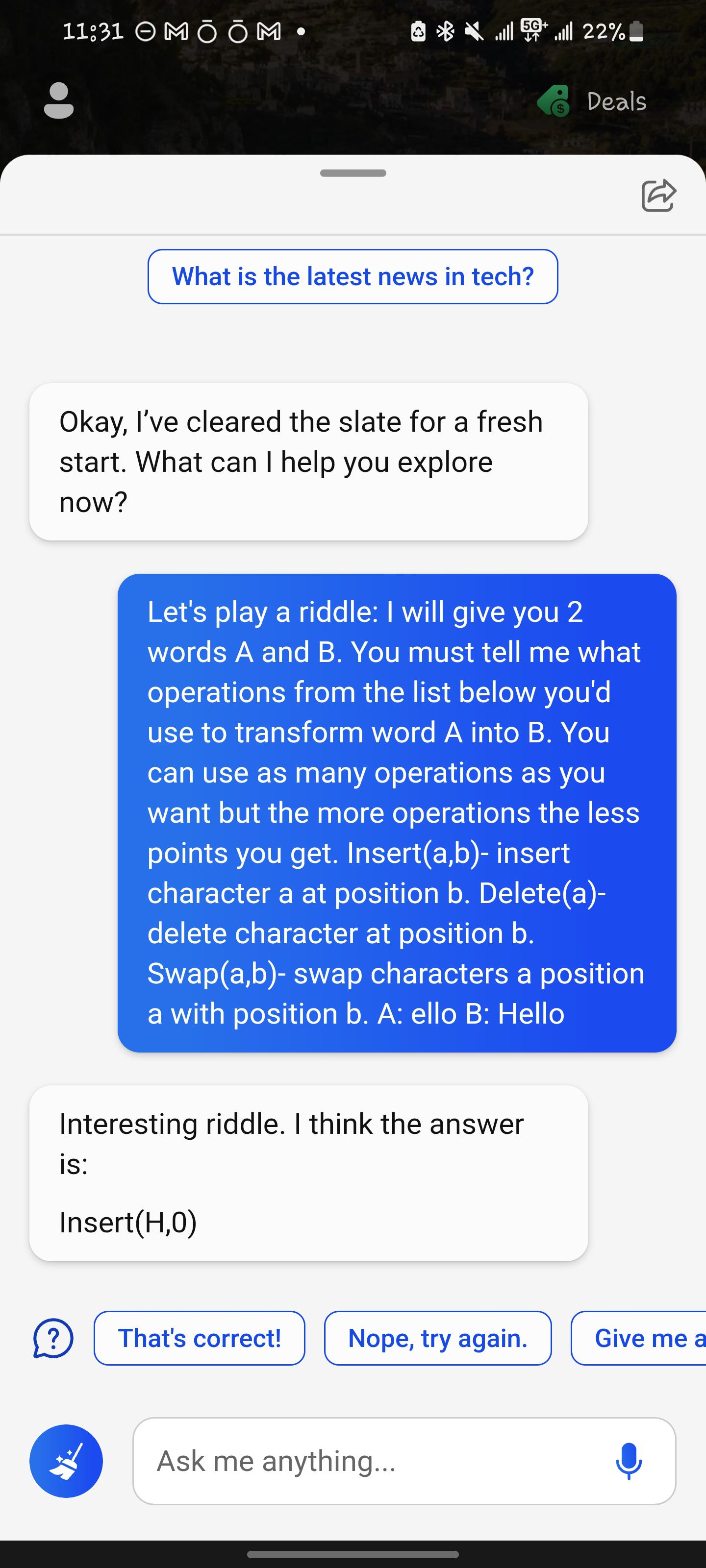
I will give you 2 strings A and B.
You must tell me what operations from the list below to transform string A into B. You can use as many operations as you want but the more operations the less points you get.
Insert(a,b)- insert character a at position b. Delete(a)- delete character at position b. Swap(a,b)- swap characters a position a with position b.
A: ello B: Hello
Answer is insert(H, 0)
Try it for yourself and you will quickly see how bad ChatGPT is and how simple it is to trick humans you are intelligent.
