This article from Agoric is extremely relevant here, from a previous such incident (re: the event-stream package on npm): https://medium.com/agoric/pola-would-have-prevented-the-even...
Put simply: in many cases, the dependencies you install don't need nearly as much authority as we give them right now. Maybe some of these packages need network access (I see a few named "logger" which might be shipping logs remotely) but do they need unrestricted filesystem access? Probably not! (They don't necessarily even need unrestricted network access either; what they're communicating with is likely pretty well-known.)
The security manager is an additional layer of security that most languages don't have, however Java applets have shown it to be full of holes and generally unsuitable for running untrusted code.
The applet security posture has contributed a great deal towards negative opinion towards the language, probably would have been better off never having existed.
In 1996, Java was being overwhelmed by exploits because the mapping of the language to the VM was not well matched. There was a Java summit with lots of interesting people. This summit was also when Sun got confirmation that MicroSoft had quite a few engineers working on an independently implemented runtime. To Sun's credit, they did get rather more serious about Java security -- but they had already created a rocky foundation.
It is my opinion, that the business model Sun had "in mind" for Java was a free runtime for everyone that they were in control of, but to make money from selling an "official" Java compiler suite.
I do not believe that the Sun Java JVM was created with security in mind.
I could be wrong, but I don't see any mention of permissions on imported code: https://deno.land/manual@v1.7.2/examples/import_export
Simply relying on package signing and the like permits trusted but malicious actors. With Deno packages configured well it can really lock down and limit a ton of attack vectors.
Here is an interesting proposal on how to possibly get there in JS with import maps: https://guybedford.com/secure-modular-runtimes
Deno uses ambient permissions for the entire process and unfortunately missed the opportunity to do it right.
1. https://hacks.mozilla.org/2019/11/announcing-the-bytecode-al... (ignore the title, it's irrelevant to the excellent explanation that constitutes 70% of the post)
The main hope at the moment seems to be JS.
I thought it was because operating systems still use access based instead of capabilities based security?
That's how the web/application server containers worked (probably still do, but I've been disconnected). The server classes have different permissions from the application code classes (loaded from the .war/etc files). If an application code method calls into a system class, the permissions which apply are those or the application since that method is in the calling stack frame.
I wrote this support into several Java web container and J2EE application server products back in the day. AFAIK, all that still works great today in Java.
e.g., If someone gives an app the ability to upload photos, it can silently read all photo metadata, upload all photos to a private server instead of uploading just the single photo that the user picked. This can be solved with OS level standard photo pickers but it hasn't been yet.
Same with package code. Maybe a package needs network access for stuff it genuinely needs to do. However it can (and probably will) at some point go above and beyond in the amount of data it collects. FB Mobile SDK outage is a good example of this. https://www.bugsnag.com/blog/sdks-should-not-crash-apps
Agoric (the company whose blog post I linked to) and the people behind it have done a ton of object capability work over the years.
POLA is good to live by regardless if it can be implemented.
Systemd has some capability to restrict access to system resources. I haven't experimented with the capabilities yet so not sure what's all there.
Free software / open source propels engineering as you can share and leverage the results of collective efforts. However, at no point did the concept come with inherent guarantees about concerns such as security.
esr defined 19 points for "good" open source software development in his seminal essay "The Cathedral and the Bazaar". I feel some of those are sometimes easily thrown out of the window for the sake of "efficiency" or "cost-effectiveness".
This issue resonates with bullet point 17 in particular:
> A security system is only as secure as its secret. Beware of pseudo-secrets.
I think this issue has less to do with package managers, and a lot with companies rushing into the convenience of public code platforms such as Github without properly vetting whether or not they might be inadvertently leaking internal information through packaging manifests.
That is not true at all, the industry both Development and even more so in Operations has been outsourcing responsibility for a long time, they is why we have support contracts, SLA's and other very expensive services we pay many many times more than the cost of hardware for...
To outsource responsibility... Network down -- Call Cisco... Storage Down Call EMC or Nimble... etc
It seems dumb that they don’t have per repo tokens. I think the issue is with their licensing as if they made proper tokens users could abuse it by giving tokens to their friends. But this should be detectable in a friendly (please don’t do that) way.
I want to be able to give read-only access to private repos.
I want to be able to give fine grained function level and repo level access.
If I’m an admin on multiple repos, I want to be able to issue a token for just a single repo so I can give that to a CI job without worrying if every single repo I admin is at risk.
