But the implementations are rarely extracted out for general purpose usage and rarely have a rich API.
I've been thinking a lot about a general purpose "epoll" which be registered on objects that change. I want to be able to register a reaction to a sequence of actions on arbitrary objects with an epoll style API.
One of my ideas is GUI thunking. The idea that every interaction with the GUI raises a new type that can be interacted with, to queue up behaviours on the GUI. This is essentially Future<> that are typed and the system reacts to the new type based on what you did and presents a GUI that is as if the operation you queued up was completed. (You can interact with the future because any action on something that isn't done yet, is queued up)
It's a bit like terraform plan and apply, but applied to general purpose GUIs.
For example, you can click download file, then queue up installation and then using the application, ALL BEFORE it is installed. Because the actual computation is separate from the type information that was queued up.
Imagine using AWS Console to set up an entire infrastructure and wire everything together but not actually execute anything until the very end when you click "Run".
https://github.com/samsquire/gui-thunks
I feel we are still early days with regard how to build computer user interfaces that are easy to build, maintain and understand the code for.
I used knockout and angularjs 1 and I enjoyed Knockout especially. ko.observables and the map plugin makes creating reactive code very straightforward.
This rings so true to me.
I've recently realized how every single non trivial part of my app is in fact a workflow problem : it could be ideally written as a pipe of asynchronous steps, glued together. It's true both for the frontend part and the backend.
I believe that's the point of reactive frameworks, but somehow those frameworks are usually designed around continuous streams of incoming events. Which isn't what i've noticed is the most widespread case. One-shot instanciation of pre-designed workflows would be really ideal.
It's also why it's so unfortunate data modelling is often ad-hoc by defaulting to some bucket-of-json model with no regard for the needs of the application.
I also think surprisingly often, given some ideal data modelling, it's both faster and easier to use synchronous processing because you no longer end up having data far away in weird formats.
Many problems can be workflow problems, sometimes even pulling in a rule engine, or require a job queue to do things that can fail.
Then you have software such as https://temporal.io/ which is really powerful for resilient workflows.
Imagine coordinating the user with a workflow with asynchronous data collection steps.
Imagine programming "reaction to user behaviour as a workflow engine". Can coordinate global user behaviour with a resilient workflow script.
await user.login();
if (user.showTutorial()) {
await user.tutorial();
}
await user.checkout();
await user.submitOrder();
SolidJS pitches its state management as being robust enough for use outside of itself.
IMO, most state management tools baked into ui frameworks aren’t robust enough to be worth extracting.
All operations get "queued up" in IO and only run "at the end of the world".
To write your program you `flatMap` over the `IO`: An `IO` contains the computation(s) that will run at some point, but you can map on the result of them right away, and return another `IO` value; than `flatten` the `IO[IO]` data structure (which makes `flatMap`). In Haskell you have extra syntax for `flatMap` called "do notation". In Scala, where there are library solutions for `IO`, you can use "for comprehensions" instead. In both cases the nested `flatMap` calls get sequenced. This way and you can write code almost like a consecutive chain of imperative procedure calls but it all gets "queued up" and the whole program only runs when the `IO` data structure gets evaluated by the runtime ("at the end of the world", as last call in your program).
But that's not really related to data flow.
For example, I'm currently working on a spreadsheet-style tool where the reactivity is largely being handled by SolidJS signals. It works fairly well up to a point (and that point is probably good enough for the client's needs), but it's very clear that there are big limitations here, and a more complete solution would bundle its own reactivity system. Things like computing results that spill across several cells just don't map cleanly onto conventional signals, so we instead have lots of ways to manually trigger recomputation, rather than just setting up the perfect pipeline flow. Likewise, figuring out where data loops are happening just isn't really possible.
That's not to say that SolidJS is bad for this sort of stuff - it has been great, and it's impressive how well the underlying reactive primitives work even for this project. But I think even when the underlying theory between these tools is pretty similar, the practical tradeoffs that need to be made are very different. And as a result, the different libraries servicing these different use cases will look very different.
I suspect this is the reason why these implementations are rarely extracted out more broadly. The sort of system that works well for one situation will rarely work so well for another.
Angular relied on RxJS.
