I created a few years ago a successful open source AKHQ project: https://github.com/tchiotludo/akhq (renamed from KafkaHQ) which has been adopted by big companies like Best Buy, Pipedrive, BMW, Decathlon and many more. 2300 stars, 120 contributors, 10M docker downloads, much more than I expected.
Now let's talk about Kestra, an infinitely scalable orchestration and scheduling platform for creating, running, scheduling and monitoring millions of complex pipelines.
I started the project 30 months ago and I'm even more proud of this project that required a lot of investment and time to build the future of data pipelines (I hope). The result is now ready to be presented and I hope to get some feedback from you, HN community.
To have a fully scalable solution, we choose Kafka as our database (of course, I love Kafka if you didn't know) as well as ElasticSearch, Micronaut, ... and can be deployed on Kubernetes, VM or on premise.
You may think there are many alternatives in this area, but we decided to take a different road by using a descriptive approach (low code) to build your pipelines allowing to edit directly from the web interface and deploy to production with terraform directly. We paid a lot of attention to the scalability and performance part which allows us to have already a big production at a big French retailer: Leroy Merlin
Since Kestra core is plugin based, many are available from the core team, but you can create one easily.
More information: - on the official website: https://kestra.io/ - on the medium post: https://medium.com/@kestra-io/introducing-kestra-infinitely-... - check out the project: https://github.com/kestra-io/kestra
Your comments are more than welcome, thank you!
… but your core dependencies are a Kafka cluster and an elastic search cluster which are both a pain in the ass to scale; so really, could you run this seriously without a really expensive hosted cloud instance of both of those?
This kind of wording:
> Since the application is a Kafka Stream, the application can be scale infinitely
Is a major turn off to me.
Kafka cannot scale infinitely. Nothing can. In fact, Kafka can be a pain in the ass to scale.
In makes me question some of the other commentary on the project.
> Kafka cannot scale infinitely. Nothing can.
It is very common that when a phrase can't be literally true, it signals a metaphorical meaning. E.g., if a teen tells you their new teacher is a million years old, it's not a literal statement of age. Similarly, nobody expects "scale infinitely" to mean that, as in Universal Paperclips, that we'll be converting whole galaxies into Kestra clusters. It means that any bottlenecks are external to the system.
I disagree. I've worked with plenty of people that would probably take this statement at face value and assume you could scale to a completely arbitrary amount of load with no marginal effort.
Plus, there's a difference in context here: we're talking about a technical product. It doesn't hurt to be precise and technical in your description of it, does it? This is the most likely setting in which someone might interpret something literally.
I do agree there's a difference in context, but for me it goes the other way. I'd expect pretty much anybody in a technical audience to know technical basics. For me that's a big part of the fun in writing on HN, in that it's not obligatory to dumb my points down just to coddle the clueless.
I agree with you that Kafka & ElasticSearch can be a pain to scale if you need to have a horizontal and vertical scaling.
On other side, on single machine, it's really has easy to setup. With this, you will have the same scaling than Airflow for exemple since it depend on a non scalable database (mysql or postgres). But the chance you will have with Kestra is that you will be able to scale to multiple node for your backend (as well with kestra that allow scaling all services). When you hit the limit with standard database, you will be stuck.
And yes clearly infinite scale is not a literal statement terms, nothing can scale infinitely but since the architecture is really robust (and scalable), the issues will be on other aspects than Kestra (cloud limit, database overload, ...).
A final point and a more important one, the backend are all pluggagle in Kestra since Kestra is really think as module: Look at the directory here : https://github.com/kestra-io/kestra :
- runner-kafka & runner-memory are 2 implementation of Kestra, you can add a new one that will use Redis, Pulsar, ...
- repository-elasticsearch & repository-memory is the same, you can implement another one, I started one implementation for JDBC that I don't have the time to finish for now : https://github.com/kestra-io/kestra/pull/368
Both are AWS hosted products (RDS, AWS Elasticsearch).
Better to compare how complex they are to scale in terms of actions required.
Just don't go multiple node if not needed by the project. But when you will need to, with Kestra you can go multiple node and scale.
For other workflow engine (dagster, prefect, ...), we decided to use a complete different approach on how to build a pipeline. Since others decide to use python code, we decided to go to descriptive language (like terraform for example). This have a lot of advantages on how the developer user experience is: With Kestra, you can directly the web UI in order to edit, create and run your flows, no need to install anything on the user desktop and no need a complex deployment pipeline in order to test on final instance. Other advantage is that it allow to use terraform to deploy your flows, typical development workflow are: on development environment, use the UI, on production deploy your resource with terraform, flow and all the others cloud resource.