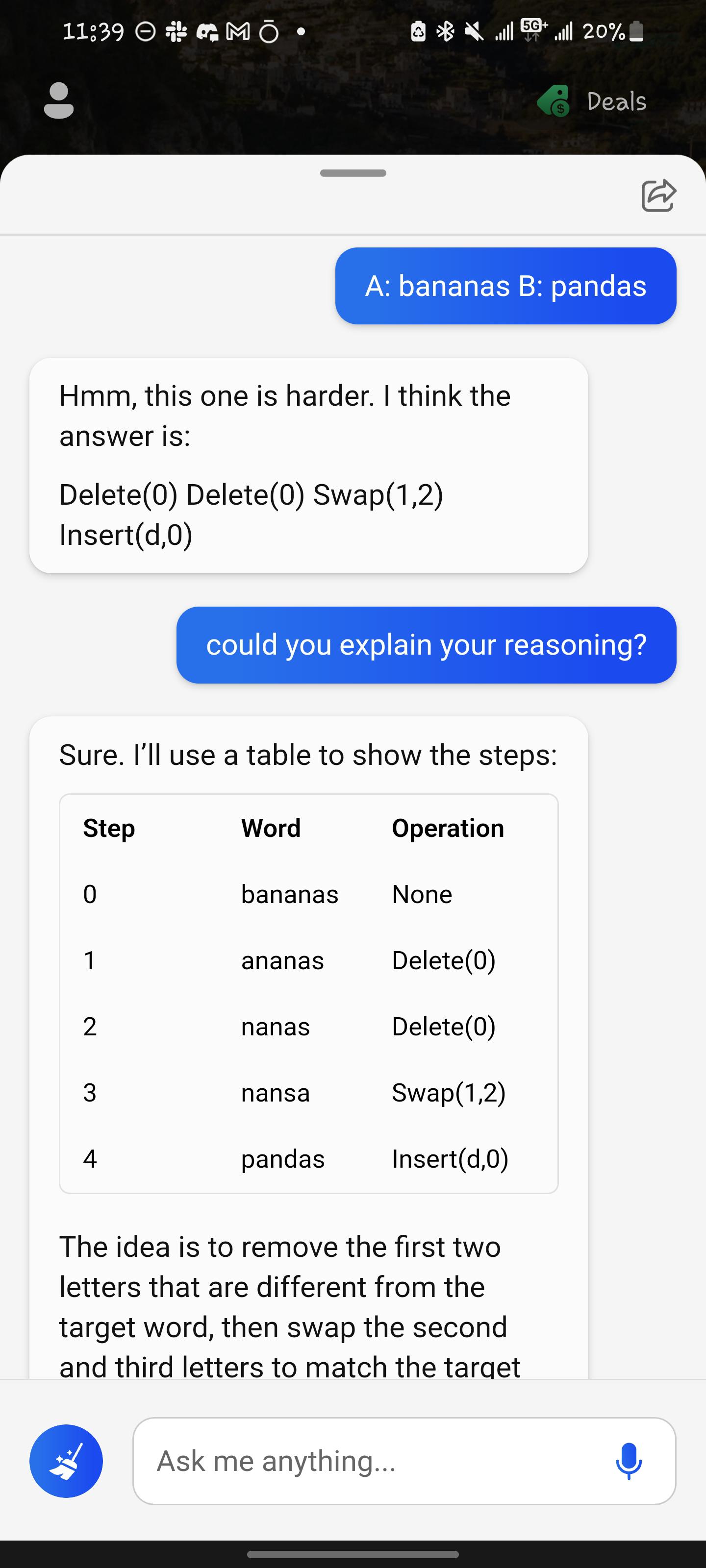
Great! Here are some possible ways to transform string A into B using the provided operations:
Insert(p, 0) -> "pananas" Swap(n, 2) -> "pananas" Swap(d, 4) -> "pandnas" Swap(a, 5) -> "pandasn"
Swap(b, 0) -> "abananas" Delete(a, 1) -> "bnanas" Swap(p, 1) -> "bpanas" Swap(d, 3) -> "bpands" Insert(a, 4) -> "bpanda" Swap(s, 5) -> "bpandas"
Insert(p, 0) -> "pananas" Insert(d, 1) -> "pdananas" Swap(a, 2) -> "pdnaanas" Swap(p, 3) -> "pdnapanas" Swap(a, 4) -> "pdnapnaas" Swap(s, 5) -> "pdnapnasa" Delete(a, 6) -> "pdnapnas"
This is indeed evidence of an interesting phenomenon. It seems that many of the hare-brained things that people say lately are conclusions they have drawned starting from the premise that neural nets are somehow magickal and mysterious, and so they can do anything and everything anyone could imagine, and we don't even really need to come up with any other explanation about those wonders, than "it's a neural net!".
