I'm not familiar with Git internals. Does the performance of the hashing algorithm contribute significantly to how Git deals with large files or with operations over a large number of small files?
I've run into performance problems with things like MathJaX, which includes thousands (or tens of thousands?) of files as a backup method for rendering equations. (I understand each file has a single character in some typeface.)
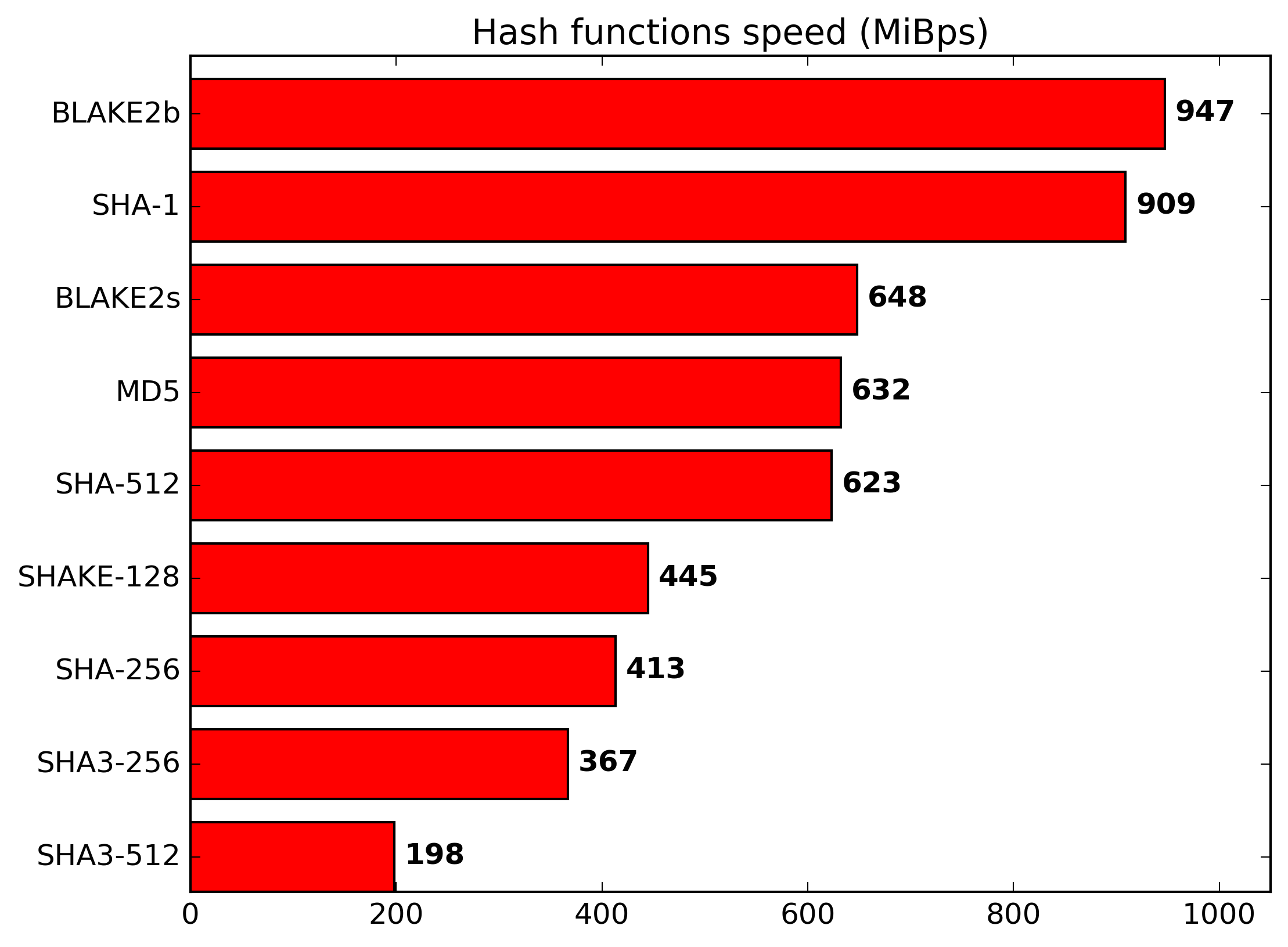
The hash function may not matter for overall git performance in virtually all dev machine setups, but there will be a (maybe tiny, maybe larger, depending on the repo and disk io speed) difference in cpu utilization and heat generation, right?
sha3 will probably get hw accel eventually. Blake2 is less likely to. It's like the dilemma between chacha20 and a stream cipher mode for aes. An argument could be made for either, depending on application specifics and available hardware.
{kind=link}