There is also differential dataflow.
I feel all the ideas are related and could be combined.
What I want is a rich runtime and API that lets me fork/join, cancel, queue, schedule mutual exclusion (like a lock without a mutex), create dependency trees or graphs.
I am also reminded of dataflow programming and Esterel which a kind HN user pointed me towards for synchronous programming of signals.
This is exactly the reason to use state machines/data flows IMO.
Every implementation is unique enough that simply following how data flows through the different states and transitions, and where the sinks and funnels are, will tell you everything you need to know about what your system is actually doing at any point in time.
The challenge there is, things like that are a shitload of instrumentation and requires a lot of forethought to not just jam everything into a framework that puts boundaries on what you can design and implement. So for 99% of applications, it's not worth the hassle and you're better off with just basic text documentation.
Yes.
One of the goals for Objective-S [1] was that it should be possible to build constraints using the mechanisms of the language (so not hardcoded into the language), but then have them work as if they were built into the language.
Part of that was defining how they should look, roughly, and figuring out the architectural structure. I did this in Constraints as Polymorphic Connects [2].
For syntax, I use the symbol |= for a one-way dataflow constraint and =|= for a two-way dataflow constraint. This combines the := that we use for assignment and the | we use for dataflow. Also relates the whole thing to the idea of a "permanent assignment", which I think was introduced in CPL. The structure is simple and general: you need stores that can notify when they are changed, and a copy-element that then copies the data over. At least for one-level constraint. If you want to have multiple levels, you can
I was very surprised and happy when I discovered that I had actually figured this out, sort of by accident, when I did Storage Combinators [3]. There is a generic store that does the notifications, which you can compose with any other store. The notifications get sent to a "copier" stream which then copies the changed element. Very easy. And general, as it works for any store.
For example, I have been using this to sync up UI with internal state, or two filesystem directories. And when I added a store for SFTP support, syncing to SFTP worked out-of-the-box without any additional work. ("Dropbox in a line of code" is a slogan a colleague came up with, and it's pretty close though of course not 100%)
[1] http://objective.st (Site currently being revamped)
[2] https://dl.acm.org/doi/10.1145/2889443.2889456?cid=813164912... / http://www.hpi.uni-potsdam.de/hirschfeld/publications/media/...
[3] https://dl.acm.org/doi/10.1145/3359591.3359729 / https://www.hpi.uni-potsdam.de/hirschfeld/publications/media...
So it (a) appears to be a very useful or at least attractive concept, and (b) somehow difficult to fit into current programming languages/practice in a clean way.
[1] https://blog.metaobject.com/2014/03/the-siren-call-of-kvo-an... (HN: https://news.ycombinator.com/item?id=7404149 )
In FRP, a program is fundamentally a function of type Stream Input → Stream Output. That is, a program transforms a stream of inputs into a stream of outputs. If you think about this a bit more, you realise that any implementable function has to be one whose first k outputs are determined by at most the first k inputs -- i.e., you can't look into the future. That is, these functions have to be causal.
The causality constraint implies (with a not-entirely trivial proof) that every causal stream function is equivalent to a state machine (and vice-versa) -- i.e., a current state s, and an update function f : State × Input → State × Output. You get the stream by using the update function to produce a new state and an output in response to each input. (This is an infinite-state Mealy machine for the experts.)
Note that there is no dataflow here: it's just an ordinary state machine. As a result, the GUI paradigm that traditional FRP lends itself to the best are immediate mode GUIs. (FRP can be extended to handle asynchronous events, but doing so in a way that has the right performance model is not trivial. Think about how you'd mix immediate and retained mode to get an idea about the issues.)
When I first started working on FRP I thought it had to be dataflow -- my first papers on it are actually about signals libraries like the one in the post. However, I learned that basing it on dataflow and/or incremental computation was both unnecessary and expensive. IMO, we should save that for when we really need it, but shouldn't use it by default.
1. You seem to be confusing "dataflow constraints" with "dataflow". Though related, they are not the same.
2. Yes, the implementation of Rx-style "FRP" (should have used the scare quotes to indicate I am referring to the common usage, not actual FRP as defined by Conal Elliott) has deviated. And has deviated before. This also happened with Lucid.
