We deploy TiDB in three available zone(AZ) in one region in AWS. Each AZ contains a SQL computing server, and a columnar storage replica server, sometimes the computing server will send request to the replica server in another region and get the data result, if the data acquisition volume is high, this will cost us much money. Unfortunately, we only found out about this when we received the bill from AWS. After that, We start optimizing the size of the transferred data :sob:
- We used gRPC with no compression before, and we tune an acceptable compression level to achieve a balance of performance and data volume.
- Improve our SQL optimizer to consider the network cost more accurately and data placement rule to balance data more logically to reduce data transfer crossing AZ.
- As a cloud service, we will also expose the cost transparently to our customers like MongoDB Atlas does. :-)
We didn't pay attention to the cost of crossing AZ before, just thought this might be cheap. Of course, we were wrong :sob:
But would anyone think of the bit flips?
> We've now determined that message corruption was the cause of the server-to-server communication problems. More specifically, we found that there were a handful of messages on Sunday morning that had a single bit corrupted such that the message was still intelligible, but the system state information was incorrect.
> We use MD5 checksums throughout the system, for example, to prevent, detect, and recover from corruption that can occur during receipt, storage, and retrieval of customers' objects. However, we didn't have the same protection in place to detect whether this particular internal state information had been corrupted. As a result, when the corruption occurred, we didn't detect it and it spread throughout the system causing the symptoms described above. We hadn't encountered server-to-server communication issues of this scale before and, as a result, it took some time during the event to diagnose and recover from it.
https://web.archive.org/web/20150726045623/http://status.aws...
See also: At scale, rare events aren't rare, https://news.ycombinator.com/item?id=14038044 (2017).
Even “medium” VMs can get gigabytes per second of throughout..
Within DCs, sure. At the same time, a lot more company networks become spread thin over 4G/5G networks and finicky cable ISPs in recent years with WFH.
This caused quite a strain on internal LOB apps which could reasonably assume zero packet loss and sub-1ms LAN latency beforehand :)
Software engineering is not a mature field but microservices feels like a dead alley everyone is marching on.
These seem swapped.
“A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.” — Leslie Lamport
Each failure scenario must be gracefully handled in each subpart to take into account all possible impact on the whole system.
You'll always get a random crap you never heard of destroying an assumption you made in your own crap.
I remember an instance where a national mobile phone provider in France got a single db outage but during a large sms day (think new year), so the failover happened but totally overloaded the new servers, and it created a chain reaction to other providers to a point you couldnt read your email for a day or two because of inability to get smses. Why is that random db in a provider I dont even use impacting my google account ? Because the system is distributed.
After watching Lamports introduction to TLA+, I got the impression he's just a really funny guy (while being a genius, too).
- Servers/applications never restart
- Startup order is fully deterministic
- All instances run the same software revision (maybe somewhat covered by 8)
- Hardware is reliable
- All clients are playing nicely along (and I'm not even talking about attacks)
- Logging and metrics are cheap
- There are no software bugs in any layer
It still is for the minority of systems.
On single OSs Google runs an init that is deterministic; as do the BSDs and some distributions of Linux.
For distributed systems your ops team controls for this; usually on the service discovery layer. (Don’t publish until ready, don’t start service until you can establish a connection to required endpoints).
e.g. let's take the example of an init system starting up all processes. Now what happens if a if one of the processes crashes and gets restarted by a processmanager? Now the order already changed, and e.g. a former process which relied on the restarted one might work based on outdated data. Similar things can also happen on other layers - e.g. one of the services in a dependency chain might disappear and reappear.
Another example is a developer/administrator manually changing the config of a certain service and restarting it to take effect - that could also trigger dependency problems.
Now those are absolutely solvable - either by making sure all services operate gracefully with any startup order or by other mitigations (e.g. "always reboot the full box"). But like everything else in the list, it still is a problem that is observed in very often in distributed systems.
Much better to lose a node immediately than to have it fail gradually.
- Amazon S3 design requirements and principles (2006), https://archive.is/EP6HU#selection-1205.0-1425.66
- Amazon S3: Architecting for resiliency (2009), http://web.archive.org/web/20100719163331/https://qconsf.com...
