Surprised it was a single availability zone, without redundancy. Having multiple fully independent zones seems more reliable and failsafe.
Astonishing how our important infrastructure is moved to AWS with zero knowledge of how AWS works.
It's also a lot more expensive. Probably order of magnitude more expensive than the cost of a 1 day outage
In theory the only additional cost should be the latency-based routing itself, which is $50/month. Other than that, you'll probably save money if you choose the right regions.
Not sure I agree. Yes, network costs are higher, but your overall costs may not be depending on how you architect. Independent services across AZs? Sure. You'll have multiples of your current costs. Deploying your clusters spanning AZs? Not that much - you'll pay for AZ traffic though.
Multi-Region is a different story.
I don't think these independent zones exist. See AWS's recent outages, where east cripples west and vice versa.
(N.B. I find HN commentary on AWS outages pretty depressing because it becomes pretty obvious that folks don't understand cloud networking concepts at all.)
Wouldn't it be possible to create fully independent zones with multiple cloud providers, like AWS, GCP, Azure? This is assuming that your workloads don't rely on proprietary services from a given provider.
This is exactly one of the reasons people go cloud. Introducing an additional AZ is a click of a button and some relatively trivial infrastructure as code scripting, even at this scale.
Running your own data center and AZ on the other hand requires a very tight relationship with your data center provider at global scale.
For a platform like Roblox where downtime equals money loss (i.e. every hour of the day people make purchases), then there is a real tangible benefit to using something like AWS. 72 hours downtime is A LOT, and we're talking potentially millions of dollars of real value lost and millions of potential in brand value lost. I'm not saying definitively they would save money (in this case profit impact) by going to AWS, but there is definitely a story to be had here.
This also introduces new modes of failure which did not exist before. There are no silver bullets for this problem.
You constantly hear about multi zone, region, cloud. But in practice when things break you hear all these stories of them running in a single region+zone
> Several months ago, we enabled a new Consul streaming feature on a subset of our services. This feature, designed to lower the CPU usage and network bandwidth of the Consul cluster, worked as expected, so over the next few months we incrementally enabled the feature on more of our backend services. On October 27th at 14:00, one day before the outage, we enabled this feature on a backend service that is responsible for traffic routing. As part of this rollout, in order to prepare for the increased traffic we typically see at the end of the year, we also increased the number of nodes supporting traffic routing by 50%
Consul was clearly the culprit early on, and you just made a significant Consul-related infrastructure change, you’d think rolling that back would be one of the first things you’d try. One of the absolute first steps in any outage is “is there any recent change we could possibly see causing this? If so, try rolling it back.”
They’ve obviously got a lot of strong engineers there, and it’s easy to critique from the outside, but this certainly struck me as odd. Sounds like they never even tried “let’s try rolling back Consul-related changes”, it was more that, 50+ hours into a full outage, they’d done some deep profiling, and discovered the steaming issue. But IMO root cause analysis is for later, “resolve ASAP” is the first response, and that often involves rollbacks.
I wonder if this actually hindered their response:
> Roblox Engineering and technical staff from HashiCorp combined efforts to return Roblox to service. We want to acknowledge the HashiCorp team, who brought on board incredible resources and worked with us tirelessly until the issues were resolved.
i.e. earlier on, were there HashiCorp peeps saying “naw, we tested streaming very thoroughly, can’t be that”?
Also, multiple changes may have confounded the analysis. Adjusting the Consul configuration may have been one of many changes that happened in the recent past, and certainly changes in client load could have been a possible culprit.
Quite frankly relying on consul scares the shit out of me. There are so few guarantees and so many pitfalls and traps that I don’t sleep well. At this point I consider it a mortal risk.
That applies to vault as well.
And there is still no satisfying explanation for this:
> The system had worked well with streaming at this level for a day before the incident started, so it wasn’t initially clear why it’s performance had changed.
But I totally agree with you that the first thing they should look into is to rollback the 2 changes made to the traffic routing service the day before, as soon as they discovered that the consul cluster had become unhealthy.