After, it will be really nice to have some independent performance benchmark. I really think Kestra is really fast since it was based on a queue system (Kafka) and not a Database. Since workflow are only events (change status, new tasks, ...) that is need to be consume by different service, database don't seems to be a good choice and my benchmark show that Kestra is able to handle a lot of concurrent tasks without using a lot of CPU.
AirFlow 2 is designed to support larger XCOM messages, so the guidance to only use it for small data no longer applies.
Your DAG construction overhead issue is likely due to dagbag refreshing. Airflow checks for DAG changes on a fixed interval, causing a reimport. The default period for that is fairly small, so for large deployments you will want to use a larger period (e.g. at least 5 minutes). I do not know why the default is so short (or was last I checked, anyway). Python files shouldn't do much of note on import regardless IMO.
I am not otherwise familiar with the improvements in Airflow 2, so I cannot say for sure if your other complaints still remain.
The performance issue is still here, just launch Airflow and submit thousand dagruns with simple python sleep(1) and you will hit the cpu bound very quickly with a total time that will have a large duration. Airflow is not designed for a lot of short duration tasks. When using event driving data flow, it's really complicated to managed.
Imagine a flow that will be triggered for each store for example (thousand of store, with 10+ tasks for each one), Airflow will not be able to manage this kind of workflow quickly (and it's not its goals). Airflow was clearly defined to handle small (hundreds tasks) for a long time.
For the XCOM part, Airflow store this in database, so you can't store data into this, you will need to store a small data (database is not here to store big files). In Kestra, we have a provide a storage that allow storing large data (Go, To, ...) between tasks natively with the pain on multiple node clusters.
Is there a way to use this as a managed service?
Are you looking for independent partners/integrators?
In a meantime, we provide different installation : - Docker compose: https://kestra.io/docs/administrator-guide/deployment/docker... - Kubernetes: https://kestra.io/docs/administrator-guide/deployment/kubern... - Jar: https://kestra.io/docs/administrator-guide/deployment/manual...
Kestra is not so complicated to be installed, for Kafka and Elasticsearch, you could use Amazon managed service or Aiven for example.
But be sure that we will provide a managed service as soon as possible
What's your position on other companies providing managed service of your project?
We do deployment, security, remote backups, vm snapshots, monitoring/alerts, automated OS & Software updates, and much more. We launched few weeks ago here on HN
There is a free trial, so you can start and get a working instance of Kestra in less than 5 minutes. Let me know what you think :)
In resume, all image exist with tag full containing all plugins
I see partial structures and then JSON string as is and then some long blob of string no one can understand what it is with no new lines.
What devs want are pretty simple, structured log with table layout without repeating the column names on every row to make it look insanely verbose for any human to consume.
I'm picking up bits of open source apps to build a decent solution with Vector (which has awesome Vector remap language to parse strings into structured data if it isn't already) and throw it into ClickHouse to view it from Metabase.
Apparently, Kibana, Graylog or even Grafana are pretty bad at displaying logs to even feel tiny comfortable reading it every day.
Logging is such a crucial part of developer life and not sure why that there aren't any sane open source solutions.
It's not as json ? or I don't understand where you see that.
It can look a bit better with more config for these 3 other tools but these are pretty much what they're and the readability isn't any better than tail/grep.
