And how do they calibrate low/middle/high.
Yes, recurrent nets exist, and have since the 80s, before even convolutional nets. The authors seem a bit out of the loop, considering the (more recent) success of RNNs in speech recognition... Arguably this article itself describes a type of RNN.
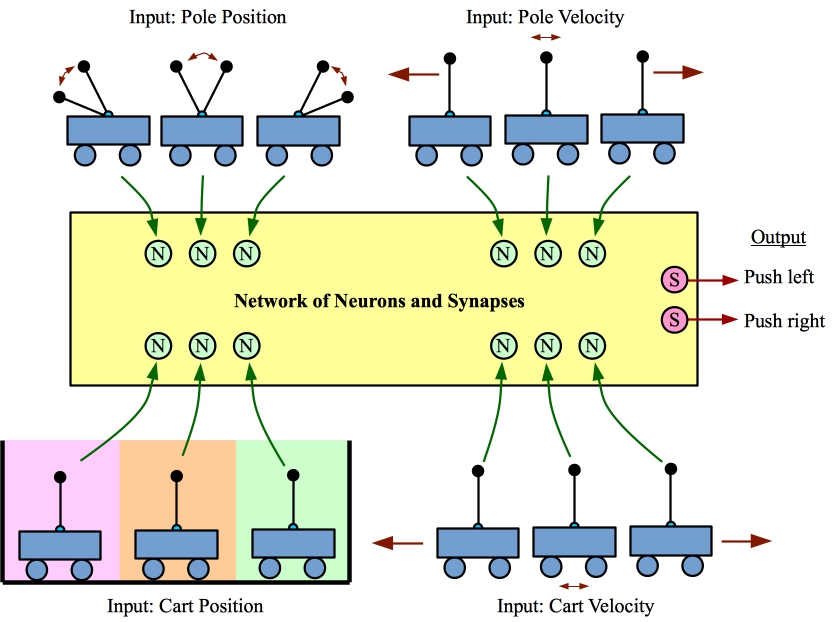
We attempt to illustrate that in this image: http://neuromorphic.eecs.utk.edu/images/graphics/Inv-Example...
Basically, the inputs and outputs are fixed, random neurons and connections are added, the networks are all tested, the better ones are changed and/or combined, and then repeat until a "good" network is found, where good in this case means balancing the pole for a long time without running into the walls.
Currently, fixed architecture ANNs can solve the cartpole problem very quickly already with Q-learning or policy gradient methods: https://gym.openai.com/envs/CartPole-v0
It seems like some kind of neuromorphic networks are going to be necessary for the long term AI 'dream', but there really needs to be something better then evolutionary algorithms for training, those just don't scale.
I am working on a project right now which will require a more complex network interacting with many real world sensors, so it should be interesting to see how EO performs for such a problem. Our EO has been demonstrated to scale on parallel machines as large as ORNL's Titan, but I readily acknowledge that much more work needs to be done with learning algorithms.
But it kind of requires the structure of the cortical columns to already be in place - which has happened through genetics/evolution in biology.
Biologically plausible backpropagation could also work, but I haven't seen anyone successfully apply it in SNN's
But you're right that the synapse right below the outputs has no input, which doesn't make any sense. The original generated network had a neuron with no inputs at (6,12) just to the left of the outputs, left over from the evolutionary algorithm like you suggested. We ran a program that was supposed to prune the network by removing the evolutionary noise that had no effect on the outputs. It looks like that program just removed any neurons with no inputs, leaving behind that meaningless path of synapses.
But here, from the claims in the post and the lab website, it sounds as if the goal is in application: Creating better, more efficient controllers. This comes across as a little detached from the applied machine learning literature. At the least, I missed a comparison to reinforcement learning (which has a history of learning to solve this exact task with simpler controller designs and most likely shorter search times) and also to non-bio-inspired recurrent networks.
One more point: Even if I follow along with the claim that 'deep learning' approaches don't have memory (implying recurrent networks aren't included in that label), I want to point out that this particular task setup, with positions/angles as well as their rates of change provided, can be solved by a memoryless controller. It would have done more to highlight the strengths of the recurrent network approach if a partially observable benchmark task had been used, e.g. feeding positions and angles only. Much more difficult high-dimensional tasks e.g. in robotic control are tackled in the (deep) reinforcement learning literature among others.
https://www.youtube.com/watch?v=fqk2Ve0C8Qs
Double inverted pendulum balancing (2015), a much harder task:
https://www.youtube.com/watch?v=8t3i2WPpIDY
Double inverted pendulum balancing with a physical cart (2011), a much much harder task:
https://www.youtube.com/watch?v=B6vr1x6KDaY
Triple!!! inverted pendulum balancing with a physical cart (2011), a much much much harder task:
Here's a system learning how to do this.[1] Takes about 200 trials.
Here's the triple inverted pendulum balancing problem, solved using feedforward control.[2]
[1] https://www.youtube.com/watch?v=Lt-KLtkDlh8 [2] https://www.youtube.com/watch?v=cyN-CRNrb3E
{kind=link}