They allow ssh keys with some similar functionality, but ssh keys can’t be used as much as tokens.
I’ve been waiting for a story about how some third party app granted access to my whole org gets taken over and wreaks havoc. Eventually this will probably be the attack that alters real packages instead of these name overloading packages.
https://docs.github.com/en/developers/apps/scopes-for-oauth-...
https://docs.github.com/en/rest/reference/permissions-requir...
Anyway. I’m sticking with Pop / Linux. But it does make me nervous!
I'd guess distros are generally better off in that respect, but kernel space & user space aren't that different nowadays, when caring about your own security
I'm very happy to finally have a real world example to motivate all the folks that eye-rolled me every time I've raised it in the past. It just resonates better, especially with less technical leadership folks.
what could possibly go wrong?
Random libraries, possibly pulled in by a dependency of a dependency of a dependency... not so much.
curl -sSL https://dot.net/v1/dotnet-install.sh | bash /dev/stdin <additional install-script args>
See https://docs.microsoft.com/en-us/dotnet/core/tools/dotnet-in...
There are other examples I've seen from time to time.
If I'm not mistaken insider knowledge wasn't necessary.
Remember how much was temporarily broken in the leftPad event? Imagine if all that had been silently back-doored instead?
I guess it's a case of the ease of use proving too great, so convenient in fact that we just kind of swept the implications under the rug.
I can't. It's incredibly wasteful time and resource-wise, and ties your development process to third-party providers (and your ISP), which fall over often enough in practice.
It's a good practice to have a local cache of all the third-party dependencies you use, available to both developers and CI infrastructure.
We have that, it's called Java and .NET, but apparently solved problems aren't interesting anymore.
For a distributed company with developers from all over the globe the "local" here doesn't really make much sense. But from my experience with NPM, you download packages on your developer machine once you set up a project, and then only when something really messes up node_modules, which happens once in three months, on average.
You do re-download packages for every build in CI pipeline as you build a docker image from scratch though, and that's when NPM mirror is usually set up.
Pulling packages from the internet is fine and that's how all Linux distros work but the more important thing is signature verification, imo
At my last gig (Java), developers reviewed all third-party libraries + dependencies and manually uploaded them to a private Ivy server. I don't think that could work in the Node ecosystem, where every module seems to have 100+ dependencies.
EDIT:
There's a real security vs accessibility trade-off here. You can't be a productive web developer, according to modern standards, and review every single transitive dependency that gets pulled into your application. And it's very inefficient to have individual developers at different orgs separately reviewing the same libraries over and over again.
One would naturally turn to repository administrators to enforce stricter security standards. Maybe RubyGems could review all source code for every new version of a package and build it themselves instead of accepting uploads of pre-built artifacts. But these repositories are run by smallish groups of volunteers, and they don't have the resources to conduct those kinds of reviews. And no open-source developer wants to have to go through an App Store-like review process to upload their silly McWidget library.
I try not to think about it too much and have faith in the powers that be
The web really is held together by duct tape and bubble gum.
Right, that's why we see this kind of attack all the time on Maven Central, but never on npm... oh, wait?! NO! The kind of simple attacks you see routinely on npm (typo squatting, ownership transfers to malicious authors, now this) just doesn't happen on Maven Central at all.
You have a username/password to Maven Central and you also have a private key to it.
But in order to be granted a groupID (think of it as an account), you need to prove at the time of account creation that you own the domain that matches the groupID (think account name).
So if you try to register com.foo on Maven Central, at that time you need to own foo.com, otherwise you'll be rejected.
If you do own it at that time, well your account is approved and now you have a username/password to it and a private key you need to use to sign artifacts when you publish them.
If your domain expires and is later bought by someone else, that doesn't make them the new owner of your Maven Central groupID.
I find it hard to believe any high profile organization would allow their domains to expire, or else they would also lose e-mail and websites, right?
How long did it take npm to have scoped packages. Sure, let me create a "paypal" project, they only need one js project no?
If Java suffers from excessive bureaucracy, the newer package developers/repos suffer from too much eagerness to ship something without thinking
Not to mention dependency and version craziness. If you want your software to be repeatable you need to be specific with the versions and code you're taking.
The very existence of package-lock grinds my gears and that's before it starts flip flopping because someone mistook URLs for URIs. Of course that only exists because ranged dependencies are a terrible idea, and that's before anybody even mentions things like namespaces or classifiers.