Frequently the feature you want to roll back now has other services depending on it, has already written data into the datastore that the old version of the code won't be able to parse, has already been released to customers in a way that will be a big PR disaster if it vanishes, etc.
Many teams only require developers to maintain rollback ability for a single release. Everything beyond that is just luck, and there's a good chance you're going to be manually cherry picking patches and having to understand the effects and side effects of tens of conflicting commits to get something that works.
With the behaviour matching other types of degradation (hardware), it's entirely reasonable that it could have taken quite a while to recognise that software and configurations that have proven stable for several months, that is still there working, wasn't quite so stable as it seemed.
- The write up is amazing. There is a great level of detail. - When they had the first indication of a problem, instead of looking if the problem was the hardware (disk I/O, etc.) the team went full cattle/cloud: bring down the node, launch a new one. Apparently that cost them a few hours. We would probably have done the same but I wonder if there's a lesson there. - The obvious thing to do was revert configs. It is very strange that it took so long to revert. After being down for hours and having no idea what gives, it's the reasonable thing to try. - The problem was consul. But consul is a key component and Roblox seem to be running a fairly large infrastructure. The company's valuation is sky-high, I assume the infra team is quite large. Consul is an open source project. Wouldn't make sense instead of relying on hashicorp so heavily to bring-in or train ppl around consul internals at this point? (maybe not possible/feasible/optimal, just wondering)
Would be a nice touch to check if bbolt has the bug and possibly push a fix. That said, the post-mortem is state-of-art. Way better than anything we've seen from much much bigger companies.
I shouldn't have drank that many
Hindsight is 20-20
Stop.
–
Little elevators are far too small for me
So I ride the big ones
It's not so fun unless you're OCD
And you like buttons
I recommend watching the following:
Roblox is great that it built up an ecosystem where people can contribute and get rewarded. It is a positive feedback loop.
Not like open source software, where the financial loop is broken. I am pretty sure the Bolt creator did not get anything from HashCorp for his work.
I know there are lots of child actors and plenty of household situations that make enjoying childhood difficult for many youths - but just because we're already bad at a thing doesn't mean we should let it get worse. Child labour laws were some of the first steps of regulation in the industrial revolution because inflation works in such a way where opening the door up to child labour can put significant financial pressure on families that choose not to participate when demand adjusts to that participation being normal.
>"As there are no discoverability tools, users are only able to see a tiny selection of the millions of experiences available. One of the ways boost to discoverability is to pay to advertise on the platform using its virtual currency, Robux."
(Note that this "virtual" currency is real money, bidirectionally exchangeable with USD).
The sales pitch is "get rich fast":
>"Under the platform’s ‘Create’ tab, it sells the idea that users can “make anything”, “reach millions of players”, and “earn serious cash”, while its official tutorials and support website both “assume” they are looking for help with monetisation."
I agree that this doesn't really look like a labor issue. That's distracting and contentious tangent; it's easier to just label this as a kind of consumer exploitation. (Most of the people involved aren't earning money -- but they are all paying money). It's a scam either way.
Edit to add: lazy people downvote.
Big props to the on-calls during this.
Kind of curious about this. I know this is probably company specific but how do outages get handled at large orgs? Would the on-calls have been called in first then called in the rest of the relevant team?
Is their a leadership structure that takes command of the incident to make big coordinated decisions to manage the risk of different approaches?
Would this have represented crunch time to all the relevant people or would this be a core team with other people helping as needed?
Yes. This was a multi-day outage and eventually the oncall does need sleep, so you need more of the team to help with it. Typically, at any reasonable team, everyone that chipped in nights get to take off equivalent days and sprint tasks are all punted.
Yes. Not just to manage risks, but also to get quick prioritization from all teams at the company. "You need legal? Ok, meet ..." "You need string translations? Ok escalated to ..." "You need financial approval? Ok, looped in ..."