3. However, the question is which of the two is the unnecessary bit. As far as I can tell, what people actually want from this is "it should work like a spreadsheet", so dataflow constraints (also known as spreadsheet constraints). This is also how people understand when used practically. And of course dataflow is also where all this Rx stuff came from (see Messerschmitt's synchronous dataflow)
4. Yes, the synchronous dataflow languages Lustre and Esterel apparently can be and routinely are compiled to state machines. In fact, if I understood the papers correctly the synchronous dataflow languages are seen as a convenient way to specify state machines.
5. It would probably help if you added some links to your papers.
It sounds like you've converted data-flow to its state-space form. It's still data flow, just in a variant that might be easier to compute.
FWIW you probably need a pair of functions :
next state = F(input, current state)
output = G(input, current state)
s = Ax + Bs
y = Cx + Ds
def f(input_stream):
i = next(input_stream)
j = next(input_stream)
yield i + j
f(input_stream)
[1] - https://developer.apple.com/tutorials/swiftui [2] - https://developer.apple.com/documentation/combine
You might be tempted to say that the lazy approach might avoid some recomputations, but if a node isn't actually going to be accessed then that node is effectively no longer live and should be disposed of/garbage collected, and so it will no longer be in the update path anyway!
The mixed push/pull approach has only once nice property: it avoids "glitches" when updating values that have complex dependencies. The pull-based evaluation implicitly encodes the correct dependency path, but a naive push-based approach can update some nodes multiple times in non-dependency order. Thus a node can take on multiple incorrect values while a reaction is ongoing, only eventually settling on the correct value once the reaction is complete.
In other push-based reactive approaches, you have to explicitly schedule the updates in dependency order to avoid such glitches, so perhaps this push/pull approach was picked to keep things simple.
In particular this is problematic if you have observable optional state that has inner observable/derived state and someone reactively reads the outer state and then it's inner if the outer one is defined.
Then you clear and dispose the outer state and at the same time set some other observable value that the inner derived depends on. With eager recomputation, it can now happen that the inner derived is recomputed, even though the inner state is disposed.
[1] https://github.com/microsoft/vscode/blob/fe9154e791eafb4f18d...
The other option is to use FrTime's approach and only update nodes in dependency order.
Goldman's Slang language has subsets of both lazily-evaluated backward-propagating dataflow graph ("The SecDb Graph") and forward-propagating strict-evaluating dataflow graph ("TSecDb"). They both have their use cases. The lazily evaluated graph is much more efficient in cases where you have DAG nodes close to the output that are only conditionally dependent upon large sub-graphs, especially in cases where you might be skipping some inputs, and so the next needed graph structure might not be known at invalidation time.
Ideally, you'd have some compile-time/load-time static strictness analysis to determine which nodes are always needed (similar to what GHC does to avoid a lot of needless thunk creation) along with some dynamic GC-like strictness analysis that works backward from output nodes to figure out which of the potentially-lazy nodes should be strictly evaluated. In the general case, the graph dependencies may depend upon the particular dynamic values of some graph nodes (the nodes whose values affected the graph structure used to be called "purple children" in SecDb, but that lead to Physics/Statistics PhDs coming to the core team confused by exceptions like "Purple children should not exist in subgraph being compiled to serializable lambda")
TSecDb already contains a similar analysis to prune dead code nodes from the dataflow DAG after the DAG structure is dynamically updated. (For instance, when a new stock order comes in, a big chunk of TSecDb subgraph is created to handle that one order, and the TSecDb garbage collector immediately runs and removes all of the graph nodes that can't possibly affect trading decisions for that order. This also means that developers new to TSecDb often get their logging code automatically pruned from the graph because they've forgotten to mark it as a GC root (TsDevNull(X))... and it's pretty bad logging code if it affects the trading decisions.)
Risk exposure calculations (basically calculating the partial derivatives of the value of everything on the books with respect to most of the inputs) are done mostly on the lazy graph, and real-time trading decisions are done mostly on the strict graph.
Seems like the trouble here is you'll have to traverse the tree every time to check timestamps but if the dependency is dirty that needs to happen anyway.