No maven wasn't perfection, and it could be (and has been) improved on - but npm doesn't even get into spitting distance.
What I want as a developer is to establish my trust relationship to developers of libraries I depend on.
`npm install <somepackage>` should first check a record of signing keys in my source code repo, then check a user-level record of signing keys I've trusted before, and then - and only then - add a tentative trust relationship if this is brand new.
`npm release` or whatever (npm is just an example - every system could benefit from this) - would then actually give me the list of new trust relationships needed, so I can go and do some validation that these are the packages I think they are.
The key thing with Go is that all dependencies have a checksum (go.sum file) and that should be committed to the repo.
So even if the domain gets hijacked and a malicious package is served up, then the checksum will fail and it will refuse to build.
People should be using internal module proxies anyway for Go. You can just store the module files in a directory, a git repo or a web service and serve up an internal cache.
Packages are typically considered immutable once published. If I have a particular package e.g. "FooLib.Bar v 1.2.3" then this zip file should _always_ contain the same bits. If I need to change those bits, e.g. to fix a bug then I need to ship e.g. "FooLib.Bar v 1.2.4"
Also packages aren't always small. So it makes sense to cache a copy locally. On dev machine "package cache" and in an org's "internal feed" and only check upstream if it's not there.
So I shouldn't need to go to the source url to get it. Ideally, I just ask "who has "FooLib.Bar v 1.2.3" for me?"
It also means that tampering can be detected with a hash.
But the "check upstream" model is now vulnerable to fake new versions.
At Google, we have those resources and go to extraordinary lengths to manage the open source packages we use—including keeping a private repo of all open source packages we use internally
I wonder how they built this culture and if it is even realistic for smaller companies to aim for it.
I think it typically comes down to a few key leaders having the political capital/will to enforce policies like this. Google's `third_party` policies[0] were created relatively early on and were, as far as I understand, supported by high level technical leaders.
The ROI of policies like these is not always immediately evident, so you need the faith of key leaders in order to make room for them. Those leaders don't necessarily need to be high in the org chart — they just need to be respected by folks high in the org chart.
As a counterfactual, establishing Google's strong testing culture seems to have been a mostly bottoms-up affair. Good article on the history of that at Mike Bland's blog[1].
0. https://opensource.google/docs/thirdparty/ 1. https://mike-bland.com/2011/09/27/testing-grouplet.html
Fortunately there was a hard legal requirement to vet every dependency license, otherwise I am not sure I would have been able to keep this workflow. As other posts say you do need a very strong commitment at the management level for this to work, besides security (where it feels that often it matters only until it costs money or until it’s even slightly inconvenient) it might be helpful to make a legal case (what if we ship something with a nested dependency on AGPL ) to get some help to establish these procedures.
I have been writing and architecting security related software for pretty much all my career and I find it quite scary how these days so much software delegates so much control to unvetted external dependencies.
We would pay to access their ”distribution”, a limited set of packages vetted by them. Distribution vendor would screen changes from upstream and incorporate into their versions.
Of course this is more limited world. It’s like using a paid Linux distribution with certain amount of software covered by the vendors support policies.
It's also useful for your organization to rebuild all of the source code from scratch (for reproducible packages anyway) and compare the new ones to the old ones, looking for things like compiler or hardware injection attacks. Secure build systems are definitely non-trivial.
https://cloud.google.com/security/binary-authorization-for-b...
""That said, we consider the root cause of this issue to be a design flaw (rather than a bug) in package managers that can be addressed only through reconfiguration," a Microsoft spokesperson said in the email."
No, npm has scopes for a reason, why would that not fix this issue?
Maybe the bug wasn't explained correctly but if it prefers public over private that seems like a bug.
OTOH, it certainly is an issue that if you forget and happen to test some code without being configured to have the private package server as your default then you'd get public repos.
Maybe instead of named packages companies should be using private URLs for packages. That way you always get what you ask for?
Artifactory apparently didn't, and served up whichever was the highest version of public vs. private. Which is stupid.
But the bottom line is that when using npm, the exact package selection policy is determined by whatever registry implementation you're talking to, and so it's the registry implementation which should prioritize private packages by default.
But that's just NPM, it's an issue in all of the mentioned package managers.
I've noticed more dev teams succumbing to the temptation of easiness that many modern package managers provide (NPM, Cargo, Ivy, etc.) - especially as someone who has to work with offline systems on a regular basis.
