Holding up quite well despite HN frontpage. I love what a bit of caching can do.
EDIT: appears I jinxed it. I get the allure of hosting something in your home, but these days when you can get a decent VPS for $10/yr it doesn’t really make sense.
When you're hosting static content (like presumably this content is; it's down so I can't say for sure), you should distribute it on a CDN for $0/year. A single VPS can be overwhelmed by traffic just as your Raspberry Pi can.
P.S. Getting weird RPi errors because of power supply makes you appreciate the value proposition of a good VPS :p
But yeah, I agree. This is static content, and should be hosted on any of the gazillion free tier CDNs. But then you don’t get that warm fuzzy feeling of watching the rPi behind your couch melt into the floor.
Otherwise, for a well-known average traffic load suitable to a Pi, a Pi is a great idea.
Nowadays a host personal projects on scaleway and netcup (EU based). I've been with the first for a could of years and the second for 6 months now, good service from both.
If you're mainly hosting static* or cacheable content, you may even get by with a raspberry pi running behind cloudflare's free plan with cache enabled. If you don't mind all traffic to your site being served by such a third party of course.
* If you only have static content, GitHub pages can be considered too.
EDIT: evidently, not far
I thought this was going to be about some sneaky exploit where they'd manage to get a gov.uk to forward links to porn or something. But no, it's really a whole subdomain just taken over by some sketchy porn site.
I'm wondering if the porn site operators even know it's happening? Seems the most likely thing is the DfT had a site at that URL, hosted on AWS. And then they shut it down without removing the DNS record and Amazon assigned that IP to somebody else.
Lots of bulk hosts will let you pick (or randomly be assigned) a shared IPv4 address like 10.20.30.40 and then - either by luck or often alphabetical order - your aaardvark.mydomain.example gets to be the "default" host which shouldn't exist for HTTPS but does in many popular half-arsed HTTPS web servers including Apache. So now web clients connect to 10.20.30.40, they send SNI to the bulk host's server - "I'm here to talk to thing.mycorp.example" and it ignores what they said and gives them aaardvark.mydomain.example because that's the "default" now. And if Let's Encrypt accepted that, you could buy some bulk host accounts, impersonate all these abandoned sites and get certificates for them. So, they had to knock that on the head.
The custom TLS server trick works by (ab)using ALPN, lazily made servers like Apache don't ignore ALPN at least unlike SNI, and so the client learns this server wasn't the one with the ALPN it needed to talk to after all and the certificate isn't issued.
‡ 10.20.30.40 isn't a real public address it's just for example purposes here
There’s an RFC for that :)
How that challenge worked was that the CA would give you a certificate for a fictitious name (say, abc123.acme-challenge.invalid) and you had to present it from the host when asked for that name by the client (the CA) though SNI.
Many hosts that share IPs between customers also let those customers upload their own certificates. The attack just involved uploading a challenge certificate for a colocated site, and letting the host serve it as expected. Even if the host _did_ check that the name on the cert was not the name of another customer (which is itself sometimes impossible), and even if the target site was not abandoned, and even if it had correctly functioning HTTPS, these are fictitious made up names, so the attack would still work.
It involved no ignoring the Host header, or really any misconfiguration, that’s why it requires rolling to tls-alpn.
I suppose there's a few possible explanations here: (1) the original site was hosted on S3, and at some point the bucket was dropped and someone else picked it up, (2) it was originally hosted on S3 and the bucket got hacked, (3) someone with access to the DNS has decided to go rogue and point it at a somewhat-legit-looking but fake domain. If there are historical DNS records floating around it might help to narrow down what happened here.
1. gov.uk’s DNS server used to point charts.dft.gov.uk to something legitimate 2. Someone hacked gov.uk’s DNS server, and changed this one specific domain to CNAME charts.dft.gov.uk.s3-website-eu-west-1.amazonaws.com 3. That same someone set up their porn thing at AWS in a bucket that maps to charts.dft.gov.uk.s3-website-eu-west-1.amazonaws.com
The CNAME of charts.dft.gov.uk.s3-website-eu-west-1.amazonaws.com still works, but the reverse DNS of that IP is simply s3-website-eu-west-1.amazonaws.com: I am not sure how does one gain control of an s3-website subdomain when "abandoned" (bucket name only?), but someone did.