Kinda. Definitely would have represented crunch time, but a very very demoralizing crunch time. Managers also try to insulate most of their teams from it, but everyone pays attention anyways. Keep in mind these typically only last an hour or 3, at most they last a few days, so there is no "core team" other than the leadership structure from your question 2. Otherwise, it is very much "people/teams helping as needed".
The largest of these calls I've seen was well into the hundreds of sw engineers, managers, network engineers, etc.
Working with them during an incident is an on call comms lead, who handles outside-of-team comms (protecting the engineers), and an engineering lead (who is a consultant, advisor, and can approve certain actions).
For big incidents, an exec incident manager is involved. They primarily help with getting resources from other teams.
Edit: sometimes when it's a really gnarly problem and there are huge numbers of people on the call, the set of people who are actively trying to come up with mitigations and need to just be able to talk freely at each other will break off into a less noisy call and leave a representative to relay status to the main call.
During the worst outage I was a involved in basically the entire org including all of the most senior engineers worked around the clock for two weeks to fix everything
LMDB uses a regular bucket for the freelist whereas Bolt simply saved the list as an array. It simplified the logic quite a bit and generally didn't cause a problem for most use cases. It only became an issue when someone wrote a ton of data and then deleted it and never used it again. Roblox reported having 4GB of free pages which translated into a giant array of 4-byte page numbers.
How does this happen so often? It's awesome to get the authors take on things. Also thank you for explaining and owning it. Where you part of this incident response?
So BoltDB and LMDB affected users may switch to libmdbx as the Erigon (Ethereum implementation) does year ago https://github.com/ledgerwatch/erigon/wiki/Criteria-for-tran...
For now this is (relatively) easy since bindings for GoLang, Rust NodeJS/Deno, etc are available and the API is mostly the same in general.
---
The ideas that MDBX uses to solve these issues are simple: zero-cost micro-defragmentation, coalescing short GC/freelist records, chunking too long GC/freelist records, LIFO for GC/freelist reclaiming, etc.
Many of the ideas mentioned seems simple to implement in BoldDB. However the complete solution is not documented and too complicated (in accordance with the traditions inherited from LMDB ;)
:)
It's also interesting how much a tiny detail can derail a huge organization. My former employer lost all services worldwide because of a single incorrect routing in a DNS server.
Is there an issue/bug for this somewhere?
OSS contributors are rarely noticed or appreciated. Did HashiCorp ever sponsor you or share any revenue with you? The OSS ecosystem is broken.
Why do I have a feeling "enjoyed" wasn't really enjoyed so much as "WTF", followed by "oh shit..." at the thought that their main way to balance load may have gone out the window.
Sometimes it's even the Missouri state governor doing that too.
As far as players figuring out the DNS steering scheme; the company has no responsibility to keep a non-advertised backend up. If it was a problem, disallow new connection to it and remove it from the main pool.
Playing "what-if" thought experiments is fun, but when the rubber hits the road, you often find that things that are stable for 99.99%+ of load patterns encounter previously unforeseen problems once you get into that far-right-hand side of the scale. And it's not like we've completely mastered squeezing performance out of huge CPU core counts on NUMA architectures while avoiding bottlenecking on critical sections in software. This shit is hard, man.
Everything is duplicated which is potentially wasteful but ensures complete redundancy and it’s an insurance policy. If you rollout, you rollout to each datacenter separately. So in this case rolling out in one complete datacenter and waiting a day for their Consul streaming changes probably would have caught it.
Not only can one save a significant amount of money, it can also be simpler to troubleshoot and resolve issues when you have a simpler backend tech stack. Perhaps that doesn’t apply in this case, but there are plenty of use cases which don’t need a hundred micro services on AWS, none of which anyone fully understands.
You're assuming the average profits lost are more than the average cost of doing things differently, which, according to their statement, is not the case.