Because of that ease there are fewer tools and tutorials out there to support offline package management. There are more for using caches, though these are often along the lines of either 'the package manager will do this for you and it just works (but in case it doesn't, delete node_modules or cargo clean and re-try)', or stand up a dependency server on your own machine with these proxy settings (which has it's own security issues and is frequently disallowed by IT cybersecurity policies).
As an example, many blog articles I found a while back suggest using yumdownloader from the yum-utils package. This is unfortunately not reliable, as there are some packages that get skipped.
I have found I need to script reading a list of dependencies from a file; then for each dependency: create a directory for it, use repotrack to download its RPM and it's transitive dependency RPMs in the dependency's directory; then the script aggregates all the RPMs into one directory, removes the OS installed RPMs, uses createrepo to turn that directory into a RPM repository, and then makes an USF ISO image out of the directory for transfer onto offline system and installation.
The fact that pip/npm/gem etc. look for packages in a fallback location if not found in the private repository is a terrible design flaw. One which not all package managers have.
For example, when you add a cargo dependency from a private registry, you have to specify the registry that the dependency comes from, so cargo will never go looking in some other place for that crate. I'm sure many other package managers also have designs that are not vulnerable in this way.
Similarly, many package managers do not support pinning of transitive dependencies (with hashes), or pinning does not happen by default, so that many people are still using floating dependencies.
Proof: https://www.theregister.com/2016/03/23/npm_left_pad_chaos/
Sudden unplanned loss of availability is a catastrophic security problem, the A in the security CIA[1]. Worse is that the dependency that caused that problem was something that should never have been a dependency in the first place.
Proper dependency management requires a degree of trust and integrity validation which are completely counter to automation. Most developers are eager to accept any resulting consequences because they don't own the consequences and because they are fearful of writing original code.
[1] https://en.wikipedia.org/wiki/Information_security#Key_conce...
Look at what happened when the "left-pad" function disappeared from npm a few years ago. IIRC, it broke react. The downside of package managers like this is that many people have no idea what they are using.
Anyone who uses this must have already understood and just overlooked this vulnerability when they realize their private package must have a unique name that doesn't match a public package
In which case, would you not get the same issue, if you do the same attack, but with a transitive dependency which you haven't specified?
> a unique design flaw of the open-source ecosystems
This is a big generalization.
Inside Amazon, as well as in various Linux distributions, you cannot do network traffic at build time and you can only use dependencies from OS packages.
Each library has its own package and the code and licensing is reviewed. The only open source distribution that I know to have similar strict requirements is Debian.
[I'm referring to the internal build system, not Amazon Linux]
[Disclaimer: things might have changed after I left the company]
I know, because I wrote an as yet unpublished paper on safely pulling packages from private and public repos.
Using terms correctly is especially important in security: someone who read your comment might incorrectly believe that this did not affect them because they are using the correct names for all of their dependencies.
Installing packages only from a trusted (and signed) source protects against typosquatting, misread or confusing package names and many other risks.
Pre and post install scripts in NPM packages are such a terrible idea. Even when it’s not malware, it usually just a nagging donation request with a deliberate “sleep 5” to slow down your build and keep the text displayed.
pkg managers that do have that: cargo (build.rs), pip (setup.py), npm (install scripts), apt/rpm/pacman (postinstall hooks)
Maybe the only exceptions are Go and Java package managers?
The reason is simple because without it you can't properly bind to system libraries.
And even without, the supply chain attack still works against at least developers as packages are not just build but also run, often without any additional sandbox. (E.g. you run tests in the library you build which pulled in a corrupted package).
The main problem here are not build scripts (they still are a problem, just not the main) but that some of the build tools like npm haven't been build with security but convenience as priority and security was just an afterthought. For example npm did (still does?, idk) not validate if the packag freezing file and the project dependencies match so you could try to sneak in bad dependency sources.
Also for things which are classical system package managers (i.e. not build tools) like apt/rpm/pacman it build scripts really does not matter at all. The reason is that what you produce will be placed and run in your system without sand-boxing anyway, so it's a bit different then a build tool which is often used to build binaries (installers, etc.) at one place and then distribute them to many other places.
Edit: Another attack vector is to bring in a corrupted package which then "accesses" the code and data of another package, this could use speculative pointer accesses or similar but in languages like Java,Python, JavaScript you often can use reflections or overriding standard functions to archive this much more reliable.
Such 'nagging donation requests' were banned by npm pretty much days after they first appeared, IIRC, and npm itself is literally a tool for installing code to execute later, so there's no security issue here. If someone wanted to embed malware into a package, they wouldn't need postinstall scripts for it.