So the scenario someone described below is pretty likely: DoT drops it, and drops AWS use of the name, but leaves the DNS record in. I wouldn't attribute this to anyone in the DoT.
It would still require intentional action to do so, though, so I wonder if anyone has any clue how do people find out about spurious, unused S3 subdomains that still have DNS pointing at them? Scan the entire internet for domains pointing to s3-website, and check AWS API to see if it's available? Or did someone run into this by accident and decided to poke fun at it while earning some cash along the way?
There are bots that scan for this. Then someone creates the bucket on S3 and boom, subdomain hijack.
>> Scan the entire internet for domains pointing to s3-website, and check AWS API to see if it's available?
What I wonder is how do you scan all the DNS records with their subdomains? Unlike IPv4 address space, which is very decidedly finite and not-too-big, the space of all the subdomains is basically infinite.
Other than using AXFR (zone-transfer DNS request) which is usually restricted, you are searching an unbounded space.
I guess you don't need an AWS API calls since hitting a non-existing bucket with HTTP will let you know: http://something.that.does.not.exist.s3-website-eu-west-1.am...
IOW, how would you write such a bot? :D
'This site is hosted on a Raspberry Pi 4B in the author's living room (behind the couch)'
> Elsewhere we have the Department for Transport careers page, which sort of does what it says. Clicking on the ‘see all vacancies’ button will redirect you to the civil service jobs site. This isn’t weird in itself, what is weird is that it uses t.co - Twitter’s redirection and domain obscuring tool to do it. Don’t ask us why, we have no idea why they would do this.
This sounds like someone inexperienced with the system is somehow managing it. How can you use a t.co link for... this? I'm surprised this edit got past anyone.
EDIT: Redacted the link just to be on the safe side. It's in the article if anyone's curious.
The content on this page isn't written by tech people - it's written by policy experts and other civil servants whose expertise isn't exactly how URL's work...
