The suggestion elsewhere in this thread to decrease the number of iterations during normal testing and crank it up during nightlies is also good.
The only thing I’m still missing from the libraries is a convenient mechanism of remembering previously failing generated inputs and use them as a static list of testcases next to the at runtime generated ones like a regression test of sorts.
Edit: typos
As far as I know the Haskell Quickcheck library by John Hughes was in fact the first library to lay out property-based testing. He then went on to create a paid and expanded version of the library in Erlang. And then as Quickcheck rose in popularity it's been re-implemented in many many different languages.
disclaimer: Auxon co-founder
Also, big (h/t) to Quickcheck from me as well. Getting into it via Erlang many, many years ago was among the more impactful and transformative developments in my approach to thinking about improving software quality.
[1]: https://news.ycombinator.com/item?id=26018386
[2]: https://github.com/HypothesisWorks/hypothesis/issues/2701
edit: newlines
That's a really nice idea. It doesn't fit into the usual compositional design of the proptest libraries that I've used, but it certainly seems like it should be possible in principle.
If your tests are coupled, you're already in a bad way whether you know it or not. Dumping property testing on top of that without addressing the underlying cause sounds like a recipe for misery.
It's probably a great stick and carrot if you're pushing a tech debt reduction agenda though.
In my job Cucumber seems to add little more than just commenting and sequencing functions, tasks that are better suited to your programming language of choice, while adding overhead and complexity.
What am I missing?
I believe that Cucumber is at its best in situations where it's clear to all parties that a specification is valuable. In that case, making the specification executable is very clearly a massively useful way to spend your time.
They’re saying that sometimes it’s better to just see the error in full and try and figure it out.
What takes the time in my case was simply getting a failure to occur at all. It might take days on a mature compiler before a failure occurs, if then. This would be millions of attempts.
If I were to add just one thing to the list: metatest. Write a test that asserts that your generated test cases are "sufficiently comprehensive", for whatever value of "sufficiently" you need. In an impure language, this is as easy as having the generator contain a mutable counter for "number of test cases meeting X condition" for whatever conditions you're interested in. For example, say your property is "A iff B". You might want to fail the test if fewer than 10% of the generated cases actually had A or B hold. (And then, of course, make sure your generators are such that - say - A and B hold 50% of the time; you want an astronomically small chance of random metatest failure.)
(I did a brief intro to this in the Metatesting section of a talk I did two years ago: https://github.com/Smaug123/talks/blob/master/DogeConf2019/D... . On rereading it now, I see there's a typo on the "bounded even integers" slide, where the final `someInts` should read `evenIntegers`.)
I'd just check that when you're writing or changing the tests though; for nontrivial conditions it can take a very long time to get neglibible probability of any metatest failing in a given run, and flaky metatests are just as bad as the usual kind.
If this split is particularly important, we'd usually recommend just writing separate tests for data that satisfy A or B; you can even supply the generators with pytest.mark.parametrize if copy-pasting the test body offends.
I think there's a strong argument with FsCheck to write all your proptest code in F# just to take advantage of the vastly better generator syntax, but that's a hard sell for a team who mostly don't know F# and aren't convinced proptests are much better anyway. Writing the generators in C# seemed really incredibly tedious. I did start to get the hang of identifying properties to test though. Once you're past the mechanics of "how does this work" that can become much easier.
A load road to travel here, but I kind of gave myself a remit to improve software quality and I do think we need to be looking at this kind of testing to help.
Where do people who are using it find that it offers the most value? I keep feeling that we could really solidify some of our bespoke parsing and serialisation code using this kind of tech.
I'd very much welcome contributions on documentation, and esp. on approaches of how to keep the C#/F# documentation consistent and still accessible for both types of users. Even if it's just ideas/comments - how would you like the documentation presented? What are examples of excellent C# documentation? We need to balance that with available resources - we don't have a team of ghostwriters to write docs and examples for every language, as you can imagine. I know it's a cliche by this time, but if every user would take a couple minutes to write a paragraph or example where e.g. the C# docs are lacking, it might be in a much better state. From our side, if something is stopping you from contributing in this way, we'd like to hear about it. Addressing that is important.
Separately, I'm surprised you experienced that generators are significantly more tedious to write in C# vs F# - could you open an issue with a few examples of this? This would inform v3.0 where we will stop trying to use tricks to make the F# API accessible, but instead add a bespoke C#/VB.NET API in the FsCheck.Fluent namespace, and separating F#'y bits in FsCheck.FSharp.
Property Based Testing is Monte Carlo simulation for model checking.
1: https://hypofuzz.com/docs/literature.html 2: https://google.github.io/oss-fuzz/getting-started/new-projec...
There are also plugins for IDEs (Pycharm, VS Code and vim), which can be quite helpful during the development.
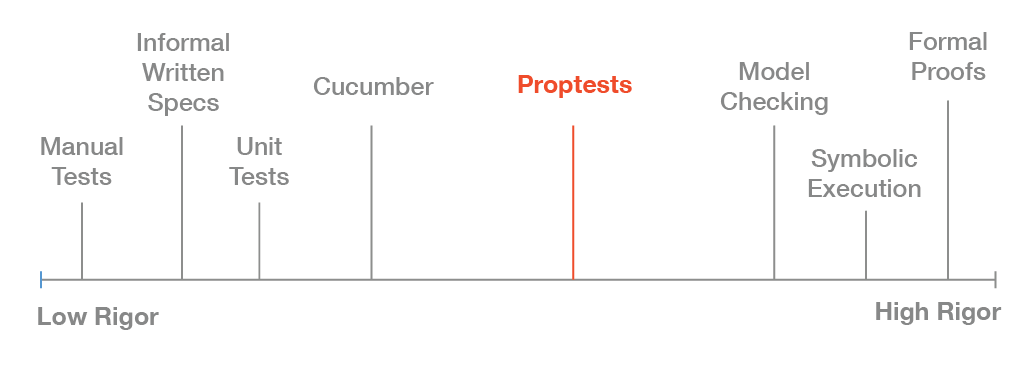
link to the graphic for ease of reference:
https://blog.auxon.io/images/posts/effective-property-based-...
[1]: https://fsharpforfunandprofit.com/posts/property-based-testi...
{kind=link}