This is really a complete nothingburger.
What does "banned by npm" mean? Here's an example from the source of the latest version of nodemailer (with 1.4M weekly downloads) sleeping for 4,100 ms on every install so that it can show a "Sponsor us to remove this lag" message: https://github.com/nodemailer/nodemailer/blob/a455716a22d22f...
> and npm itself is literally a tool for installing code to execute later, so there's no security issue here. If someone wanted to embed malware into a package, they wouldn't need postinstall scripts for it.
It's fine to have a standard mechanism for postinstall steps. It should be opt-in by the end user rather than opt-out. That way people know that they're running additional code and ideally selectively pick which packages are allowed to do so. The vast majority of packages do not need it anyway as they do not have C++ bindings or need to generate data.
The defaults for NPM are such that you have to know quite a bit of how NPM works to download a package and inspect the contents without executing random code.
> This is really a complete nothingburger.
It's defensive in depth. With the default being to execute remote code, a single typo could be installing a package that immediately runs malware.
And yes, you want to sandbox the install too anyway, but it at least needs permissions enough to do its job, i.e. interact with the network somehow. (Although I’m working on a tool to make that fully deterministic so it can never exfiltrate anything.)
There’s also the possibility that there’s no “execute” step at all, like installing a dependency tree just to inspect source, or in theory being able to skip auditing unused code paths.
Discovered after seeing a comment on HN about a bill of materials for software, i.e., a list of "approved hashes" to ensure one can audit exactly what software is being installed, which in turn led me to this issue.
Even then, that only gives you a stronger indication that the image hasn't been altered since it was signed by the image author at any point after it being signed. However it is not a guarantee that the source produced the binary content. It's also not a guarantee that the image author knew what they were signing - though this is a different issue.
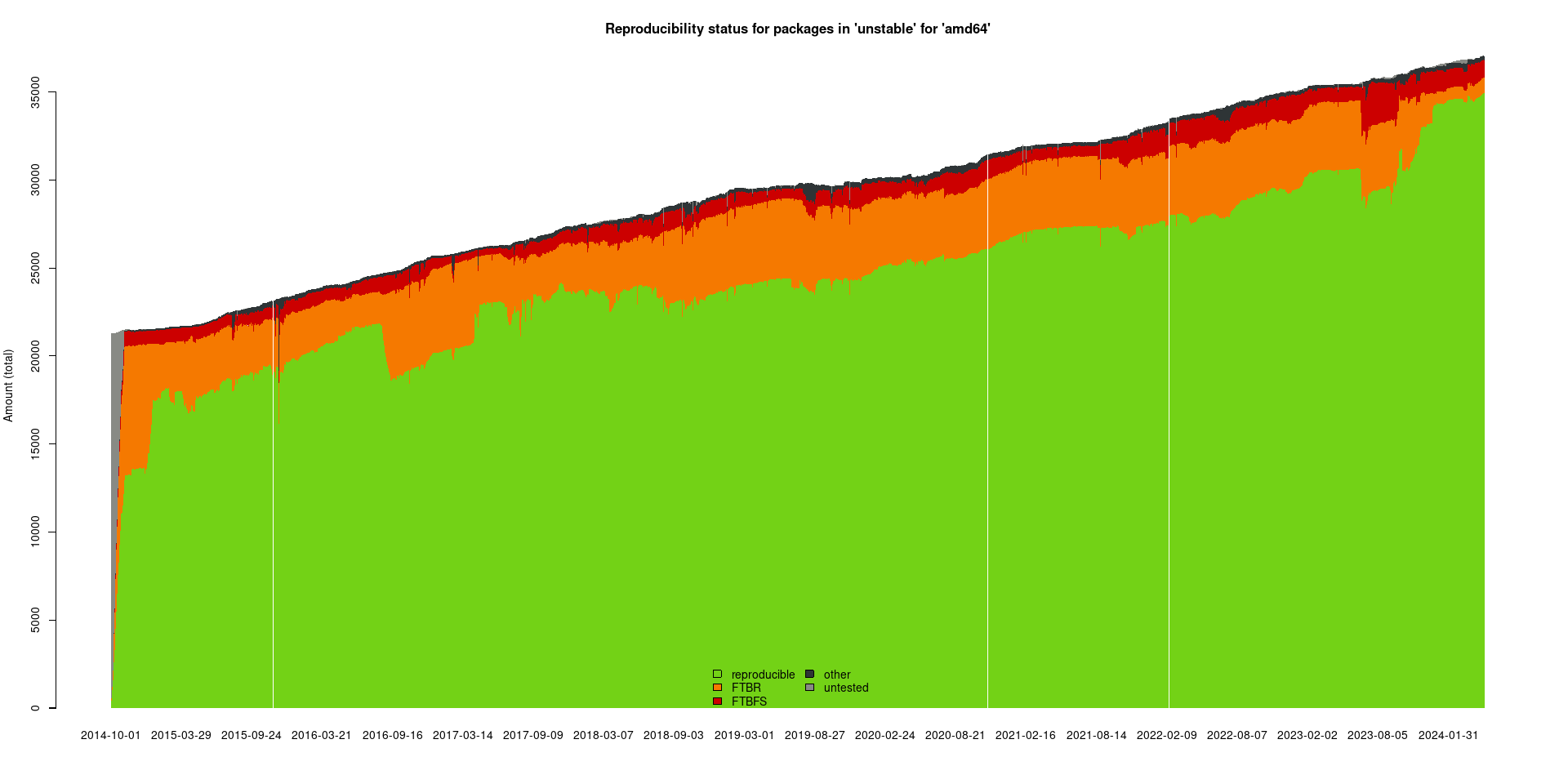
Debian has a reproducible builds initiative[1] so people can compile packages themselves and them match byte for byte what Debian built. Not sure how far they've got with that.
https://tests.reproducible-builds.org/debian/unstable/amd64/...
[1] - https://docs.docker.com/engine/security/trust/#client-enforc...
That is, given a Gemfile.lock like, e.g.
GIT
remote: https://github.com/thoughtbot/appraisal
revision: 5675d17a95cfe904cc4b19dfd3f1f4c6d54d3502
specs:
appraisal (2.1.0)
bundler
rake
thor (>= 0.14.0)
The Gemfile section is more explicable. While newer Gemfiles look like this:
source "http://our.own.gem.repo.com/the/path/to/it" do