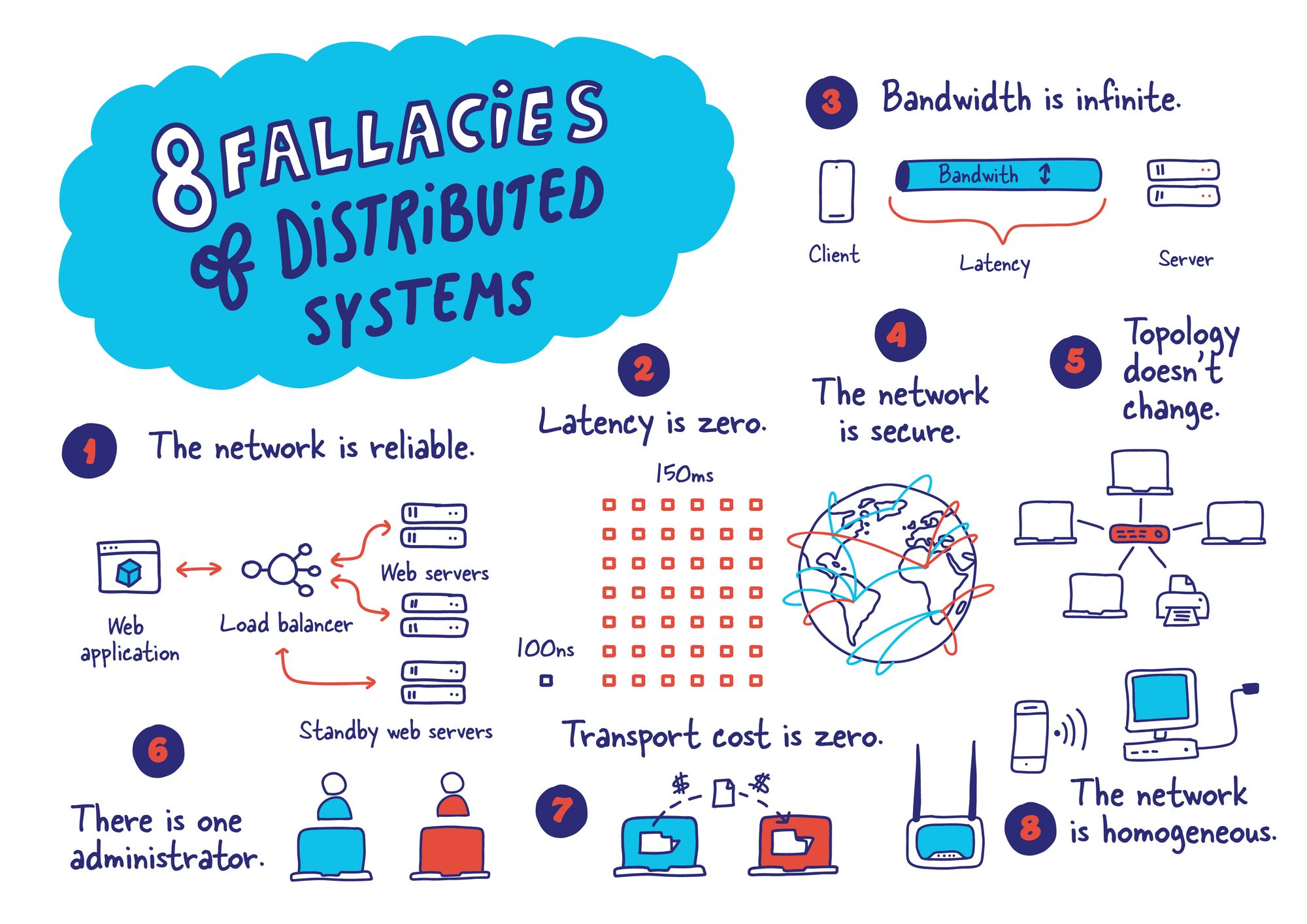
http://deniseyu.io/art/sketchnotes/topic-based/8-fallacies.p...
* https://cacm.acm.org/magazines/2014/9/177925-the-network-is-...
Discussions here:
https://en.m.wikipedia.org/wiki/Fallacies_of_distributed_com...
https://en.wikipedia.org/wiki/Fallacies_of_distributed_compu...
"oh, today the underlying layer decided to wait 1min30 for a timeout",
"oh, the DNS resolution is broken",
"no route to host???",
"invalid certificate, did somehone hijack the DNS query?"
"this library decided to wrap the errors, now I have learn an entire new vocabulary of failure modes"
Of course coordinating threads is difficult.
I am designing an LMAX disruptor system that translates a synchronous piece of code into nested LMAX disruptors.
Essentially you can do high IO and high CPU and not block other requests as they're pipelined.
https://github.com/samsquire/ideas4#51-rewrite-synchronous-c...
Don't block the UI thread or the node js event loop. We don't have to pick between tokio and rayon. We can have multiple event loops.
{kind=link}
{kind=link}