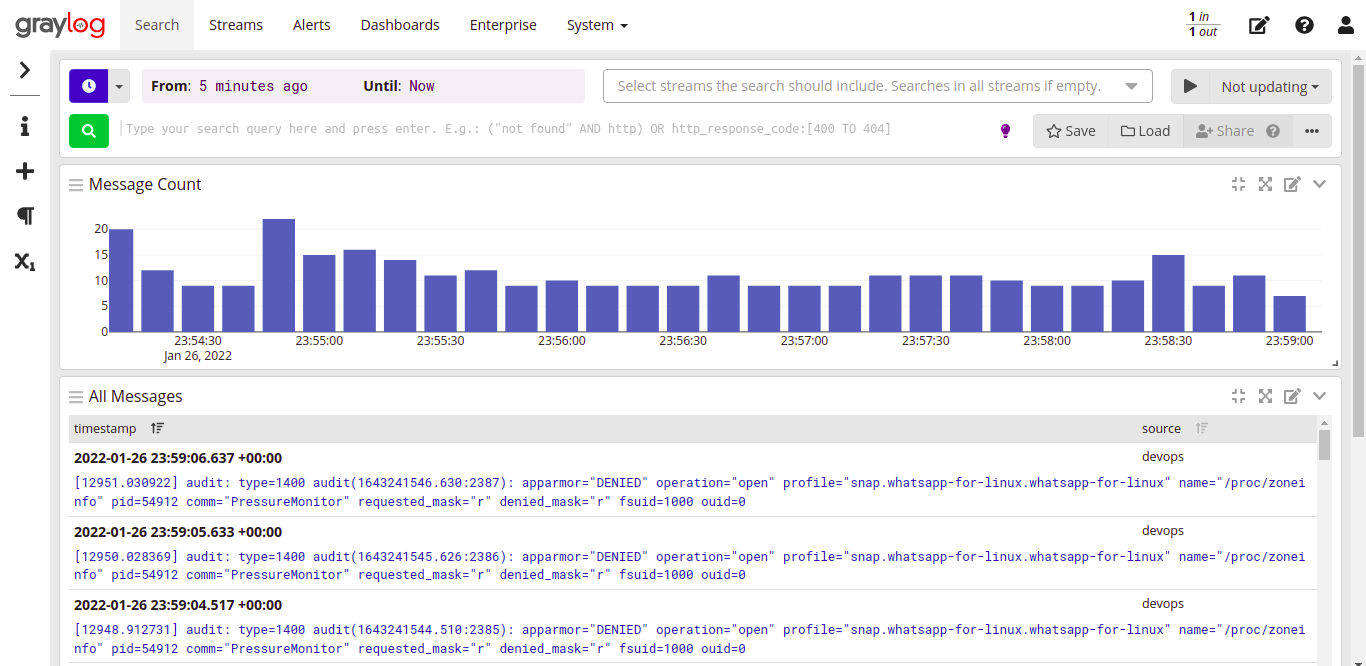
- Graylog : https://adamtheautomator.com/wp-content/uploads/2022/02/imag...
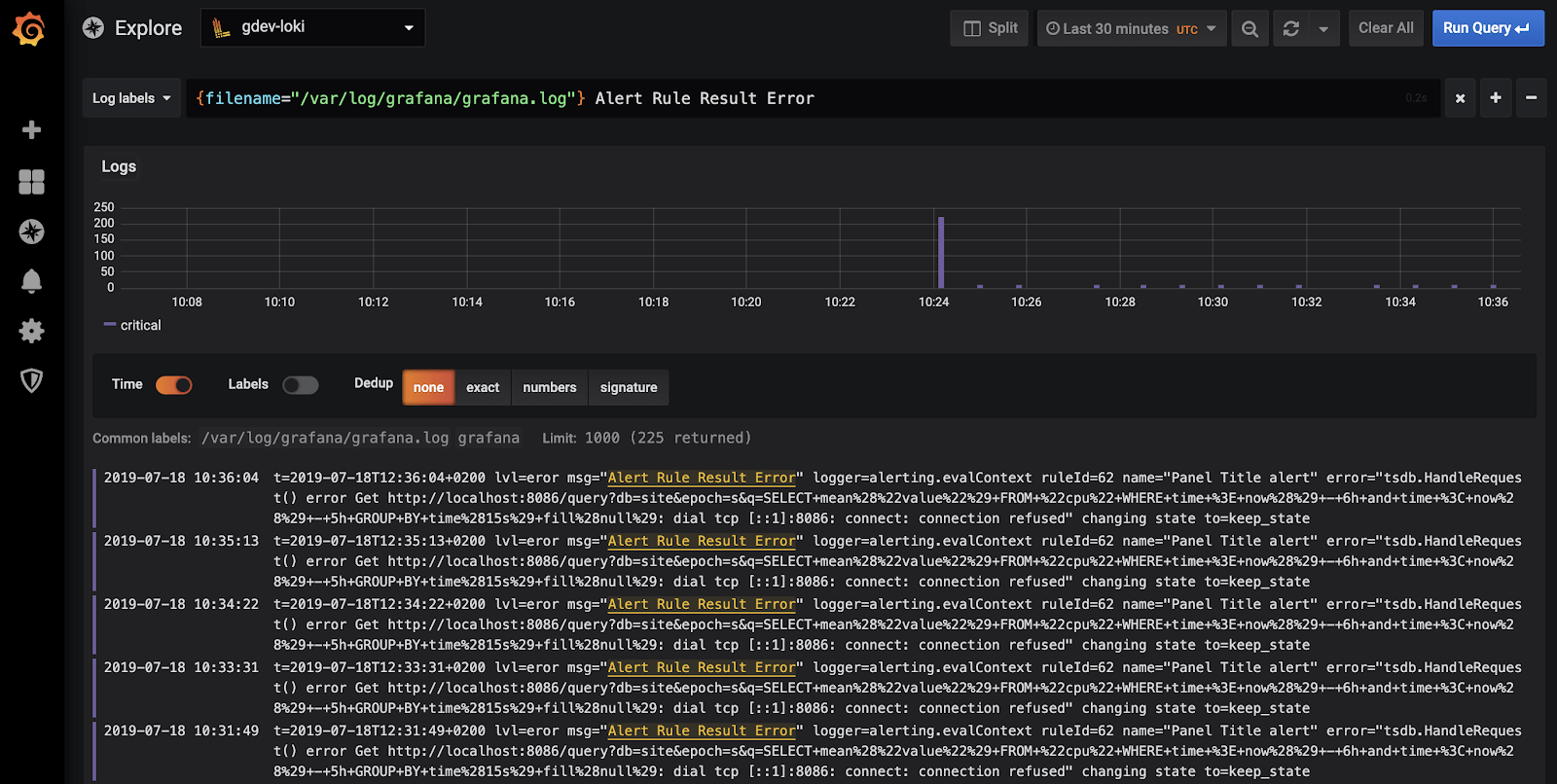