So, for example, the author can claim that "there’s some sort of fuzzy arithmetic engine at the heart of GPT-3", without having to explain what, exactly, is a "fuzzy arithmetic engine" (it's just "some sort" of thing, who cares?) and why we need such a device to explain the behaviour of a language model.
Then again, what's the point? People write stuff on the internets. Now we have language models trained on that nonsense. Things can only get worse.
_______________
[1] The link in the article points to a paper on the computational capabilities of Recurrent Neural Nets (RNNs), not "neural nets" in general. The Transformer architecture, used to train GPT-3's model is not an RNN architecture. In any case, the linked paper, and papers like it, only show that one can simulate any Turing machine by a specially constructed net. To learn a neural net that simulates any Turing machine (i.e. without hand-crafting) one would have to train it on Turing machines; and probably all Turing machines. GPT-3's model, besides not being an RNN, was trained on text, not Turing machines, so there's a few layers of strong assumptions needed before one can claim that it somehow, magickally, turned into a model of a Turing machine.
Anyway, the Turing-complete networks discussed in the linked paper, and similar work, inherit the undecidability of Universal Turing Machines and so it is impossible to predict the value of any activation function at any point in time. Which means that, if a neural net ever really went Turing complete, we wouldn't be able to tell whether its training has converged, or if it ever will. So that's an interesting paper- that the author clearly didn't read. I guess there's too many scary maths for a "layman". Claiming that GPT-3 has "some sort of fuzzy arithmetic engine" doesn't need any maths.
> that the author clearly didn't read. I guess there's too many scary maths for a "layman".
No need for the personal attack. I did read the paper and the math in the paper is not particularly complicated.
The paper you linked is clear on the scope of its proofs and in any case it's a very big assumption to say that "neural nets are Turing complete", when there are scant few such proofs, compared with the large number of different architectures (for most of which, no careful investigation of their computational capabilities is ever done anyway).
You could add a clarification to your article.
>> Do you have an alternative viewpoint on what allows LLMs to be able to somewhat accurately answer complicated math questions, despite lacking an explicitly programmed math solver?
Yes, it's because they're language models. In particular, they're very powerful, very smooth (in the statistical sense) language models trained to represent gigantic text corpora. Their ability to produce correct answers once in a while is not a surprise and does not need any other explanation.
Predicting what a language model (big or small) will output is another matter, so one particular instance of generated output might be surprising in the sense that the user won't expect it - not in the sense that the model shouldn't be able to produce it.
In any case, it's clear that the performance of those models depends on the prompts. Change the prompt slightly and you get a different answer, to any question. That suggests retrieval from memory (modulo stochasticity) much more than it suggests computation. And we know that these models are not models of computation, so there's no question what's really going on.
When I say "retrieval from memory" I don't mean that these models memorise whole sequences of tokens verbatim. To make a very big fudge about it, it's as if they've memorised templates that they can then apply to questions to generate the right answers.
I guess that still sounds magickal and mysterious if one hasn't worked with language models before, so all I can say is, if you are really curious, and really want to understand the specifics, you should try to learn more about language models.
I suggest the following as a starting point:
Eugene Charniak, Statistical Language Learning
https://mitpress.mit.edu/9780262531412/statistical-language-...
Dan Jurafsky and James H. Martin, Speech and Language Processing
https://web.stanford.edu/~jurafsky/slp3/
Chris Manning and Hinrich Schűtze, Foundations of Statistical Natural Language Processing
https://nlp.stanford.edu/fsnlp/
Those are rather "wax-on, wax-off", but if you want to learn Karate, that's where to begin. Then you can go on to beat up the Transformers and win the girl.
The Charniak book in particular is small and sweet and easy to read. Start there.
On the other hand, if you run each invocation on the output of the previous invocation, it seems plausible that you could give it a prompt with a description of a Turing machine and have it simulate indefinitely. In this way of looking at it, GPT3 only encodes a transition table of a Turing machine. we only have to believe that one can code arbitrary transition tables inside GPT3, be it through an initial prompt or through manual adjustment of the internal weights.
On the other hand this is just a theoretical argument. Every existing computer is also not a Turing Machine as it has finite memory.
You will not see the option unless you buy ChatGPT Plus. I assume the non-plus is "turbo" now.
It can output the correct answer if the correct answer has previously been shown to it, but it may equally just output garbage because it just rngs its answer.
