> I'm not so sure the Linux design where copies are done in syscalls must be inherently less efficient.
Windows overlapped IO can map the user buffer directly to the network hardware, which means that in some situations there will be zero copies on outbound traffic.
> especially the RX copy I also don't think you need more than one copy, if you design the network stack with that in mind.
When the interrupt occurs, the network driver is notified that the DMA hardware has written bytes into memory. On Windows, it can map those pages directly onto the virtual addresses where the user is expecting it. This is zero copies, and just involves updating the page tables.
This works because on Windows, the user space said when data comes in, fill this buffer, but on Linux the user space is still waiting on epoll/kevent/poll/select() -- it has only told the kernel what files it is interested in activity on, and hasn't yet told the kernel where to deposit the next chunk of data. That means the network driver has to copy that data onto some other place, or the DMA hardware will rewrite it on the next interrupt!
If you want to see what this looks like, I note that FreeBSD went to a lot of trouble to implement this trick using the UNIX file API[0]
> On Linux, I think for sockets, there are only: blocking, select, poll, epoll. And the latter three are just different ways to do the same thing.
Linux also supports SIGIO[1], and there are a number of aio[2] implementations for Linux.
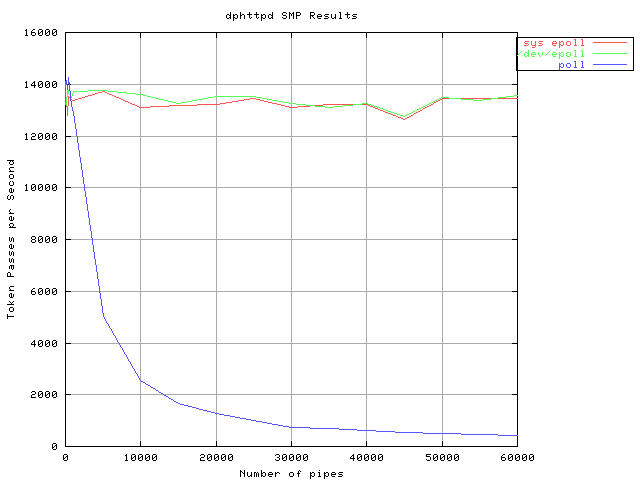
epoll is not the same as poll: Copying data in and out of the kernel costs a lot, as can be seen by any comparison of the two, e.g. [3]
Also worth noting: Felix observes[4] SIGIO is as fast as epoll.
> I don't see how one could do it more efficiently
Dereferencing the pointer causes the CPU to stall right after the kernel has transferred control back into user space, while the memory hardware fetches the data at the pointer. This is a silly waste of time and of precious resources, considering the process is going to need the file descriptor and it's user data in order to schedule the IO operation on the file descriptor.
In fact, on Linux I get more than a full percent improvement out of putting the file descriptor there, instead of the pointer, and using a static array of objects aligned for cache sharing.
For more on this subject, you should see "what every programmer should know about memory"[4].
[0]: http://people.freebsd.org/~ken/zero_copy/
[1]: http://davmac.org/davpage/linux/async-io.html#sigio
[2]: http://lse.sourceforge.net/io/aio.html
[3]: http://lse.sourceforge.net/epoll/dph-smp.png
[4]: http://bulk.fefe.de/scalability/
[5]: https://www.akkadia.org/drepper/cpumemory.pdf
{kind=link}