- Grafana : https://grafana.com/static/assets/img/blog/logcontext_explor...
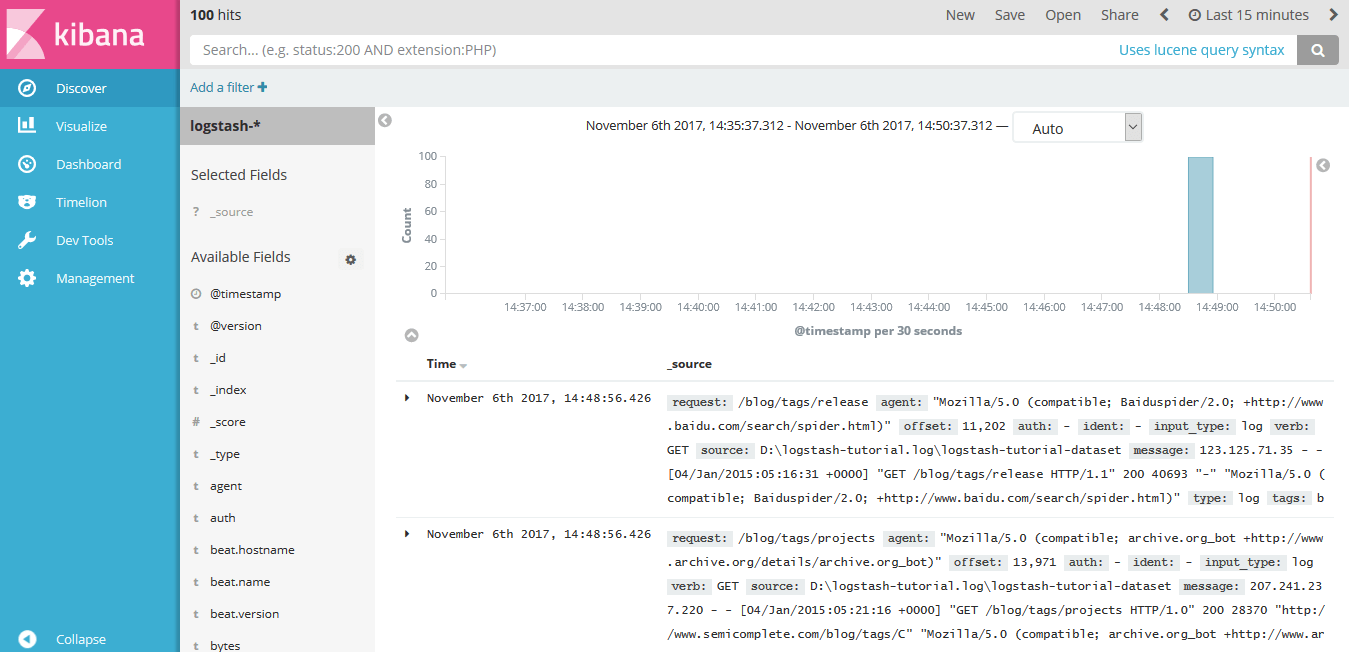
- Kibana : https://blog.ip2location.com/wp-content/uploads/2018/12/logs...