gem 'gemfromourrepo'
end
# or
gem 'gemfromourrepo', source: "http://our.own.gem.repo.com/the/path/to/it"
source 'https://rubygems.org'
source 'http://our.own.gem.repo.com/the/path/to/it'
gem 'gemfromrubygems1'
gem 'gemfromrubygems2'
gem 'gemfromourrepo'
So is the understanding that Shopify's CI systems were running `bundle upgrade` or another non-lockfile operation? (possibly as a greenkeeper-like cron job?) Or is `--pure-lockfile` itself more subtly vulerable?
(I also don't think it's true that the attacker has a "small window of time"—as soon as they get a single RCE, it's over, if they're running on a normal dev machine then they can daemonize into the background, add persistence, and snoop events over time. CI systems are obviously less vulnerable to this by nature.)
However, this section is concerning:
> The presence of a source block in a Gemfile also makes that source available as a possible global source for any other gems which do not specify explicit sources. Thus, when defining source blocks, it is recommended that you also ensure all other gems in the Gemfile are using explicit sources, either via source blocks or :source directives on individual gems.
Yikes! This is yet another easy footgun for people to reintroduce this issue
I think the issue tends to be more that there's just so many packages (often nested 10+ deep) and it's best practice to keep them as up to date as possible.
When it's fairly typical for a JS project to have thousands of dependencies, there isn't really any practical way to both stay up to date and carefully review everything you pull in.
I think the only viable solution for companies taking this issue really seriously is to keep their numbers of dependencies down and avoid having significant deep/indirect dependencies.
Edit: as an example, in my company's Node stack (for 10 services) - there's >900 dependencies. In our React stack (for 2 sites), more than 1600.
Contrary to what you might think, these are actually pretty small, lightweight systems. So really whatever you might have thought was the worst-case scenario on numbers of deps, the reality is more like 10x that in the modern JS ecosystem.
In many ways, the vast number of tiny dependencies are one of the strongest points of the JS ecosystem. But it doesn't come without caveats.
So this probably wouldn't show up on the final build distributed and deployed somewhere. But it did manage to run arbitrary code on developers' machines of those companies.
Is this kind of attack possible using Nuget-Package manager?
When I first used maven, I was appalled by how hard it was to prevent it from accessing maven central. And horrified to see karaf trying to resolve jars from maven central at run time. What a horrible set of defaults. This behaviour should be opt-in, disabled by default, not opt-out through hard to discover and harder to verify configuration settings.
