It's unclear though from the Readme how this tool works with distributed compute. I assume much of that would be abstracted away, and I'm not sure how you'd make it flexible enough to deal with all the various possible setups.
One other aside: I assume that the Keras team has basically decided that Tensorflow is the only first class citizen in their ecosystem?
If you have a distributed model you have to make sure all of your workers on a single variant get the same HPs. Again, vizier. (Hi, I'm job 25 worker 3, what are my HPs?)
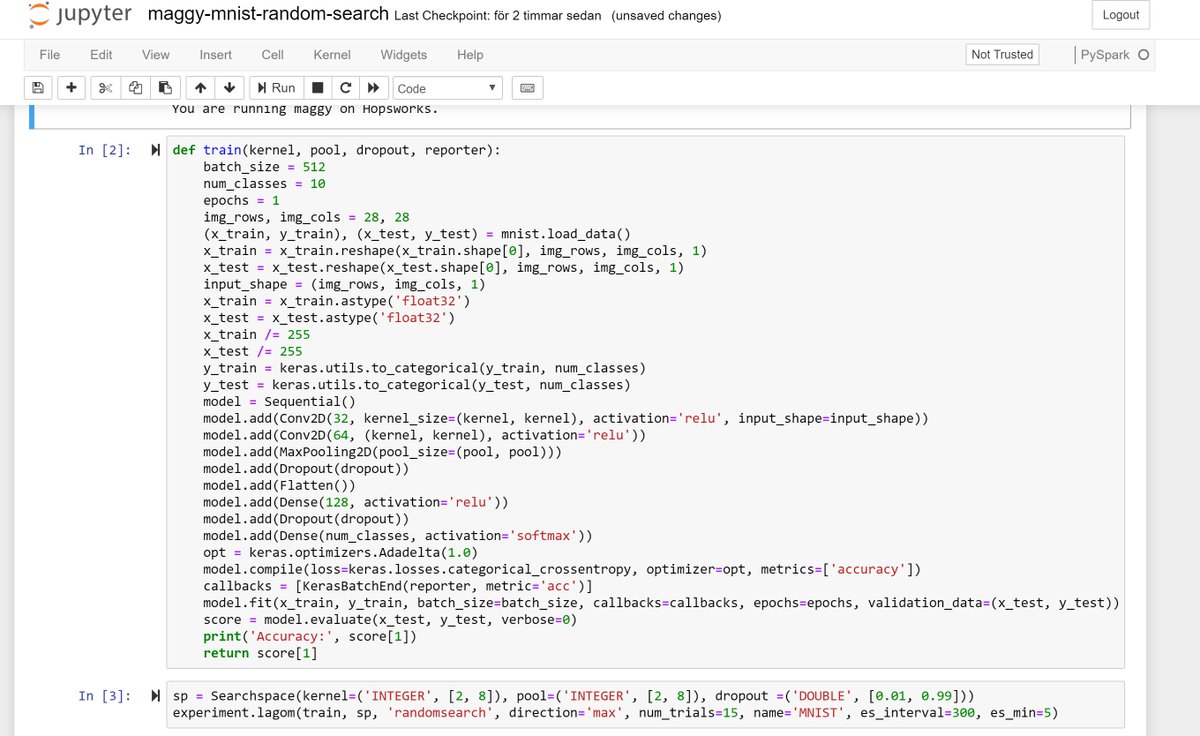
We did something similar to this, but it is data-parallel and is Python (built on top of PySpark) and supports a resource mgr with GPUs so that you can allocate GPUs to Spark executors. The main challenge we had was actually printing out logs live in the Jupyter notebook, while keeping the code Pythonic. Data Scientists do not like to leave their notebook to read logs - even if they know their are 10s of hundreds of parallel executors generating them.
Also... In that linked tweet I read the word "pythonic", but that screenshot looks like a big, monolithic plate of spaghetti to me.
Currently ray.tune is by far the best available hyperparam tuning package period, and when it comes to scaleout. I bet we'll some integrations with keras soon
{kind=link}