As he wrote, CPUs are most efficient (compute per Watt) at a specific frequency, and if his CPU mostly waits for RAM, this can be done at low power.
It's probably possible to create x86-64 CPUs with narrower backends (fewer execution units) with microcode-emulated 128 and 256 bit registers/operations (and maybe even emulated FPU) and get a cheaper and faster build server, if it was economical to fab such narrow-use-case chips (those would be good for redis/memcached too I imagine).
He actually did `make -j32`, not 16. Which is going to absolutely devastate the cache.
`make -j<number of cores x 2>` was a good rule of thumb back when you had 1/2/4 physical CPUs with their own sockets on a motherboard and spinning rust hard disks. A lot of "compilation" time was reading the source code off the disk. But it doesn't make any sense anymore with so many cores, hyperthreading, and SSDs that serve you the file in milliseconds.
If he's bandwidth limited, he would gain a significant performance improvement by reducing the number of processes.
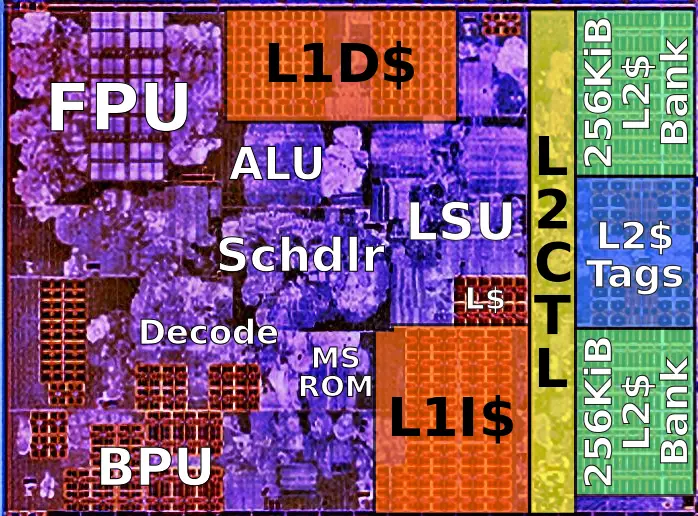
It's certainly possible to build a more lightweight core, but most of that work is reducing the complexity of the out-of-order machinery. The FPU+ALU is under a quarter of each Zen core. https://en.wikichip.org/w/images/c/cb/amd_zen_core_%28annota...
Don't get mixed up between "microcoding" and "micro-op" - the latter is something different, slower and which usually requires some kind of transition in the decoders and uop caches to start reading microcoded ops. The latter is the "normal" or "fast" mode for the CPU and just because one instruction turns into two uops (or macro-ops or whatever AMD calls them) doens't mean microcoded.
In that picture (thanks!) I see the FPU is big, the decoder is big, the branch predictor is big, the rest is probably needed. Maybe emulated FPU is good for some workloads, maybe ability to program in microinstructions instead of x86-64 is useful too. But maybe silicon area is not the expensive thing (dark silicon, etc.).
Still, the conclusion holds: if most of the time is spent waiting for values to come back from memory, a higher core frequency has strongly diminishing returns.
That's not enough to turn gcc from a largely latency bound load to a memory bandwidth hog!
Even more cache ways won't help too much in this workload.
Adding to that, there are other effects that allow core frequency to leak into the performance of memory-bound programs, such as a higher frequency allowing the core run ahead more quickly to get more memory requests in flight, recover more quickly after a branch misprediction, etc. Try it sometime: find something which is really memory bound and crank the frequency way down: there will probably be a significant effect, but not nearly in proportion to the frequency difference.
That be much more CPU-bound. Yes - some optimization will do global traversals.
I wonder if javac/clang has the same characteristics as gcc.
> Of course, in the server space, we've known for a long time that maximum efficiency occurs with a high number of cores running at lower frequencies, and that efficiency trumps performance on machines with high core counts. But I never considered that the consumer Ryzen CPUs could also benefit from the same thing until now.
makes no sense. This principal applies to all CPUs from the smallest SoCs to the largest server CPUs, why on Earth would you not expect it to apply to desktop CPUs?
You could do the same thing with a 6 core i7 and 2133 memory. Intel CPUs have long supported an adjustable power limit to constrain operating frequency based on power consumption just like he describes for Ryzen.
This is like putting an LS engine in an otherwise stock Miata and acting surprised that you can run the engine at lower RPM and still put in good lap times.
For servers, the purchasing decisions are probably much more quantitative, and if you are buying a high core count machine it probably means you have a parallelizable workload, so no efficiency comes into play since you have a lot of choice on the frequency/core-count spectrum, versus power, money, space, etc.
Why not? I like it when my electricity bill is less severe. For my wallet and the environment alike.
I didn't know that compilation was memory speed limited.
Are there any good benchmarks on it?
Anyone have any examples of getting faster memory boosting build speed?
Over the last few years I'd settled into thinking that high speed ram barely did anything. I guess I was wrong!
https://www.phoronix.com/scan.php?page=article&item=ryzen-dd...
https://www.techpowerup.com/231585/amd-ryzen-infinity-fabric...
Which mean the CPU is already shipped with the reasonable performance/watt TDP and over-TDP it will give diminish return in performance gain.
However, It would be interesting to see benchmark in much lower TDP than 105Watt and see how far the TDP can go down before big drop in performance.
It looks something like this: 4GHz 120W, 3.8 90W, 3.6 65W, 3.4 50W, 32 42W, 3.0 33W, 2.0 13W. This excludes the SOC.
3.6 @65W is impressive, almost stock speed at nearly half tdp.
{kind=link}