Also, Maven uses pinned versions, normally, and won't just download whatever newer minor version happens to be published when it builds, which again makes this attack quite hard to pull off.
Fixed versions for as many things as you can (including OS images, apt packages, Docker images, etc) lead to changes in your CI under your control.
Sure, you have to upgrade manually or by a script. But isn't plain build stability worth it? Not even talking about security.
So you wouldn't get a random version even considered.
Version shadowing and overriding is a totally different concern of course.
[1] https://github.com/pan-net-security/artifactory-pypi-scanner
You have always been able to specify the `index-url` when installing packages using pip. This can also be added to `requirements.txt` files as well.
However this is still very, very dangerous, because of day-to-day engineering, really. Any engineer doing a simple `npm install` can inadvertently bring in and execute malicious code from their machine. From there on out it would be somewhat trivial to gain further access to the same network the code war run from.
https://pip.pypa.io/en/stable/reference/pip_hash/
https://pip.pypa.io/en/stable/reference/pip_install/#hash-ch...
has if the nix peeps are reading the code nix is wget'ing
This is not as amendable to CI, but that's the point.
I get that you could in principle namespace things (at least for package managers that support this) and insist on a small set of company-internal signing keys for those namespaces. But managing all that isn't easy and what about for package ecosystems that don't really have namespaces (e.g. PyPI, NuGet)?
https://naildrivin5.com/blog/2019/07/10/the-frightening-stat...
https://techbeacon.com/security/check-your-dependencies-gith...
https://thenewstack.io/npm-password-resets-show-developers-n...
Not that I didn't expect someone to immediately take the opportunity to complain about npm, of course, despite it having nothing to do with the problem at hand... as has become tradition in tech circles.
Your code is what it depends on.
How was that design chosen, not just once but in all 3 of those large package ecosystems. Did pypi/gems/node borrow their design from each other given their similarity in other aspects?
Are there any situations where this behavior is desired?
Does any of the other ecosystems have flaws like this (nuget, cargo..)?
https://docs.google.com/document/d/1EW6uSZB0_D0qZuDSGuxujuVE...
I'm sure the hooks are needed for things NPM can't do by itself, but they shouldn't run by default. That puts pressure on developers to avoid them, and puts pressure on NPM to add whatever functionality is missing from package.json in a safe way.
(and have npmjs.com search rank packages without scripts above those that do)
A software supply chain attack is characterized by the injection of malicious code into a software package in order to compromise dependent systems further down the chain.
Backstabber’s Knife Collection: A Review of Open Source Software Supply Chain Attacks
https://link.springer.com/chapter/10.1007%2F978-3-030-52683-...
To be clear, just calling this a "supply chain attack" and omitting "software" is going to cause confusion with traditional supply chains.
The analogy is not quite apt: in a software build system you have complete visibility into the dependency tree, so this attack is less useful, whereas with hardware suppliers you are relying on the security of your vendor.
Not necessarily — plenty software still ships with the third party supply chain bits incorporated as binaries, including commercial software. User is relying on security of one or more in a chain of upstream vendors.
See Cyberpunk 2077 DLLs for instance.
https://twitter.com/CDPRED_Support/status/135660404767189811...
Cyberpunk “builds” their game with a software build system, but not all of it is them building it.
Then, build tools should be configurable such that they only pull in dependencies signed by PGP keys drawn from a whitelist.
Finally, companies need to maintain private repositories of vetted dependencies and avoid pulling from public repositories by default — and this requirement needs to be configurable from the project's build spec and captured in version control.
Adding dependencies on PGP just makes everything worse.
X.509 PKI for code signing is also terrible and very very complicated and error prone.
Also consider the community nature of development. You need to handle all sorts of painful crypto issues now.
I'll be rethinking using Artifactory in my infrastructure.
To update existing non-maintained public packages, mostly because they were on. Net framework and a lot moved to .net core.
In visual studio you can set the priority of where packages have to be checked. My own package repo has a higher priority.
I never thought about using it as an attack vector though.
I could easily find myself in trouble, because:
- There’s no autocomplete or bookmarks, so typos are easy.
- If “mybank” is a name provided by my company’s name server, I could find myself redirected to the public “mybank” entry because Mr. Not-A-Hacker says his name entry is more up to date (or because I forgot to tell ‘goto’ to check the company name server.)