According to this user's comments, it doesn't look like it'll be that tough for them:
Service discovery largely doesn't change that often. Especially in an outage where a lot of things that churn service discovery are disabled (e.g. deploys), returning stale responses should work fine. There's a reason DNS works this way - it prioritizes having any response, even if stale, since most DNS entries don't change that frequently. That said, DNS is not a great service discovery mechanism for other reasons. Not sure if there's an off-the-shelf solution that relies more on fast invalidation rather than distributed consistent stores.
Dissecting this paragraph from the post-mortem...
> When a Roblox service wants to talk to another service, it relies on Consul to have up-to-date knowledge of the location of the service it wants to talk to.
OK.
> However, if Consul is unhealthy, servers struggle to connect.
Why? The local "client-side" consul agents running on each hosts should be the authoritative source for service discovery, not the "server-side" consul agents running on the 5 voter nodes.
> Furthermore, Nomad and Vault rely on Consul, so when Consul is unhealthy, the system cannot schedule new containers or retrieve production secrets used for authentication.
Now that's one very bad setup, similar to deploying all services in a single k8s cluster.
Fwiw I believe kubernetes did this right - if you shoot the entire set of leaders, nothing really happens. Yes if containers die they aren’t restarted and things that create new pods (eg cron jobs) won’t run, but you don’t immediately lose cluster connectivity or the (built-in) service discovery. Not to say you can survive az failures or the like - or that kubernetes upgrades are easy/fun.
And don’t run dev stuff in your prod kube cluster. Just…don’t.
Their argument is that the membership set for a service (especially on-prem) doesn't change all that frequently, and even if it's out of date, it's likely that most of the endpoints are still actually servicing the thing you were looking for. That plus client retries and you're often pretty good.
I kid of course. One of the best post-mortems I've seen. I'm sure there are K8s horror stories out there of etcd giving up the ghost in a similar fashion.
>Critical monitoring systems that would have provided better visibility into the cause of the outage relied on affected systems, such as Consul. This combination severely hampered the triage process.
which gives me goosebumps whenever I hear people proselytizing everything run on Kubernetes. At some point, it makes good sense to keep capabilities isolated from each other, especially when those functions are key to keeping the lights on. Mapping out system dependencies (either systems, software components, etc) is really the soft underbelly of most tech stacks.
Hah! Good one!
(Ignoring the points around observability dependencies on the system that went down causing the failure to be extended)
I went into more detail here: https://news.ycombinator.com/item?id=30015826
The outage occurring could certainly happen to anyone, but it taking 72 hours to resolve seems like a pretty fundamental SRE mistake. It’s also strange that “try rollbacks of changes related to the affected system” isn’t even acknowledged as a learning in their learnings/action items section.
> The system had worked well with streaming at this level for a day before the incident started, so it wasn’t initially clear why it’s performance had changed.
And a short note later on how much load their caching system sees:
> These databases were unaffected by the outage, but the caching system, which regularly handles 1B requests-per-second across its multiple layers during regular system operation, was unhealthy.
Seems like the smoking gun, this should have been identified and rolled back much earlier.
When you say: status update chain: ceo --> me. What information is flowing from the CEO to you? or is it the other way around?
Yeah, don't use consul as redis, they are not the same.
A) they're afraid to ask for permission and would rather ask for forgiveness
B) management refused to provision extra infra to support the engineers need, but they needed to do this "one thing" anyways
C) security was lax and permissions were wide open so people just decided to take advantage of it to test a thing that then became a feature and so they kept it but "put it on the backlog" to refactor to something better later
That said, could've happened to anyone and it was a great write up.
Unfortunate, given it has been around for a while.
Took a major incident to swallow your pride? (consul, powered by go.etcd.io/bbolt)
EDIT: I think we're talking about two different options. I meant the ability to leave sync turned on but change the data structure.
Especially with these kind of fundamental, core services such as Consul provides, it’s not unheard of to have templates with static machine allocations (as opposed to everything in a single auto-scaling group). It’s a bit of a shortcut, but it’s often a bit hairy to implement these services using true auto-scaling.
Having said all this, doing these types of migrations when things are already completely broken / on fire makes things a lot easier: you don’t care about downtime. So then it can be as simple as restarting all instances using a new instance type, downtime be damned.