If you only updated 1 node, a push-based system will only update nodes that have changed, which will be considerably less (likely linear in depth). For instance, consider:
var evenSeconds = clock.Seconds.Where(x => x % 2 == 0);
var countEvents = evenSeconds.Count();
var minutes = clock.Seconds.Count(x => x / 60);
var hours = minutes.Count(x => x / 60);
In a push-based system, clock.Seconds would trigger seconds+1. If that's not even, propagation stops there, if it is even then this updates evenSeconds, which would then trigger an update for countEvents. Ditto logic for minutes and hours.
You can see the push-based system permits minimal state changes via early termination if downstream dependents won't see any changes.
I use it on every site except a select foew that have beetter Stylus UserStyles.
HN happens to be one i use a custom stylesheet for.
I maintain a reactive, state management library that overlaps many of the same ideas discussed in this blog post. https://github.com/yahoo/bgjs
There are two things I know to be true:
1. Our library does an amazing job of addressing the difficulties that come with complex, interdependent state in interactive software. We use it extensively and daily. I'm absolutely convinced it would be useful for many people.
2. We have completely failed to convince others to even try it, despite a decent amount of effort.
Giving someone a quick "here's your problem and this is how it solves it" for reactive programming still eludes me. The challenge in selling this style of programming is that it addresses complexity. How do you quickly show someone that? Give them a simple example and they will reasonably wonder why not just do it the easy way they already understand. Give them a complex example and you've lost them.
I've read plenty of reactive blog posts and reactive library documentation sets and they all struggle with communicating the benefits.
As an aside, "complex, interdependent state" is possibly one of the few areas that lend themselves naturally to visual programming (which is a fail in the general programming case). Why not just draw graphs?
> I've read plenty of reactive blog posts and reactive library documentation sets and they all struggle with communicating the benefits.
I just googled 'visual programming for reactive systems' and this (interesting project) turned up:
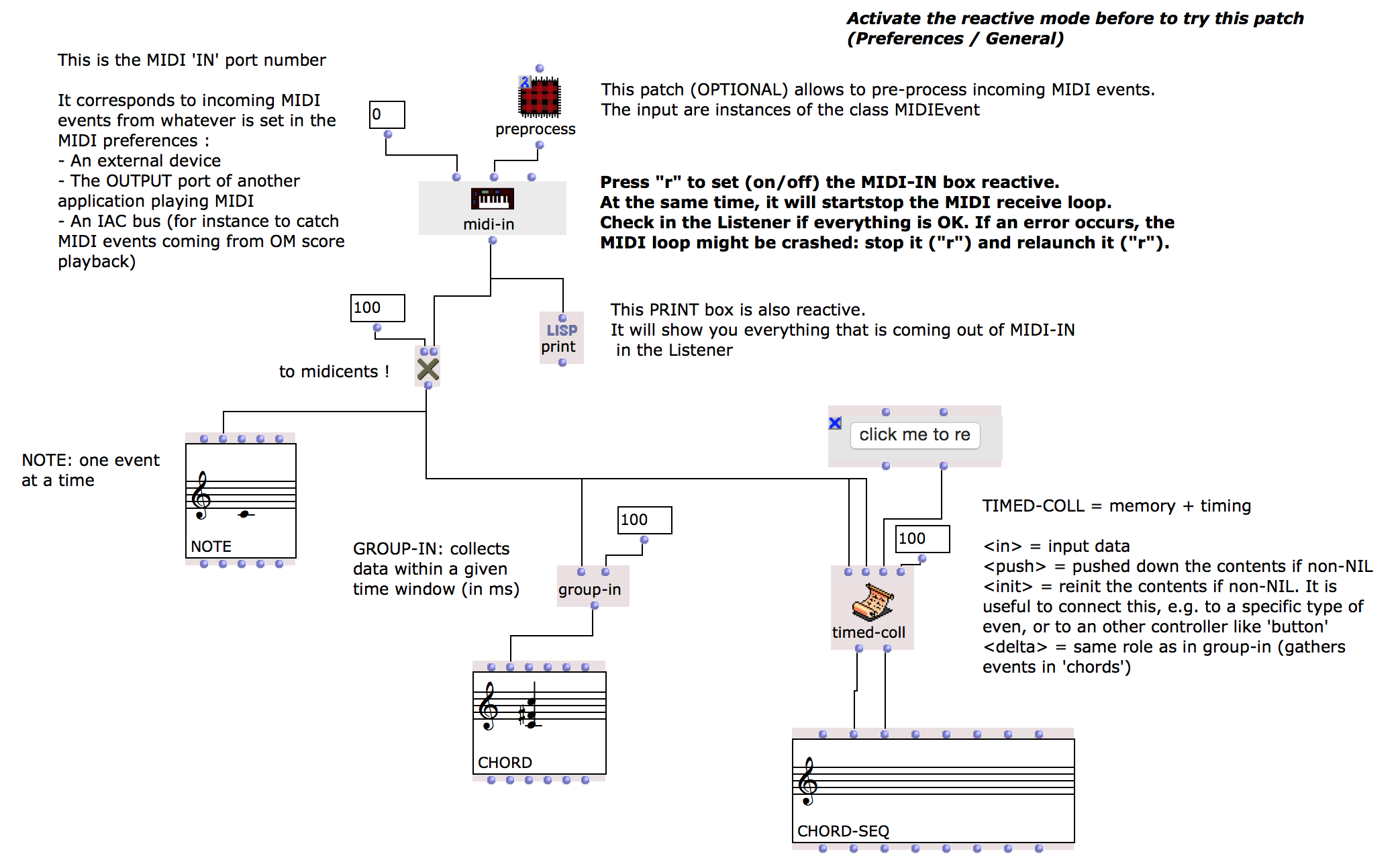
https://openmusic-project.github.io/openmusic/doc/reactive.h...
So the approach is specifically addressing complex interaction patterns between components. To highlight the solution, just do what these guys did: here you can see the benefit of 'reactive components' just by looking.
https://openmusic-project.github.io/openmusic/doc/images/mid...
(2c - good luck w/ the project)
