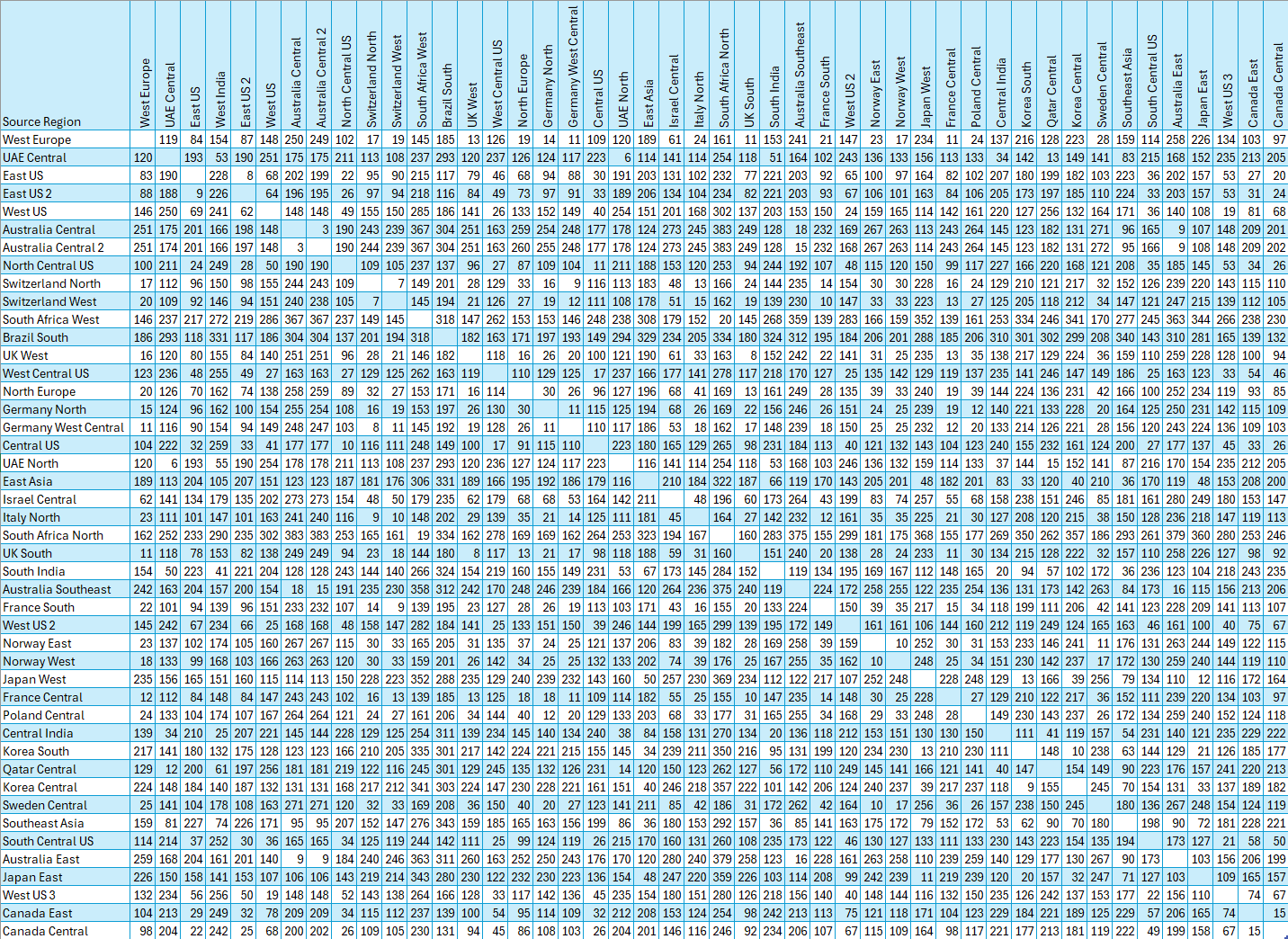
I'm in SJC (San Jose / Silicon Valley) and https://fly-global-rails.fly.dev/regions/syd shows that my replay time to their region in Sydney Australia is between 25 and 45ms. That's pretty quick!
What on earth.. Are people really OK with adding 25-45ms latency because they can't be bothered to route their query to a database that can actually service it?
They're ok with it because a (valuable) write request that's 10% slower typically comes after a read request that's much, much faster. In this scenario:
> my replay time to their region in Sydney Australia is between 25 and 45ms. That's pretty quick!
The first read only requests were probably <100ms for simonw. The replayed request (that he initiated with a click) was probably 500ms. When a request already takes 500ms, an additional 50ms of latency is basically noise.
The alternative is (often) for them to refactor their apps and then enforce write restrictions on code to make sure random GETs don't write to the DB unnecessarily.
Our goal was to make this work without requiring hairy code changes. People who are ready to do the work to optimize their apps can make things faster and use what we're doing now as a fallback, if they want.
I guess it really just depends on what you're trying to do. I would never consider 50ms as noise. It's an accumulation of various things taking 50ms that results in your request taking 500ms in the first place, which is very slow.
I'm interested in this though. I think it's a cool experiment!
This is meant to decrease the unfixable latency, it's probably not a good way to solve app level latency issues.
I wish that wasn't true, but that's what I've seen.
What would be awesome to have is something like this but built on top of envoy postgres proxy or similar where it would know where to send the query to based on the table + column value / pk. But one then rebuilds Yugabyte.
That sounds like sharding, which Postgres supports already.
Us West - Australia round-trip for them is ~140ms. And ~50ms seems to be the physical limit unless I messed up the numbers somewhere?
Edit:
Syd-syd response time 138ms
Syd-lax response time 427ms, replay time 16ms
Ok, not sure what the replay time means in this case (extra latency from the cancellation?), but it's not the total cost and you really don't want to send those packets around the world :-)
The entire request to Sydney for me (from Chicago) takes 516ms, 15ms of that is "replay overhead".
There's no reason we can't replay from LAX, though, just need to build it.
{kind=link}