* How their system architecture made them particularly vulnerable to this kind of issue
* Their actions to diagnose and attempt to mitigate the issue
* The whole later part about effectively cold-starting their entire infrastructure, all while millions of users were banging on their metaphorical door to start using the service again.
In a cloud provider, having a few people working simultaneously on spinning up instances with different potential fixes, running different tests, and then directing all traffic to the first one that works properly is a viable path to a solution.
When you have your own hardware, you can really only try one thing at a time.
How so? What would prevent you from hiring 5-10 people for Ops heavy stuff and getting a bit more hardware resources and doing those things in staging environments with load tests and whatnot? I mean, isn't that how you should do things, regardless of where your infra and software is?
If you use AWS, then you probably on average use the same day to day, but in an emergency you can spin up 5 versions of full production scale to test 5 things at once, and just edit a configfile to direct production traffic to any.
https://blog.roblox.com/wp-content/uploads/2021/11/3-perf-re...
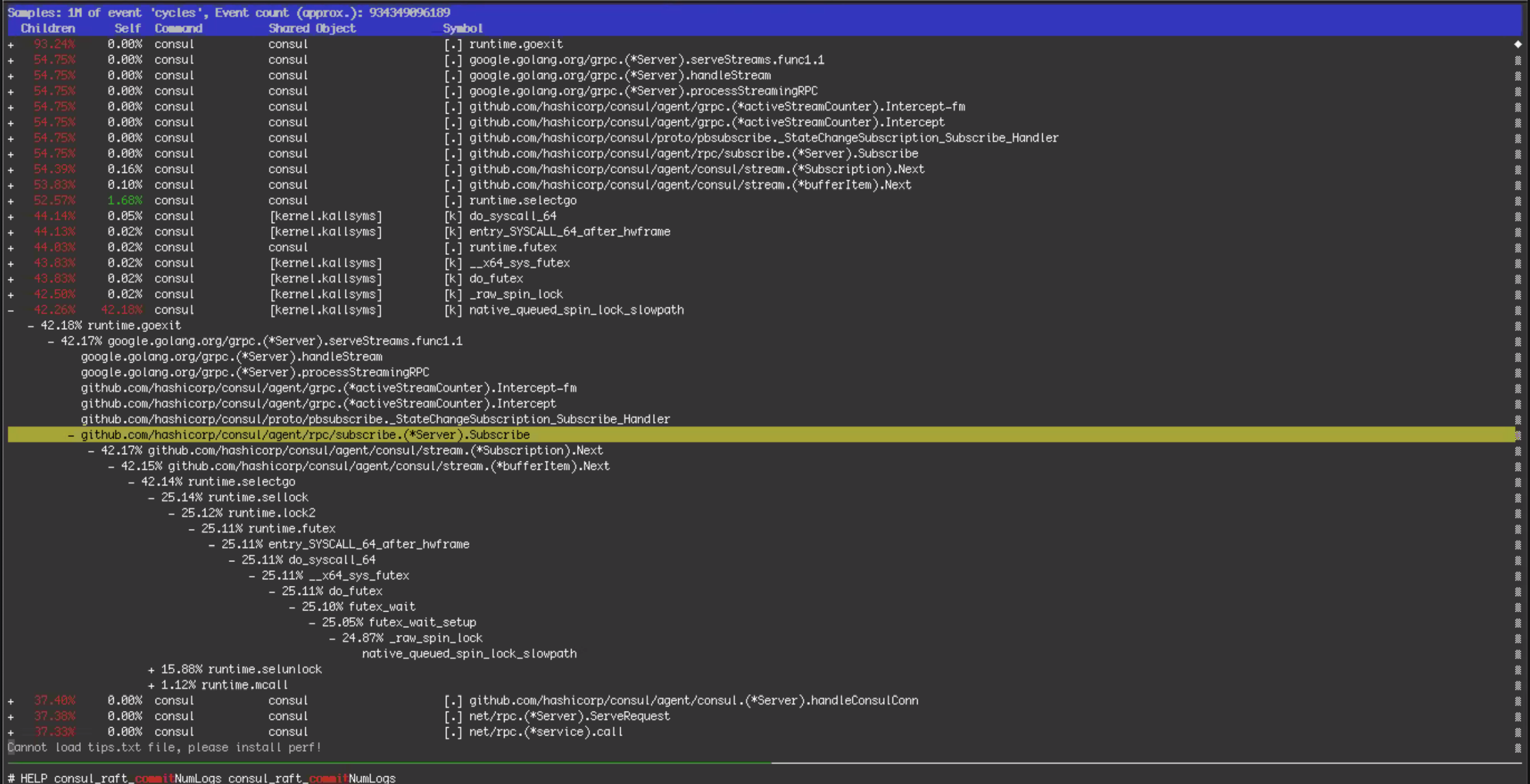
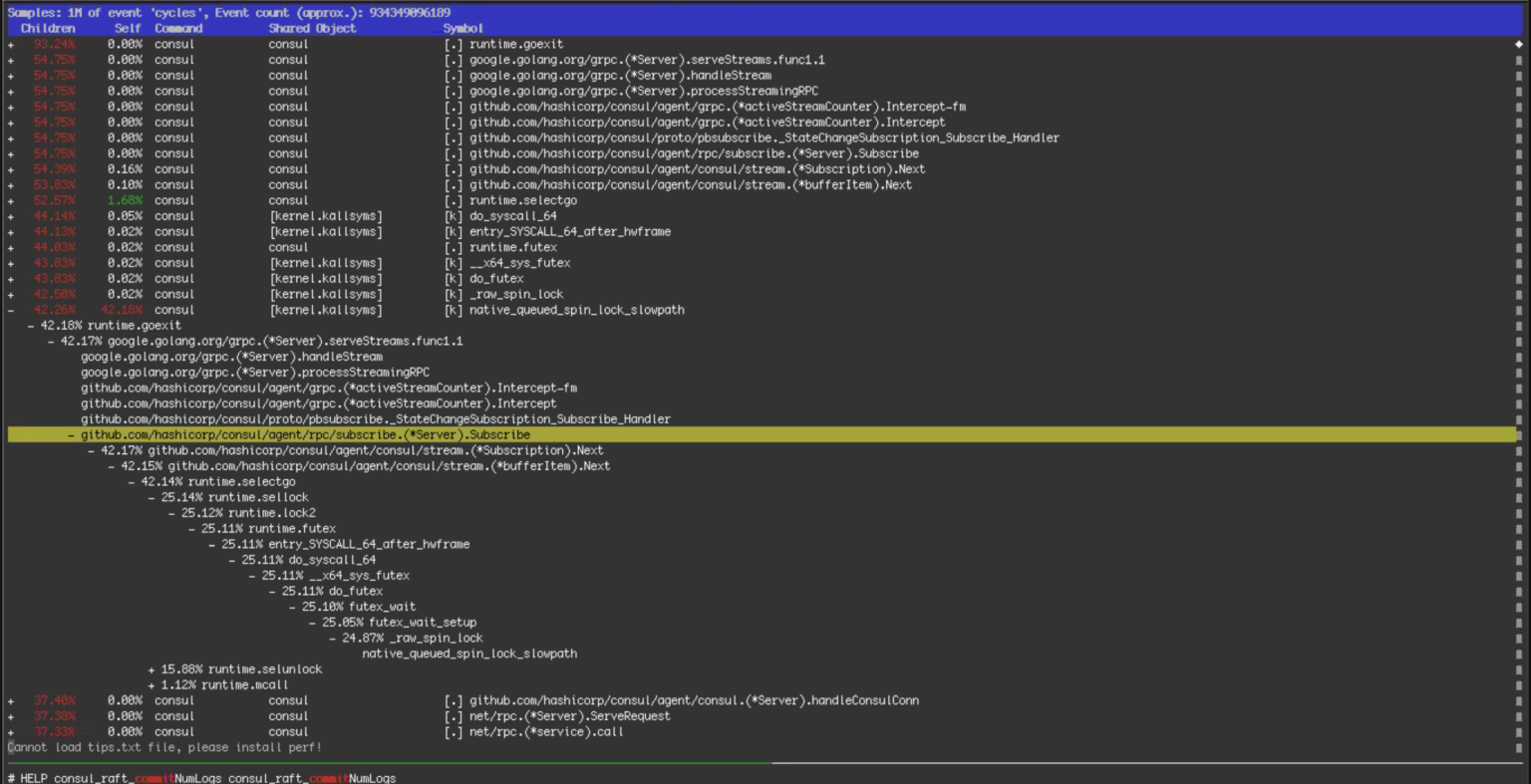
Is it really perf?