That's not a very fair assessment. The same way as it's difficult to find British dishes better than, say, minced beef and onion pie, it's challenging to find authentically British porn that's better than this govermnent office provides its people. We should commend the Tory government for its dedication.
That's a concept I have not pondered before.
I’m sorry.
A scanner that would have caught the vulnerability: https://tech.ovoenergy.com/how-we-prevented-subdomain-takeov...
Or a grey hat scanner for finding sub-domains vulnerable to takeover: https://github.com/m4ll0k/takeover
[1]: https://web.archive.org/web/20211125154944/http://charts.dft...
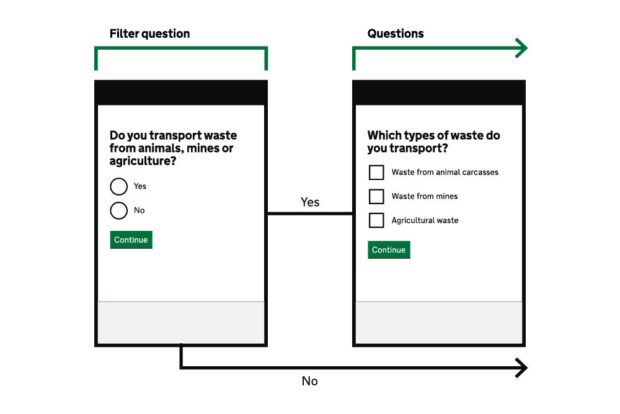
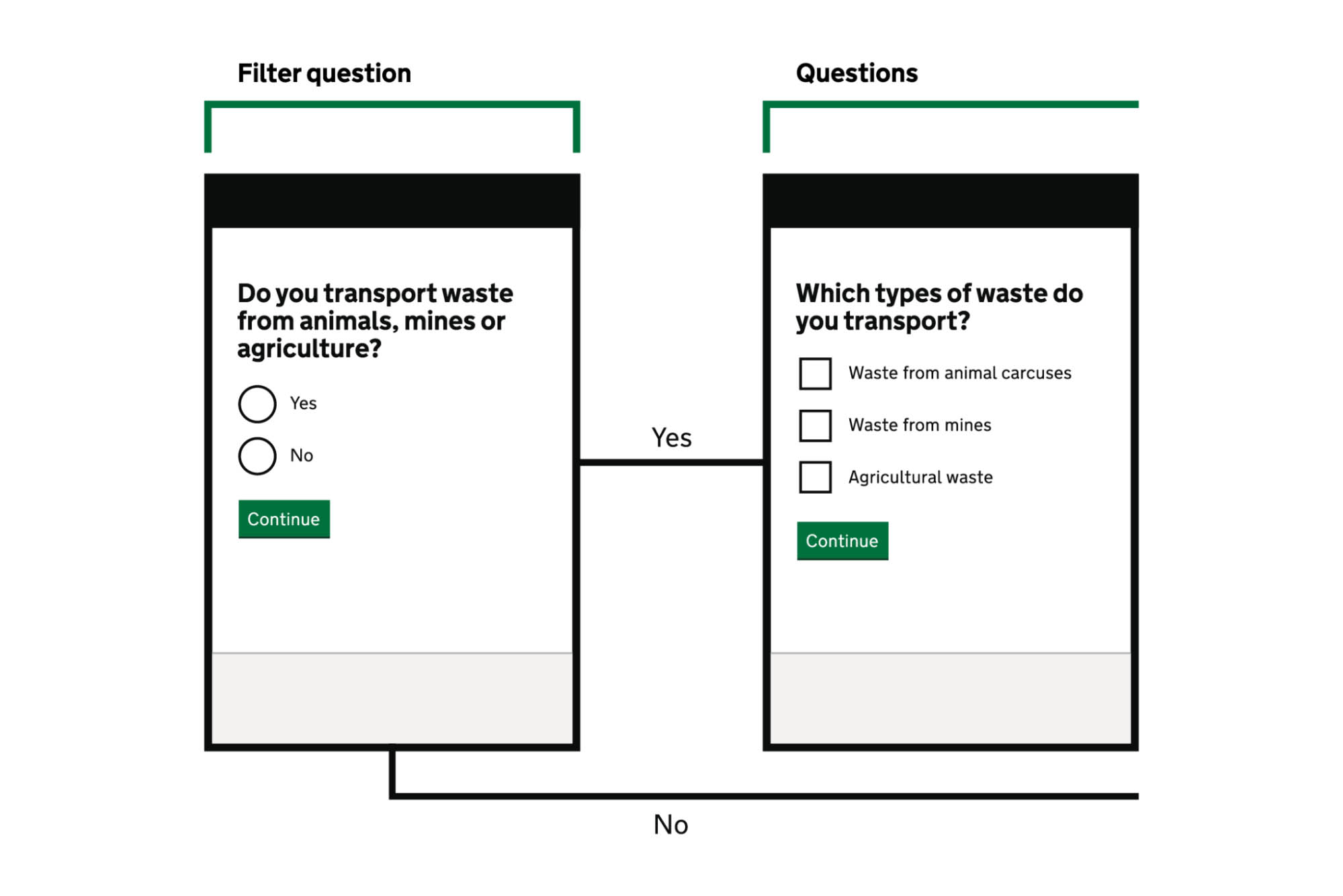
Now anyone with a rudimentary handle of the English language would probably have noticed the misspelling of carcasses on the blogpost https://designnotes.blog.gov.uk/2021/11/15/letting-users-tic... and Yorwba highlighted this on 17 November 2021 as seen in the comments. The team duly acknowledge this as seen with the updated image here https://designnotes.blog.gov.uk/wp-content/uploads/sites/53/... and the original misspelling can still be seen here https://designnotes.blog.gov.uk/wp-content/uploads/sites/53/...
Anyway, it would seem their commenting system will not allow links to be posted to them or they choose to ignore links or didn't understand the comment posted when comments like "https://www.bing.com/search?q=plural+of+carcass" come through to them which is metadata for the type of filtering being employed on their comments section.
I think its worth looking at their design principles which can be seen here https://www.gov.uk/guidance/government-design-principles "#1 Start with user needs Service design starts with identifying user needs. If you don’t know what the user needs are, you won’t build the right thing. Do research, analyse data, talk to users. Don’t make assumptions. Have empathy for users, and remember that what they ask for isn’t always what they need."
It would seem Grant Shapps Secretary of State for Transport is perhaps actually meeting the public's needs or maybe its what he thinks of the public. Are we solitary handy manipulators of parts of the body?
{kind=link}
{kind=link}