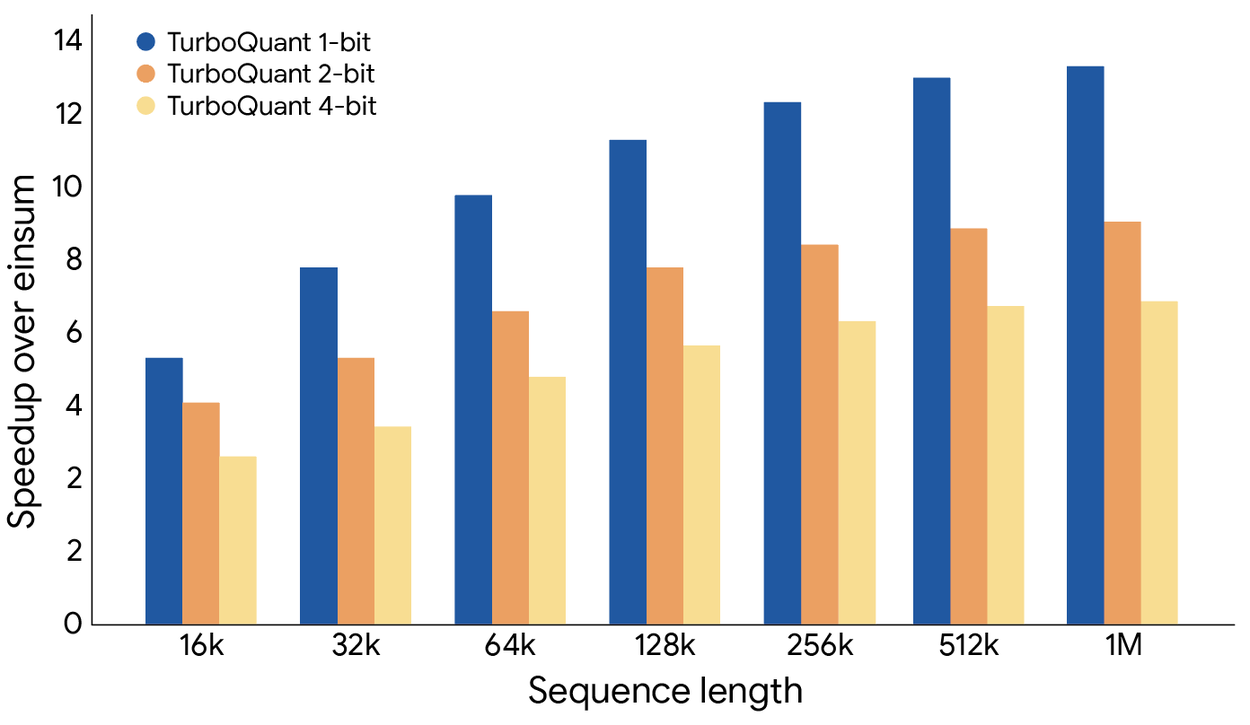
The speedup labels on the vertical axis are 0, 2, 2, 4, 6, 8... Why is 2 repeated? Did they just have nano-banana make them some charts? Can they not be bothered to use matplotlib or bokeh and directly render a graph? I don't know, maybe there is some legitimate reason that I don't know about for making a single value occur multiple times on a graph axes, but if that is the case, then they probably need to explain it in the figure caption. So it's either a "GenAI special" or it's poor communication about how to read the graph...
Look at this video visualization: https://storage.googleapis.com/gweb-research2023-media/media...
Do you have literally any clue what Polar Quantization is? Would this make me think, "I kind of have a high level understanding of that, let me go get the details from the paper."
Look at this figure: https://storage.googleapis.com/gweb-research2023-media/image...