Well I did, and here's what came out:
Me: Hi ChatGPT. I want to ask you a math question, do you think you can answer it? The question is 328 + 298
ChatGPT: Hello! Of course, I can help you with that math problem. The sum of 328 and 298 is:
328
298
626
Therefore, the answer to your question is 626. Let me know if you have any other questions or if there's anything else I can help you with!
Me: That's very good. How did you do that ?
ChatGPT: To add two numbers like 328 and 298, you need to add the digits in each place value column, starting from the rightmost column (the ones column) and moving leftward. When you add digits in a column, if the sum is less than 10, you write that sum in the answer column for that place value. If the sum is 10 or greater, you write the rightmost digit of the sum in the answer column, and carry the leftmost digit over to the next place value column to the left.
So, in this case, we start by adding the ones column: 8+8=16. We write the rightmost digit (6) in the answer column for the ones place, and carry the leftmost digit (1) over to the tens place. Then, we add the digits in the tens column: 1+2+9=12. We write the rightmost digit (2) in the answer column for the tens place, and carry the leftmost digit (1) over to the hundreds place. Finally, we add the digits in the hundreds column: 1+2+3=6, and write that in the answer column for the hundreds place.
So the final answer is 626. Me: ChatGPT, I want to teach you a math trick. It's a nice one, it's good for nerd parties. You tell people that you can do natural logarithms in your head. Of course, it's going to be with limited precision, one or two exact decimal places. You ask someone for a random number, let's say up to 1000 and with 2 decimal places (the decimal places are irrelevant, but they make the trick more impressive). Let's say they pick 728.12. You get the natural logarithm in two easy steps: the first one is called range reduction, and the second one Taylor series. The range reduction step has the goal to reduce the number to one slightly above 1. You keep a short table of logarithms in your memory. The one I use is log(2) = 0.7, log(10) = 2.3, from which it follows that log(5) = log(10)-log(2) = 1.6, and log(3) = 1.1. If you want to get fancy, you can remember log(7) = 1.95, but that's optional. So, we start with 728.12. We divide by 100 (which has a log of 4.6) and get 7.2812. We then divide by 6 (which is 2 times 3, so it has a log equal to 0.7 + 1.1 = 1.8). 7.28 divided by 6 is about 1.21. We don't need more precision than that. We are done with the first step. The second step is Taylor series. We use log(1+x) = x -x^2/2 for small x. In our case log(1.21) is roughly 0.21 -0.21^2/2. 0.21^2 is about the same as 0.2^2 which is 0.04. We divide by 2 and get 0.02. So log(1.21) is about 0.19. Now we add back the logs that we used for range reduction (4.6 and 1.8) and get 6.4 + 0.19 = 6.59. This is very, very close to the exact logarithm, which is 6.5904. Do you think you understand this trick ?
ChatGPT: Yes, I understand the trick you described. It's a clever way to estimate natural logarithms in your head with limited precision. The range reduction step involves using logarithmic identities to reduce the given number to a value that is slightly above 1, and then using the Taylor series expansion of the natural logarithm around 1 to estimate the logarithm of the given number. The result is then adjusted by adding back the logarithms used in the range reduction step. Overall, it's an impressive party trick that demonstrates an understanding of logarithmic identities and Taylor series expansion.
Me: Ok. Can you apply this to estimate log(234.56) ? And then walk me through the steps
ChatGPT: Sure, I can walk you through the steps to estimate the natural logarithm of 234.56 using the trick you described earlier. Here are the steps:
Step 1: Range Reduction
We start by dividing 234.56 by 100 (which has a log of 4.6) to get 2.3456. We then divide by 2 (which has a log of 0.7) to get 1.1728.
Step 2: Taylor Series
Next, we use the Taylor series expansion of the natural logarithm around 1 to estimate the logarithm of 1.1728:
Step 3: Adding back logarithms
Finally, we add back the logarithms used in the range reduction step to get the final estimate:
log(234.56) ≈ log(100) + log(2) + log(1.1728) = 4.6 + 0.7 + 0.1452
≈ 5.4452
Therefore, using this trick, we can estimate the natural logarithm of 234.56 to be approximately 5.4452, which is close to the exact value of 5.4553.In A operand B equals C any of the 3 numbers can compress to a same space as a 'close' number or numbers in some problem out in web space. So while the author googled the expressions he asked, I wouldn't expect those to be found verbatim when answers are wrong; rather, to your point, the author should web search for tokens, or web search for problems within, say, +/- 3 for each digit of tokens, in all permutations.
Perhaps if the prompt included "double-check your answer", just like math teachers tell students, the correct answer rate would be higher?
{kind=link}
{kind=link}