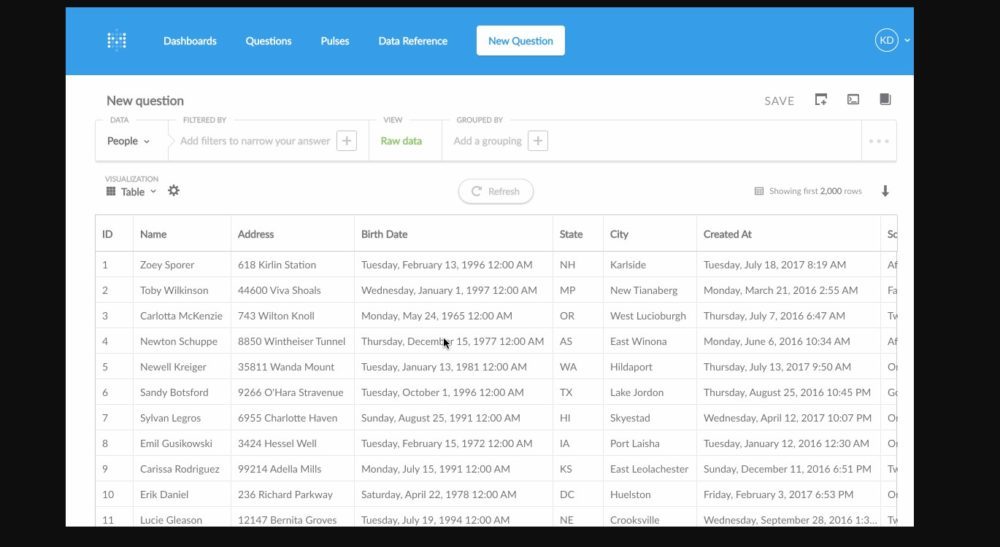
Comapred to displaying structured logs in Metabase. (This isn't text logs but you get the point.)
- https://www.predictiveanalyticstoday.com/wp-content/uploads/...
Kestra (and so airflow) is more a workflow manager to handle data pipeline like moving large dataset (batch) between different source and destination, do some transformation inside database (ELT) or with Kestra you are also able to transform the data (ETL) before save it to external systems.
This lead Kestra (and so airflow) to have a lot of connectors to differents systems (like SQL, NOSQL, Columns database, Cloud Storage, ...) that is ready to use out of the box.
temporal.io, since it's first design to handle microservice (proprietary & internal service) don't have this connector out of the box, and you will need code all this interaction.
So my opinion:
Building data pipeline interacting with many standard systems will be done easily & quickly with Kestra (or airflow)
Handling internal business process of micro service will done easily with temporal.io
Working well on a standard laptop easily
You have 3 solutions for that:
- you can use this task using runner:DOCKER property and choose the image: https://kestra.io/plugins/core/tasks/scripts/io.kestra.core....
- you can also use PodCreate to launch a pod on a kubernetes cluster: https://kestra.io/plugins/plugin-kubernetes/tasks/io.kestra....
- you have also CustomJob from VertexAI on GCP to be able to launch a container a ephemeral cluster (with any CPU / GPU): https://kestra.io/plugins/plugin-gcp/tasks/vertexai/io.kestr...
Have not seen the participants - how many contributors do you have?
This one trust on the project and decide to go production with Kestra. So they decide to inject some resource in order to develop some features that need and that is missing.
But basically, not so much people for now. We are trying to start a community around the product and started to communicate around the product since few weeks only, I hope community will follow us! And I hope to succeed like on my other open source project: https://github.com/tchiotludo/akhq
For the desktop app, I don't know, build one with electron can be simple, but a full app is not on the roadmap for now. What is your usages ?
- Because the application is built on top of Kafka, and Kafka Streams that is only available on Java
- Because the java ecosystem is very large and there is a lot good library to handle a lot of workload
- Because I love strong typing and the language (but no matter for the user, just a personal pleasure :D)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}