[0]: https://man7.org/linux/man-pages/man1/perf-report.1.html
It's perf.
I don't understand this logic. are they basically saying that their servers are on average closer to the user than mainstream cloud infra? are they e.g. choosing to have N satellite servers around a city instead of N instances at one cloud provider location in the centre of the city? is it the sparseness of the servers that decreases the latency?
or is it more to do with avoiding the herd, i.e. less trafficky routes / beating the queues?
it's also unclear whether they use their own hardware on rented rackspace as that could potentially lower costs too
If you have a latency sensitive application (like multiplayer games) it makes sense to put a few servers in each of 100 locations rather concentrate them in a half dozen cloud regions.
As they point out elsewhere, the cost of infrastructure directly impacts their ability to pay creators on the platform. Doing it yourself will always be cheaper, and they hired the smart people to make it happen.
Large cloud providers have a backbone network with interconnects to many ISPs reducing the amount of Hops a client has to take across the internet.
> Doing it yourself will always be cheaper
Treating the Cloud as a traditional IAAS Datacenter extension will be more expensive. By utilising PAAS, only using resource that's needed and when it's needed, etc.. is much cheaper.
They wanted to make sure everything was fixed before publishing
This appears to be why the outage was extended, and was referenced elsewhere too. It's hard to diagnose something when part of the diagnostic tool kit is also malfunctioning.
It is annoying, because the tools actually run perfectly fine on a local desktop, once you are past the "mothership handshake". I spent that week reading roblox dev documentation instead.
Also, i'm curious about your experiences with Roblox. I've only heard about it from these HN threads (no i don't know a single person using it) so if you have feedback to share regarding how to program it and how it compares to a modern game engine/editor like Godot, i'm all ears. Also, if you know of a free-software "alternative" to Roblox ; i'm amazed we run proprietary software in the first place, worried when it doesn't run because it can't phone home, but i'm actually ashamed we end up *producing* (eg. developing) content with proprietary tools that these companies can take away from us any minute.
However, the short 2-line way to get that output is the following:
perf record -F99 -g --pid $(pidof consul)
# Wait a few seconds and hit ctrl-c
perf report
That's impressive.
Would be interesting to compare this result to the classic paper on Tandem failures:
A. Thakur, R. K. Iyer, L. Young and I. Lee, "Analysis of failures in the Tandem NonStop-UX Operating System," Proceedings of Sixth International Symposium on Software Reliability Engineering. ISSRE'95, 1995, pp. 40-50, doi: 10.1109/ISSRE.1995.497642.
If vendors, it is reckless.
I would normally not call this out, but it is repeated so often in the text that it is jarring. Just call it "median" as it is everywhere else, please.
On the other hand, I must commend the author(s) for not using "based off of" :-)
Great write-up, otherwise.
> Note all dates and time in this blog post are in Pacific Standard Time (PST).
But the incident was during PDT. Just use UTC or colloquial "Pacific time" or equiv and never be wrong!
My heart goes out to these people. I can imagine how much sustained terror they were feeling, stare hard and harder at your terminals and still nothing makes sense.
{kind=link}
{kind=link}