That being said, we do often consider renaming them and other parts to feel more mainstream reactive. But honestly, I secretly suspect that fiddling with names won't make a difference to anyone.
I do also agree that there is some appeal to visual programming paradigms. It's pretty easy to look at the examples you linked to and get some quick sense of understanding. But those typically work well when there are a handful of nodes and edges. The software we maintain at work can have 1000's of nodes at runtime with more than 10000 edges. There's no visual representation that won't look like a total mess. Whatever their faults, text based programming languages are the only approach that have stood up at scale so far.
So our library is just a normal programming library. You can use standard javascript/swift/kotlin to write it.
Thanks for your feedback! :)
function onLoginClick() { validateFields(); networkLogin(); updateUI(); }
My goal with that example was to point out how there are implicit dependencies between validateFields() and networkLogin() and updateUI(). They need to be called in the correct order to make the program work. Our library makes those dependencies explicit and calls things for you. It's not a big deal when we have a 3 function program. But when we have dozens or hundreds of interdependent instances of state, those implicit dependencies become a real struggle to navigate.
Now we're convinced our library works well. We use it every day. But it's also very reasonable for you to be skeptical. As you say, there's cognitive load. As a potential user, you would need to spend your time to read the docs, try a few out ideas, and understand the tradeoffs. That's a lot of work.
I'm glad you took a look at the project, though. The fact that we've failed to make a case for it is certainly on us. Which gets back to my original point. I don't know how to sell a solution to complexity.
If ease of use is targeted, signals might not be the best approach. I distinctly remember things becoming easier when they went away.
I find the biggest benefit of using a fringe library like this is the ability to read and understand the whole implementation. It's really simple compared to something like React.
Furthermore, towards the end of one of the videos, the checkmark seems to turn from green to gray and back to green again with a single click.
[1]: https://docs.racket-lang.org/gui-easy/index.html
[2]: https://www.youtube.com/watch?v=7uGJJmjcxzY
[3]: https://github.com/Bogdanp/racket-gui-easy/blob/364e8becaafa...
Used in some places to simplify RxJs or not need it at all. Some, not all.
They are looking towards a future where they can get rid of Zone.js and its strategry to change detection. I see this as a step along that part.
Heck even in lisps there was reagent which was basically this and had atoms/signals :)
{kind=link}