- There’s no “green padlock” to check while I’m actively using the destination site. (Though at this point it’s too late because a few moments after I hit enter the destination site had the same access to my machine & network that I do from my current terminal.)
- A trusted site may later become malicious, which is bad due to the level of unrestricted and unmonitored access to my PC the site can have.
- Using scripting tricks, regular sandboxed browser websites can manipulate my clipboard so I paste something into ‘goto’ that I didn’t realize would be in my clipboard, making me navigate to some malicious site and giving it full access to my machine (if ‘sudo’ as added to the front).
This is just a few cases off the top of my head. If ‘goto’ was a real thing, we’d laugh it into being replaced by something more trustable.
How have current package managers not had these vulnerabilities fixed yet? I don’t understand.
Nix makes it possible to query the entire build time and runtime dependency graph of a package, and because network access during build time is disabled, such a substitution attack would be harder to pull off.
The declarations for how the source is downloaded is specified declaratively and can be pinned to a specific commit of a specific Git repository, for instance.
sigh... am I the only one that likes environments where you can run simple commands to install stuff and you can generally trust your package managers? All the security folks love to act dumbfounded when people trust things, but post-trust environments have terrible UX in my experience. I hate 2FA, for example, because now I have to tote my phone around at all times in order to be able to access any of my accounts. If I lose my phone or my phone is stolen while travelling, I'm hosed until I can figure out how to get back in.
> So can this blind trust be exploited by malicious actors?
Yes, it can. Trust can always be exploited by malicious actors, and no amount of software can change that. And it creates a world that sucks over time. Show me a post-trust, highly secure environment that isn't a major PITA to use. And not just for computers. I'm sure you could use social engineering to abuse trust of customer service reps (or just people in general) and do bad things, and the end result will be a world where people are afraid do any favors for other people because of the risk of getting burned by a "malicious actor".
And I know it's not perfect, but in Python if you use Poetry means you get a poetry.lock file with package hashes built in, so that's something.
It seems to me that down through the years ease of deployment trumps security. npm, mongodb, redis, k8s.
Or maybe sysadmin has just become outdated? Maybe front of house still needs a grumpy caretaker rather than your friendly devops with a foot in both camps.
We can now even outsource our security to some impersonal third-party so they can 'not' monitor our logs.
EOG # end of grump
It's a bit of cognitive dissonance having to explain why downloading random shit from the internet during the build is a bad idea, yet here we are.
It's not possible for an attacker to publish on that name in the public npm
This doesn't mean I'm not vulnerable to dependency attacks, but it at least limits the window, because I update these dependencies very, very rarely.
For example in the case of Facebook, it used to be that users would accept permissions without considering them, and in-turn, various apps would access their data in bad faith.
Likewise for mobile apps.
Eventually Facebook removed many of the overtly powerful permissions entirely, likewise with the mobile operating systems.
In the case of mobile, the concept of "runtime permissions" was also introduced that required explicit approval to be granted at the time of authorization.
On Android, location access now prompts the user in the notification area informing the user of an app that accessed their location.
Can some of these ideas be borrowed to the package/dependency management world? "The package you are about to install requires access to your hard drive including the following folders: x/y/z/all?
The way Nix handles this is that every external resource is cached and hashed, and every reference to an external resource must have a hash integrity check. If someone swaps out a package on a web server somewhere, rebuilds keep working because they don't need to re-fetch (because the hash wasn't changed by an operator), and fresh builds fail with an error indicating the hash is invalid, which should trigger an investigation (in practice, this is exceedingly rare, and IMO always deserves attention).
I dream for when build reproducibility is considered table stakes like version control.
"Dependency Confusion: RCE via internal package name squatting " https://news.ycombinator.com/item?id=26081149
"Dependency Confusion: How I Hacked Into Apple, Microsoft and Dozens of Other Companies, The Story of a Novel Supply Chain Attack, Alex Birsan" https://medium.com/@alex.birsan/dependency-confusion-4a5d60f...
And, of course, on production build machines, all packages are local.
This isn't just for "security" -- it's to ensure we can always build the same bits we shipped, and to avoid any surprises when something has a legitimate update that breaks something else.
The pypi maintainer is being ridiculous, it is much better to have this guy poke MSFT than have the Russians do it, he's doing them a favour.
I dunno, feels like fair game to me
To paraphrase family guy: you’re making this harder than it needs to be.
Dev 2: try “sudo npm -g package_name”.
{kind=link}