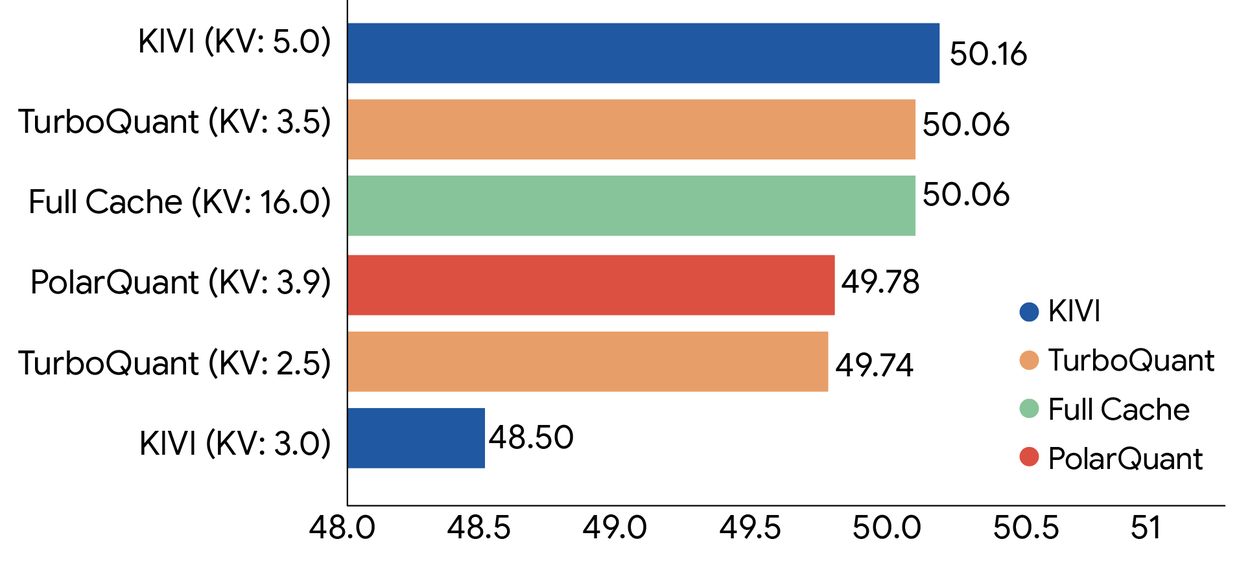
The left hand side of the graph, which is normally assumed to start at 0, starts at 48. Those MASSIVE differences you see in the figure? Only a few percent. And that's a deception but only if the figure is even accurate, because we saw earlier they can't even get figure axes correct.
The core idea is to quantize KV cache, but do so in a way that destroys minimal information. In this case, it's similarly scores between vectors. The simplest way to do this is to change all the elements from 16bit of precision to, say, 4 bits (Scalar Quant.). These papers improve on it by realizing: almost all the energy (concentration of measure) is towards the equator of the hypersphere (normally distributed as 1/d; d=vector dimensionality). (The curse/blessing of hyper dimensionality strikes again.) So when we quantize the elements (think "latitudes", e.g. to the nearest degree) we destroy a lot of information because basically all the vectors were around the equator (so some latitudes have a lot of vectors and some have very few). The idea is to rotate the vectors away from the equator so they're more consistently distributed (to better preserve the entropy during quantization, which I guess was amitport's DRIVE idea). PolarQuant does a hyperpolar coordinate transform which superficially seems neat for preserving entropy because of this equator/polar framing (and ultimately unnecessary as shown by TurboQuant). They also realized there's a bias to the resulting vectors during similarity, so they wrote the QJL paper to fix the bias. And then the TurboQuant paper took PolarQuant + QJL, removed the hyperpolar coords, and added in some gross / highly-pragmatic extra bits for important channels (c.f. elements of the vectors) which is sort of a pathology of LLMs these days but it is what it is. Et voila, highly compressed KV Cache. If you're curious why you can randomly rotate the input, it's because all the vectors are rotated the same, so similarity works out. You could always un-rotate to get the original, but there's no need because the similarity on rotated/unrotated is the same if you compare apples to apples (with the QJL debiasing). Why was PolarQuant even published? Insu Han is solely on that paper and demanded/deserved credit/promotion, would be my guess. The blog post is chock-full of errors and confusions.
PolarQuant does live on in TurboQuant's codebooks for quantization which borrows from the hyperpolar coords
I'm curious what you meant by that. I understood it to only have the MSE quantization vector, a 1-bit QJL vector, and a scalar magnitude.
> PolarQuant does live on in TurboQuant's codebooks for quantization which borrows from the hyperpolar coords
Isn't the turbo codebook the irregularly spaced centroid grid?
On the second quantization step: the paper's inner-product variant uses (b-1) bits for the MSE quantizer shown here, then applies a 1-bit QJL (Quantized Johnson-Lindenstrauss) encoding of the residual to make dot-product estimates unbiased. I chose to omit QJL from the animation to keep it digestible as a visual, but I've added a note calling this out explicitly.
Does this mean I would be able to run 500b model on my 48gb macbook without loosing quality?
https://mesuvash.github.io/blog/2026/turboquant-interactive/
Trivially, with r=0, the error is 0, regardless of how heavily the direction is quantized. Larger r means larger absolute error in the reconstructed vector.
"The TurboQuant paper (ICLR 2026) contains serious issues in how it describes RaBitQ, including incorrect technical claims and misleading theory/experiment comparisons. We flagged these issues to the authors before submission. They acknowledged them, but chose not to fix them. The paper was later accepted and widely promoted by Google, reaching tens of millions of views.
We’re speaking up now because once a misleading narrative spreads, it becomes much harder to correct. We’ve written a public comment on openreview (https://openreview.net/forum?id=tO3ASKZlok).
We would greatly appreciate your attention and help in sharing it."
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
> This clever step simplifies the data's geometry
No self-respecting researcher talks about their work in this way. But it is characteristic of these chatbots' tendency to over-use superlatives and sycophantic language.
{kind=link}
{kind=link}